1.安装Eclipse EE版本
2.配置Eclipse
配置Eclipse
-
将插件hadoop-eclipse-plugin-2.6.0jar拷贝到Eclipse安装目录下的dropins目录
-
启动Eclipse,增加Map/Reduce功能区
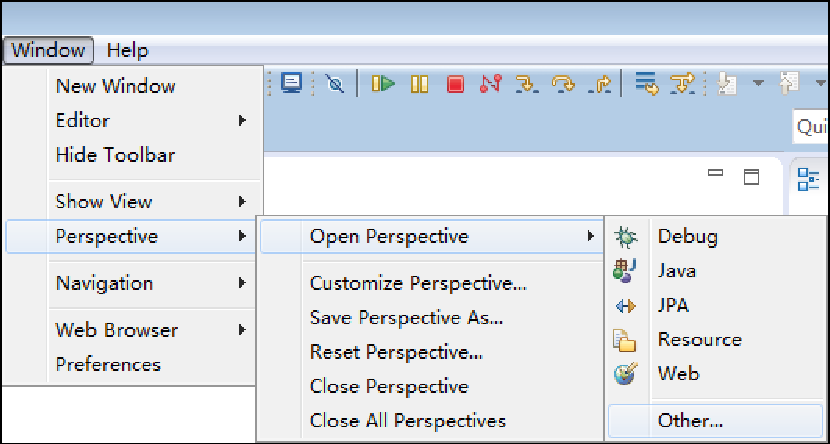
-
增加Hadoop集群的连接
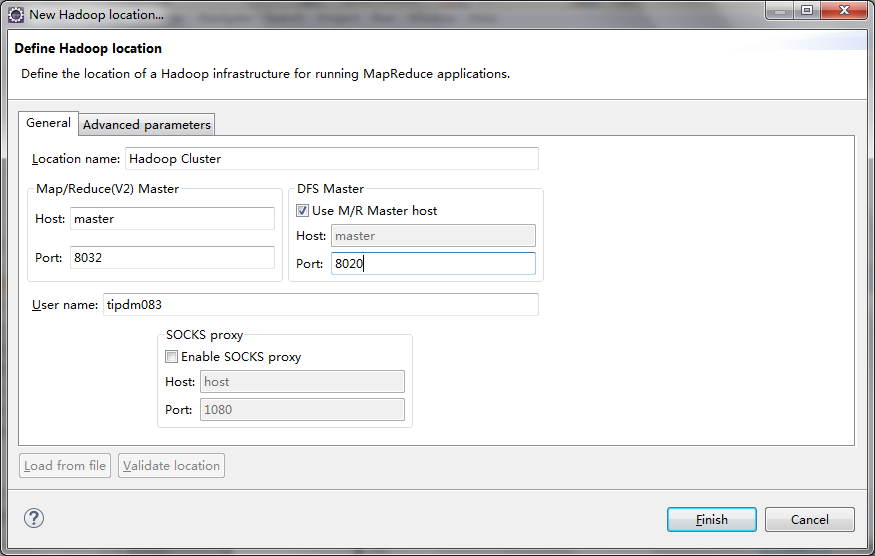
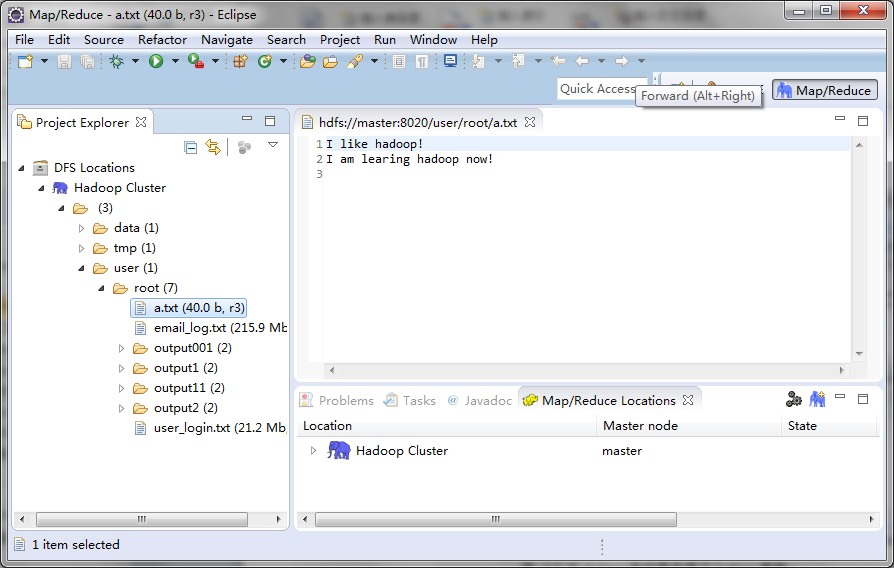
-
导入MapReduce运行依赖的相关Jar包,注意,要解压hadoop.jar,然后把解压目录选择到下面位置。

-
创建MapReduce工程,选择新建工程-->Map/Reduce Project
3.编写MapReduce程序
3 .0 mapreduce原理
MapReduce原理,如图片所示
以wordcount为例:
(1)map阶段,Map阶段将输入的行数据,解析成单词-1的key-value对

(2)reduce阶段,Reduce阶段将map阶段的输出结果进行归并,最后统计输出。
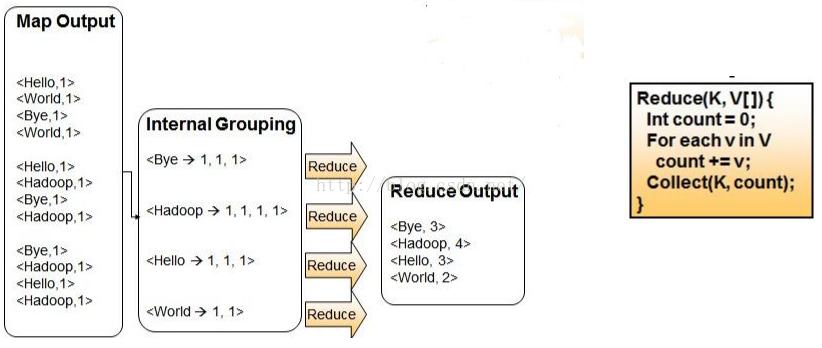
(3) 总体
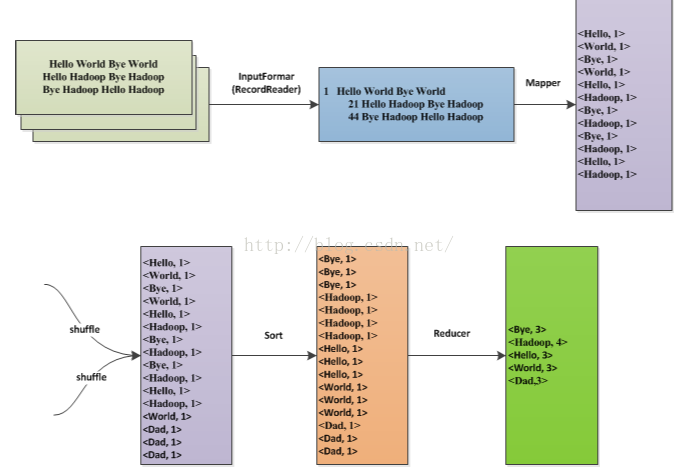
3.1编写wordcount连接程序
编写wordcount连接程序
3.2编写xxyy连接程序
编写xxyy连接程序
3.2.1 编写xxyymain程序
新建包,新建xxconnectyy.class,包含main方法。
Configuration conf=new Configuration(); //配置集群任务
Job job=Job.getInstance(conf);
job.setJarByClass(xxconnectyy.class);
job.setMapperClass(xxconnectmapper.class);
job.setReducerClass(xxconnectyyreducer.class);
job.setMapOutputKeyClass(Text.class); //配置map输出key、value类型
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class); //配置reduce输出key、value类型
job.setOutputValueClass(NullWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0])); //配置输入到hdfs数据文件xx路径
FileInputFormat.addInputPath(job, new Path(args[1])); //配置输入到hdfs数据文件yy路径
FileOutputFormat.setOutputPath(job, new Path(args[2])); //配置输出到hdfs数据文件zz路径
System.out.println(job.waitForCompletion(true)?0:1);//提交任务奥hadoop集群。
3.2.2编写xxconnectmapper.class,该方法继承Mapper类
public class xxconnectmapper extends Mapper<LongWritable, Text, Text, NullWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
