本教程是虚拟机搭建Spark环境和用idea编写脚本
一、前提准备
需要已经有搭建好的虚拟机环境,具体见教程大数据学习之路又之从小白到用sqoop导出数据 - 我试试这个昵称好使不 - 博客园 (cnblogs.com)
需要已经安装了idea或着eclipse(教程以idea为例)
二、环境搭建
1、下载Spark安装包(我下载的 spark-3.0.1-bin-hadoop2.7.tgz)
下载地址Scala 2.12.8 | The Scala Programming Language (scala-lang.org)
2、上传到虚拟机并解压(没备注就是主节点运行)
tar -zxvf spark-3.0.1-bin-hadoop2.7.tgz
3、修改权限
chown -R hadoop /export/server/spark-3.0.1-bin-hadoop2.7
chgrp -R hadoop /export/server/spark-3.0.1-bin-hadoop2.7
4、创建软连接
ln -s /export/server/spark-3.0.1-bin-hadoop2.7 /export/server/spark
5、启动spark交互式窗口
/export/server/spark/bin/spark-shell

还是很炫酷的哈哈哈,出现这个说明spark环境就搭建好了吗?漏!!!
6、配置Spark集群
cd /export/server/spark/conf
mv slaves.template slaves
vim slaves
添加
node02
node03
node04
7.配置master
cd /export/server/spark/conf
mv spark-env.sh.template spark-env.sh
vim spark-env.sh
增加如下内容:
## 设置JAVA安装目录
JAVA_HOME=/linmob/install/jdk1.8.0_141
## HADOOP软件配置文件目录,读取HDFS上文件和运行Spark在YARN集群时需
要,先提前配上
HADOOP_CONF_DIR=/linmob/install/hadoop-3.1.4/etc/hadoop
YARN_CONF_DIR=/linmob/install/hadoop-3.1.4/etc/hadoop
## 指定spark老大Master的IP和提交任务的通信端口
#SPARK_MASTER_HOST=node01
SPARK_MASTER_PORT=7077
SPARK_MASTER_WEBUI_PORT=8080
SPARK_WORKER_CORES=1
SPARK_WORKER_MEMORY=1g
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node01:2181,node02:2181,node03:2181,node04:2181 -Dspark.deploy.zookeeper.dir=/spark-ha"
## 配置spark历史日志存储地址
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node01:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true"
cd /export/server/
scp -r spark-3.0.1-bin-hadoop2.7 hadoop@node02:$PWD
scp -r spark-3.0.1-bin-hadoop2.7 hadoop@node03:$PWD
scp -r spark-3.0.1-bin-hadoop2.7 hadoop@node04:$PWD
9、创建软连接(每个节点都运行一遍)
ln -s /export/server/spark-3.0.1-bin-hadoop2.7 /export/server/spark
10、配置Yarn历史服务器并关闭资源检查
vim /export/server/hadoop/etc/hadoop/yarn-site.xml
少的部分补上
<configuration>
<!-- 配置yarn主节点的位置 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 设置yarn集群的内存分配方案 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>20480</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<!-- 开启日志聚合功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置聚合日志在hdfs上的保存时间 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
</property>
<!-- 关闭yarn内存检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
注意:如果之前没有配置,现在配置了需要分发并重启yarn(重启需要每个节点都运行)
cd /export/server/hadoop/etc/hadoop
scp -r yarn-site.xml hadoop@node02:$PWD
scp -r yarn-site.xml hadoop@node03:$PWD
scp -r yarn-site.xml hadoop@node04:$PWD
/export/server/hadoop/sbin/stop-yarn.sh
/export/server/hadoop/sbin/start-yarn.sh
11、配置Spark的历史服务器和Yarn的整合
cd /export/server/spark/conf
mv spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
添加
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node01:8020/sparklog/
spark.eventLog.compress true
spark.yarn.historyServer.address node01:18080
手动创建
hadoop fs -mkdir -p /sparklog
12、修改日志级别
cd /export/server/spark/conf
mv log4j.properties.template log4j.properties
vim log4j.properties
修改
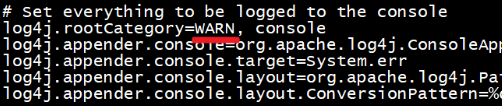
分发-可选,如果只在node1上提交spark任务到yarn,那么不需要分发
cd /export/server/spark/conf
scp -r spark-env.sh hadoop@node02:$PWD
scp -r spark-env.sh hadoop@node03:$PWD
scp -r spark-env.sh hadoop@node04:$PWD
scp -r spark-defaults.conf hadoop@node02:$PWD
scp -r spark-defaults.conf hadoop@node03:$PWD
scp -r spark-defaults.conf hadoop@node04:$PWD
scp -r log4j.properties hadoop@node02:$PWD
scp -r log4j.properties hadoop@node03:$PWD
scp -r log4j.properties hadoop@node04:$PWD
13、配置依赖的Spark的jar包
hadoop fs -mkdir -p /spark/jars/
hadoop fs -put /export/server/spark/jars/* /spark/jars/
vim /export/server/spark/conf/spark-defaults.conf
添加内容
spark.yarn.jars hdfs://node1:8020/spark/jars/*
分发同步-可选
cd /export/server/spark/conf
scp -r spark-defaults.conf hadoop@node02:$PWD
scp -r spark-defaults.conf hadoop@node03:$PWD
scp -r spark-defaults.conf hadoop@node04:$PWD
14、启动服务
- 启动HDFS和YARN服务,在主节点上启动spark集群
/export/server/spark/sbin/start-all.sh
-启动MRHistoryServer服务,在node01执行命令
mr-jobhistory-daemon.sh start historyserver
-
/export/server/spark/sbin/start-history-server.sh
15、测试
看下个博客Spark入门之idea编写Scala脚本 - 我试试这个昵称好使不 - 博客园 (cnblogs.com)
三、总结:
在主节点上启动spark集群
/export/server/spark/sbin/start-all.sh
在主节点上停止spark集群
/export/server/spark/sbin/stop-all.sh
spark: 4040 任务运行web-ui界面端口
spark: 8080 spark集群web-ui界面端口
spark: 7077 spark提交任务时的通信端口
hadoop: 50070集群web-ui界面端口
hadoop:8020/9000(老版本) 文件上传下载通信端口