Unicode 是字符集 UTF-8 是编码规则 Unicode:给每一个字符分配一个唯一的ID(又称码位)。 编码规则:将码位转换为字节序列的规则。
1、什么是字符编码:字符翻译成数字,所遵循的标准就是字符编码
2、以下两个场景涉及到字符编码的问题:
1.文件在存、取时
2.文件执行时
为什么硬盘中的文件不用Unicode编码形式存储。
Unicode: 转换速度快,缺点:占用空间大
Utf-8: 节省空间,缺点:转换速度慢。
因为Unicode和utf8的优缺点所以内存使用Unicode,硬盘上的字符编码可以用户自定义
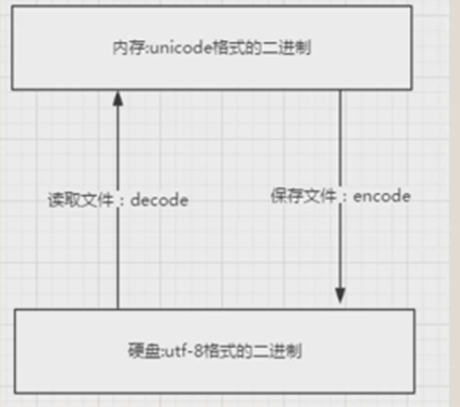
unicode----->encode----->utf-8 存储
utf-8------->decode----->unicode 读取
常见的字符编码:
ASCII: 1Bytes = 1字符 =8bit,8bit:2**8-1=256个字符,无法表示中文。 GBK(可变长): 中文2字节,英文1字节 unicode(定长): 2字节, 虽然2**16-1=65535,但可以存放100w+个字符 。又名:万国码 UTF-8(可变长):英1Bytes,中3Bytes,生僻字占用更多Bytes。最大空间可以有6字节。
如何正确使用编码:
1、保存和读取时用的编码必须一致。 2、代码需要指定执行时的编码格式 3、bytes类型:由Unicode encode的结果 4、只有Unicode类型才可以调用encode方法,可以encode成GBK,UTF-8等编码形式(都是bytes类型)
程序执行的过程:
在python3中bytes类型与unicode相互转换:Encode、Decode
阶段一:启动python解释器
阶段二:程序加载到内存
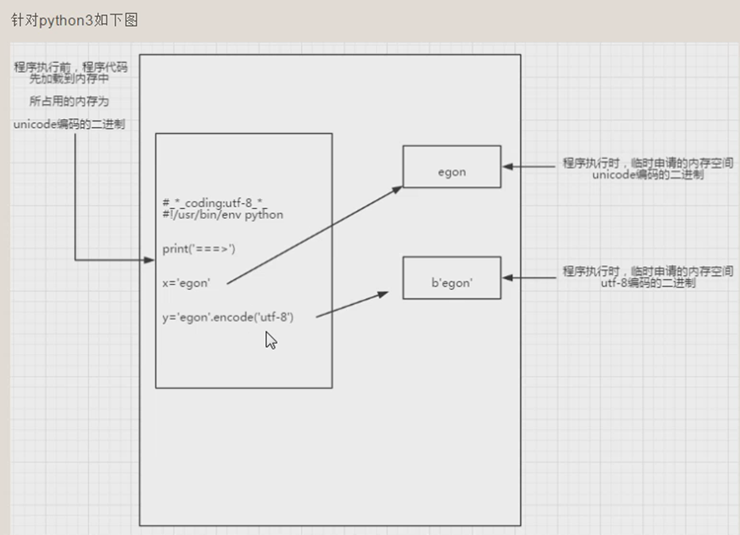
1、Python3先解码成Unicode编码格式,再加载到内存(加载到内存的代码是unicode编码格式) 2、可以用sys.getdefaultencoding()查看Python中默认的解码方式。 3、行首:coding:xxx表示已什么编码格式解码成Unicode。python2中默认使用ascii解码,python3中默认使用utf-8解码
阶段三:执行
程序执行时,局部变量会开辟新的内存空间,在python2中字符串是bytes类型,Python3 中str就是以unicode形式保存的
Python2
str类型
1、在python2中字符串是bytes类型 2、当python解释器执行到产生字符串的代码时(例如x='上'),会申请新的内存地址,然后将'上'编码成文件开头指定的编码格式 3、要想看x在内存中的真实格式,就以列表形式打印,如果直接print()会自动转换编码,这一点我们稍后再说。
Python2自动把字符串encode了一下,编码方式来自于文件头的编码。
#coding:gbk x='上' print([x,y]) #['xc9xcf', 'xcfxc2'] print(type(x),type(y)) #(<type 'str'>, <type 'str'>) #x代表16进制,此处是c9cf总共4位16进制数,一个16进制四4个比特位,
#4个16进制数则是16个比特位,即2个Bytes,这就证明了按照gbk编码中文用2Bytes
#coding:gbk x=u'上' #等同于 x='上'.decode('gbk') y=u'下' #等同于 y='下'.decode('gbk') print([x,y]) #[u'u4e0a', u'u4e0b'] print(type(x),type(y)) #(<type 'unicode'>, <type 'unicode'>)
5.3.2 python3 中
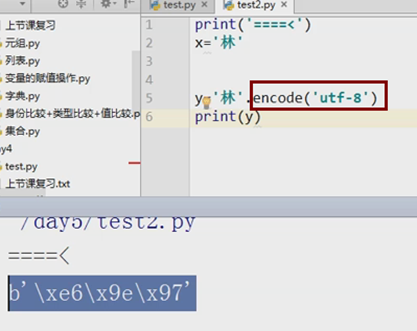
Python3 中str就是以unicode形式保存的
#coding:gbk x='上' print(type(x)) #<class 'str'> print(x.encode('gbk')) #b'xc9xcf' print(type(x.encode('gbk'))) #<class 'bytes'>
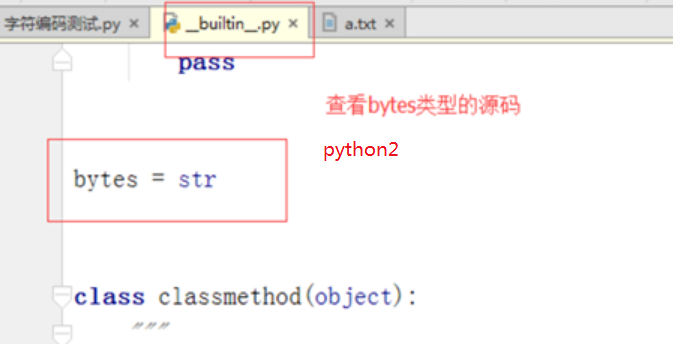
python2中的str类型就是bytes类型,Python3中的str和bytes不是一回事。