context.write(value, NullWritable.get());
}
}
3.2.3编写xxconnectyyreducer,该方法继承Reducer类
public class xxconnectyyreducer extends Reducer<Text, NullWritable,Text, NullWritable>{
@Override
protected void reduce(Text date, Iterable<NullWritable> arg1,
Reducer<Text, NullWritable, Text, NullWritable>.Context context) throws IOException, InterruptedException {
// TODO Auto-generated method stub
context.write(date, NullWritable.get());
}
}
3.2.4 文件下选择Export 为xxyy.jar包
上传包到 /opt/目录下,上传XX.txt,YY.TXT到hdfs目录下
3.3 自定义mapreduce分区
3.3.1 新建包,编写自定义分区类MyPartitioner,继承Partitioner
public class MyPartitioner extends Partitioner<Text, IntWritable>{
@Override
public int getPartition(Text user_date, IntWritable one, int numReduce) {
//numReduce,表示分区数量
if(user_date.toString().contains("2016-01")) return 0;
else return 1;
}
}
3.3.2 MapReduce主类添加分区的设置代码。
job.setPartitionerClass(MyPartitioner.class)
job.setNumReduceTasks(2);
3.4 定义Combiner类。
对map记录进行规约。实现Map output记录的I/O开销,减少map out的记录。提高reduce效率。具体做法是在主类加入代码
job.setCombinerClass(LogCountReducer.class);//Combiner类继承Reducer类,所以可以用Reducer类设置规约规则。
4.hadoop集群运行MapReduce程序
hadoop jar /opt/某某.jar 包名.主类名 输入路径1,输入路径2,。。。 输出路径 ,注意输入、输出路径都是hdfs下的目录。
5.eclipse端提交集群
eclipse配置集群提交程序
实现Tool接口,通过ToolRunner来运行应用程序。以XXYY连接的mapreduce程序为例
5.1 继承Tool接口
public class xxconnectyy extends Configured implements Tool
5.2 编写getConfiguration()方法,设置相关集群信息
注意:hadoop在访问hdfs的时候会进行权限认证,取用户名的过程是这样的:读取HADOOP_USER_NAME系统环境变量,如果不为空,那么拿它作username,如果为空
读取HADOOP_USER_NAME这个java环境变量,如果为空,从com.sun.security.auth.NTUserPrincipal或者com.sun.security.auth.UnixPrincipal的实例获取username。如果以上尝试都失败,那么抛出异常LoginException("Can’t find user name")
