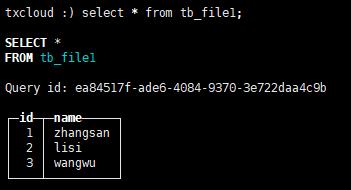
表引擎:
一、日志引擎
创建表 引擎使用Log
create table tb_user( id UInt8, name String, sal Float64, address String, birthday Date ) engine=Log;
插入数据
insert into tb_user values(1,'zhangsan',20000,'shanghai','1986-09-08'); insert into tb_user values(2,'lisi',30000,'beijig','1987-09-08'), (3,'wangwu',40000,'beijig','1985-09-08');
每个字段以单独的文件存储
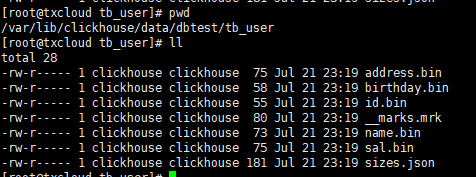
sizes.json 记录每个 .bin 文件的大小。
__marks.mrk 记录数据的位置,保存块偏移量
*.bin 是按列保存数据的文件
创建表 使用TinyLog引擎
create table tb_user2( id UInt8, name String, sal Float64, address String, birthday Date ) engine=TinyLog; insert into tb_user2 values(1,'zhangsan',20000,'shanghai','1986-09-08'); insert into tb_user2 values(2,'lisi',30000,'beijig','1987-09-08'), (3,'wangwu',40000,'beijig','1985-09-08'); insert into tb_user2 values(4,'黄山',50000,'中国','1986-09-08');
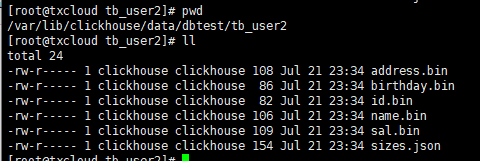
查看文件结构,可以发现,少了__marks.mrk 文件
创建表,使用StripeLog引擎
create table tb_user3( id UInt8, name String, sal Float64, address String, birthday Date ) engine=StripeLog; insert into tb_user3 values(1,'zhangsan',20000,'shanghai','1986-09-08'); insert into tb_user3 values(2,'lisi',30000,'beijig','1987-09-08'), (3,'wangwu',40000,'beijig','1985-09-08'); insert into tb_user3 values(4,'黄山',50000,'中国','1986-09-08');
查看文件结构,将所有的数据存储在data.bin 这一个文件中。

StripeLog 引擎不支持ALTER UPDATE和ALTER DELETE.
二、MergeTree家族引擎
1、MergeTree:
MergeTree系列的表引擎是CK数据存储功能的核心,它们提供了用于弹性和高性能
数据检索的大多数功能: 列存储,自定义分区,稀疏的主索引,辅助数据跳过索引等。
MergeTree:
数据的更新
数据的排序
快速查询
建立索引
分区
自动的合并 去重 局部聚合
create table tb_mt(
id Int8,
name String,
addr String
)
engine=MergeTree()
ORDER BY id ;
排序字段为id,默认是主键
insert into tb_mt values(1,'zhangsan','hz'),(5,'lisi','shanghai');
insert into tb_mt values(2,'wangwu','BeiJing'),(3,'zhaoliu','guanzhou');
查询数据 select * from tb_mt;
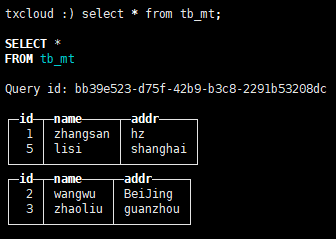
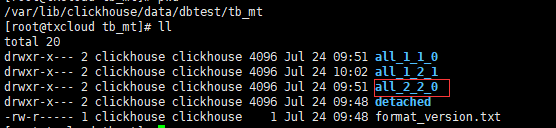
查看文件夹结构
cd /var/lib/clickhouse/data/dbtest/tb_mt
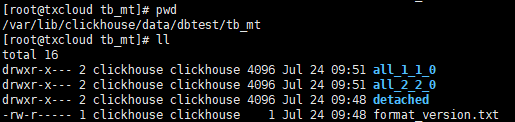
进入all_1_1_0
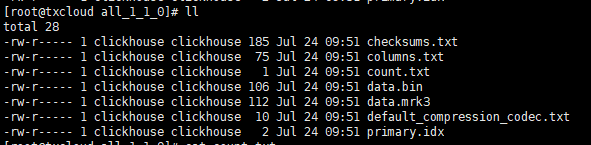
count.txt 是数据的数量,这里是2
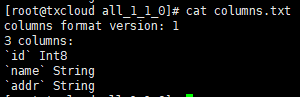
columns.txt 是数据的列
primary.idx 记录主键和索引
人为对分区数据进行合并
optimize table tb_mt;
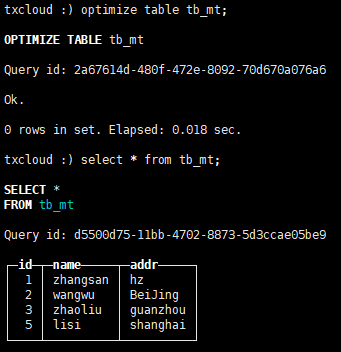
合并后数据是有序的。
查看结构,多了一个文件夹 all_2_2_0
去重功能
分别插入两条重复的数据
insert into tb_mt values(1,'zhangsan','hz');
insert into tb_mt values(1,'zhangsan','hz');
查询数据 select * from tb_mt;

