布隆过滤器
可以看作是一个位数组,每个元素只占1bit,存的都是0或者1。
它通常用于查询某个元素是否存在,但是它是一种概率性查询,能够实现高效查询,但是又一定的误判。能够告诉你某个元素一定不存在或可能存在。
与此对比:HashMap也是用来判断某个元素是否存在的,把数据存为HashMap的key,然后就可以在O(1)时间复杂度内返回结果。但是HashMap存储在内存中,而且存储占比比较高。
put加入元素
当为数组初始化时,所有位置都为0。
当字符串存储到布隆过滤器中时,该字符串首先由多个哈希函数生成不同的哈希值,然后在位数组的对应的下标位置存1。
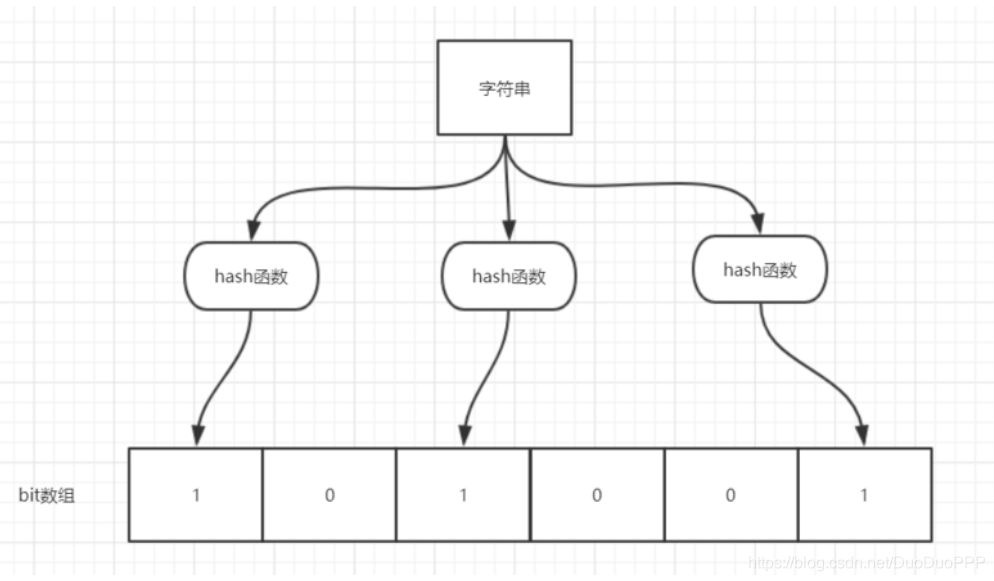
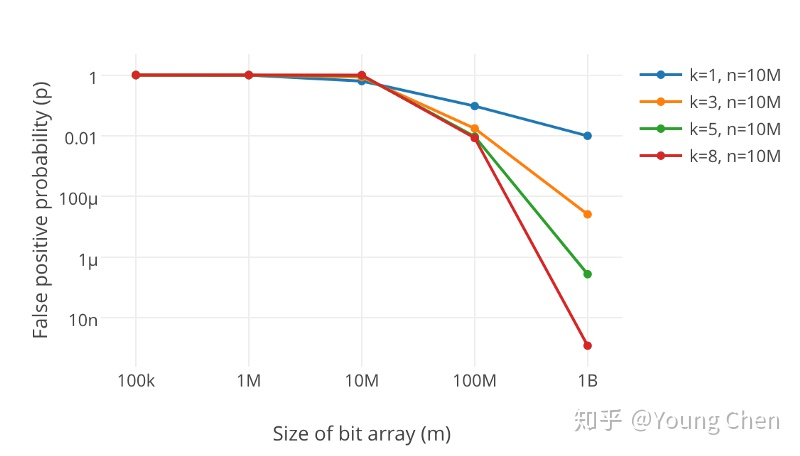
从上可得知,哈希函数的个数和布隆过滤器的长度会影响误报率。(K为哈希函数个数,m为布隆过滤器的长度,n为插入的元素的个数,p为误报率)
哈希函数
MurmurHash
Fnv
使用场景
用布隆过滤器来减少磁盘IO或者网络请求。
如果我们可以得知一个值必然不存在的话,就不用进行后续昂贵的查询请求。
1. 去重
2. Hbase
Hbase的每个Region中包含一个BloomFilter,用与加快查看速度,快速判断某个key在该Regoin中是否存在。
3. redis
减轻缓存穿透的能量
3. 判断黑名单、垃圾邮件过滤等