Configuration conf = new Configuration();
//下面配置解决root访问权限被拒绝问题。
Properties properties = System.getProperties();//设置root用户访问权限
properties.setProperty("HADOOP_USER_NAME", "root");//设置系统环境变量的访问用户名
conf.set("fs.defaultFS", "hdfs://master:9000");
conf.setBoolean("mapreduce.app-submission.cross-platform",true);//指定是否允许客户端提交
conf.set("fs.defaultFS", "hdfs://master:8020");// 指定namenode
conf.set("mapreduce.framework.name","yarn"); // 指定使用yarn框架
conf.set("yarn.resourcemanager.address", "master:8032"); // 指定resourcemanager
conf.set("yarn.resourcemanager.scheduler.address", "master:8030");// 指定资源分配器
conf.set("mapreduce.jobhistory.address", "master:10020");
conf.set("mapreduce.job.jar","D:\。。。\xxyy.jar");//先到处jar包,然后复制路径这里
return conf;
5.3 重写run方法
原来提交集群的代码,写到run方法中
public int run(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf=getConf();
Job job=Job.getInstance(conf);
job.setJarByClass(xxconnectyy.class);
job.setMapperClass(xxconnectmapper.class);
job.setReducerClass(xxconnectyyreducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileInputFormat.addInputPath(job, new Path(args[1]));
FileOutputFormat.setOutputPath(job, new Path(args[2]));
return job.waitForCompletion(true)?0:1;
}
5.4 编写main方法
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
String[] myArgs = new String[] {//设置main方法传参的路径
"hdfs://master:8020/test/XX.txt",
"hdfs://master:8020/test/YY.txt",
"hdfs://master:8020/test/xxyy_eclipse01"
};
ToolRunner.run(getConfiguration(), new xxconnectyy(), myArgs);//eclipse程序提交
}
log4j.properties文件放在包里面,才能看到控制台打印集群提交信息