可以发现,主键id是允许重复的。
合并后查询
optimize table tb_mt;
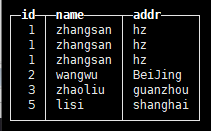
可以发现,数据没有去重。
指定分区合并
创建表,按addr进行分区
create table tb_mt2(
id Int8,
name String,
addr String
)
engine=MergeTree()
ORDER BY id
partition by addr;
插入数据
insert into tb_mt2 values(1,'zhangsan','hz'),(3,'lisi','shanghai');
insert into tb_mt2 values(2,'wangwu','hz'),(4,'zhaoliu','shanghai');
select * from tb_mt2 ;

可以发现,没有按addr进行分区。查看文件结构,有四个分区。
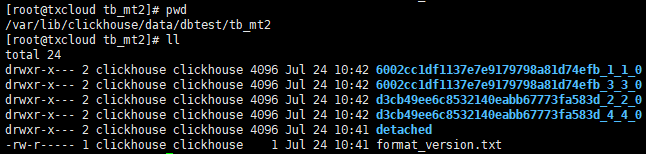
以上四个分区,一定时间阈值,会进行自动合并。
手工合并 optimize table tb_mt2; 然后进行查询select * from tb_mt2;,一次只能合并一个分区。

再合并一次optimize table tb_mt2,可以发现都合并好了。
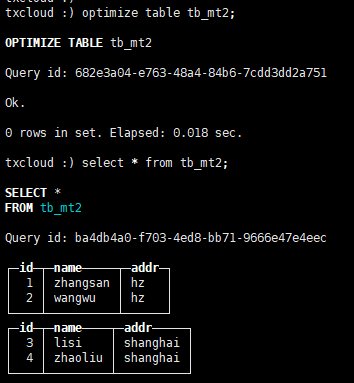
查看结构,1和3进行合并,2和4进行合并。
cd /var/lib/clickhouse/data/dbtest/tb_mt2

以后如果用分区addr进行查询,速度就会很快。
2、ReplacingMergeTree引擎 (根据数据版本删除)
这个引擎实在MergeTree的基础上,添加了“处理重复数据”的功能。该引擎和MergeTree的不同之处在于它会删除具有相同主键的重复项。数据的去重只会再合并的过程中出现。合并会在未知的时间在后台进行,所以你无法预先做出计划。有一些数据可能仍未被处理。因此,ReplacingMergeTree适用于在后台清除重复的数据以节省空间,但是它不保证没有重复的数据出现。
创建表
create table tb_rep_merge_tree( id Int8, name String, ctime Date, version UInt8 ) engine=ReplacingMergeTree(version) order by id partition by name primary key id;
插入数据
insert into tb_rep_merge_tree values(1,'a','2021-07-20',20); insert into tb_rep_merge_tree values(1,'b','2021-07-20',30); insert into tb_rep_merge_tree values(1,'a','2021-07-20',20); insert into tb_rep_merge_tree values(1,'a','2021-07-20',30); insert into tb_rep_merge_tree values(1,'b','2021-07-20',10);
查询数据: select * from tb_rep_merge_tree
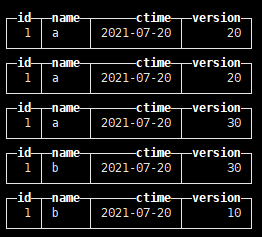
对数据进行合并 select * from tb_rep_merge_tree
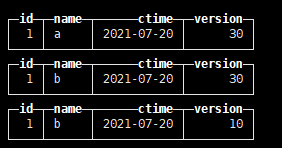
3、CollapsingMergeTree (根据sign取消标记删除以前的数据)
CollapsingMergeTree消除ReplacingMergeTree的限制(只删除小版本字段,只保留最大版本数据)。该引擎要求在建表语句中指定一个标记列Sign,后台Compaction时会将主键相同、Sign相反的行进行折叠,也即删除。
缺点: 无法保证primary key相同的行落在同一个节点上,不在同一个节点上的数据无法折叠。因此在进行count(*),sum(col)等聚合计算时,可能存在数据冗余的情况。
创建表
create table tb_clp_mt( user_id UInt64, name String, age UInt8, sign Int8 ) engine=CollapsingMergeTree(sign) order by user_id;
插入数据
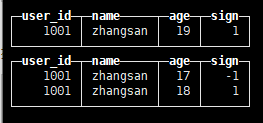
insert into tb_clp_mt values(1001,'zhangsan',19,1); insert into tb_clp_mt values(1001,'zhangsan',17,-1),(1001,'zhangsan',18,1);
查询 select * from tb_clp_mt;
合并和查询,最后留下age为18这条数据
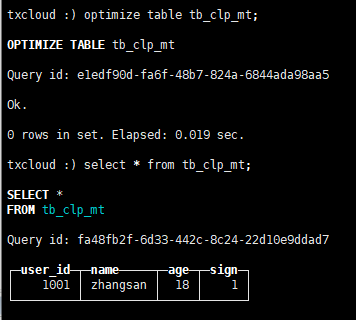
4、VersionedCollapsingMergeTree 根据取消标记删除指定版本数据
取消字段和数据版本同时使用,避免取消行数据无法删除的问题。
为了解决CollapsingMergeTree乱序写入情况下无法正常折叠问题,VersionedCollapsingMergeTree引擎在建表语句中增加了一列Version,用于在乱序情况下记录状态行与取消行的对应关系。主键相同,且Version相同、Sign相反的行,在Compaction时会被删除。
创建表并插入数据
create table tb_vs_clp_mt( user_id UInt64, name String, age UInt8, sign Int8, version UInt8 ) engine=VersionedCollapsingMergeTree(sign, version) order by user_id; insert into tb_vs_clp_mt values(1001,'zhangsan',18,-1,2); insert into tb_vs_clp_mt values(1001,'zhangsan',18,1,1),(1001,'zhangsan',19,1,2);
查询数据 select * from tb_vs_clp_mt;
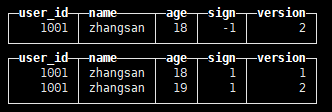
合并optimize table tb_vs_clp_mt;和查询 select * from tb_vs_clp_mt;

可以发现剩下一条age=18的数据。
4、SummingMergeTree
该引擎继承字MergeeTree。区别在于,当合并SummingMergeTree表的数据片段时,ClickHouse会把所有具有相同主键的行为合并为一行,该行包含了被合并的行中具有数值数据类型的列的汇总值。如果主键的组合方式使得单个键值对应于大量的行,则可以显著的减少存储空间并加快数据查询的速度。对于不可加的列,会取一个最先出现的值。
创建表,并插入数据
create table tb_sum_mt( id UInt64, name String, ctime Date, cost UInt64, sal Float64 ) engine=SummingMergeTree(cost) order by id partition by name; insert into tb_sum_mt values(1,'zhangsan',now(),99,10000), (1,'zhangsan',now(),88,10000); insert into tb_sum_mt values(1,'zhangsan',now(),77,10000);
查看数据 select * from tb_sum_mt;
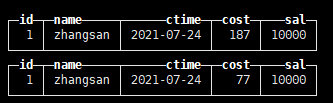
合并后查询 optimize table tb_sum_mt;

5、Memory引擎
内存引擎,数据以未压缩的原始形式直接保存在内存中,服务器重启数据会丢失。读写操作不会相互阻塞,不支持索引。简单查询下有非常高的性能表现(超过10G/s).
一般用到它的地方不多,除了用来测试,就是在需要非常高的性能,同时数据量又不太大(上限大概1亿行)的场景。
create table tb_memory( id Int8, name String, age UInt8 ) engine=Memory; insert into tb_memory values(1,'zhangsan',22), (2,'lisi',60);
服务重启,数据就会丢失。
6、缓存引擎
7、File 引擎
创建表
create table tb_file1( id Int8, name String ) engine=File(TabSeparated);
然后在指定的目录下创建文件data.TabSeparated
cd /var/lib/clickhouse/data/dbtest/tb_file1
vi data.TabSeparated
输入:
1 zhangsan 2 lisi 3 wangwu
查询 select * from tb_file1;