作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3161
简述Hadoop平台的起源、发展历史与应用现状。
起源:
2003-2004年,Google公布了部分GFS和MapReduce思想的细节,受此启发的Doug Cutting等人用2年的业余时间实现了DFS和MapReduce机制,使Nutch性能飙升。然后Yahoo招安Doug Gutting及其项目。
2005年,Hadoop作为Lucene的子项目Nutch的一部分正式引入Apache基金会。
2006年2月被分离出来,成为一套完整独立的软件,起名为Hadoop。
hadoop的版本有:
0.x系列版本:hadoop当中最早的一个开源版本,在此基础上演变而来的1.x以及2.x的版本;使用MapReduce来做计算处理,使用磁盘空间作为计算。
1.x版本系列:hadoop版本当中的第二代开源版本,主要修复0.x版本的一些bug等;使用yarn来做计算处理,使用磁盘空间作为计算。
2.x版本系列:架构产生重大变化,引入了yarn平台等许多新特性;Hadoop支持Spark来计算处理。Spark即支持磁盘做数据处理,也支持内存来做数据处理。Spark支持Python,JAVA,Scala语言。
现状应用:
由于Hadoop优势突出,基于Hadoop的应用已经遍地开花,尤其是在互联网领域。TANJURD报告显示:Yahoo! 通过集群运行Hadoop,以支持广告系统和Web 搜索的研究;Facebook借助集群运行Hadoop,以支持其数据分析和机器学习;百度 则使用Hadoop进行搜索日志的分析和网页数据的挖掘工作;淘宝的Hadoop系统用 于存储并处理电子商务交易的相关数据;中国移动研究院基于Hadoop的“大 云”(BigCloud)系统用于对数据进行分析和并对外提供服务。
2008年2月,Hadoop最大贡献者的Yahoo!构建了当时规模最大的Hadoop应 用,它们在2000个节点上面执行了超过1万个Hadoop虚拟机器来处理超过5PB的 网页内容,分析大约1兆个网络连接之间的网页索引资料。这些网页索引资料压缩 后超过300TB。Yahoo!正是基于这些为用户提供了高质量的搜索服务。
Hadoop目前已经取得了非常突出的成绩。随着互联网的发展,新的业务模式 还将不断涌现,Hadoop的应用也会从互联网领域向电信、电子商务、银行、生物 制药等领域拓展。相信在未来,Hadoop将会在更多的领域中扮演幕后英雄,为我 们提供更加快捷优质的服务。
下次上课之前,必须成功完成Hadoop的安装与配置。
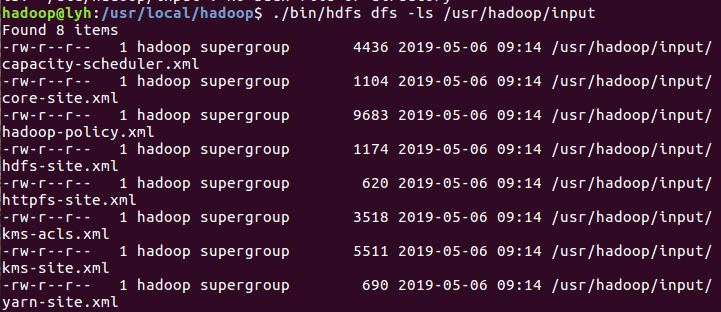
截图如下:
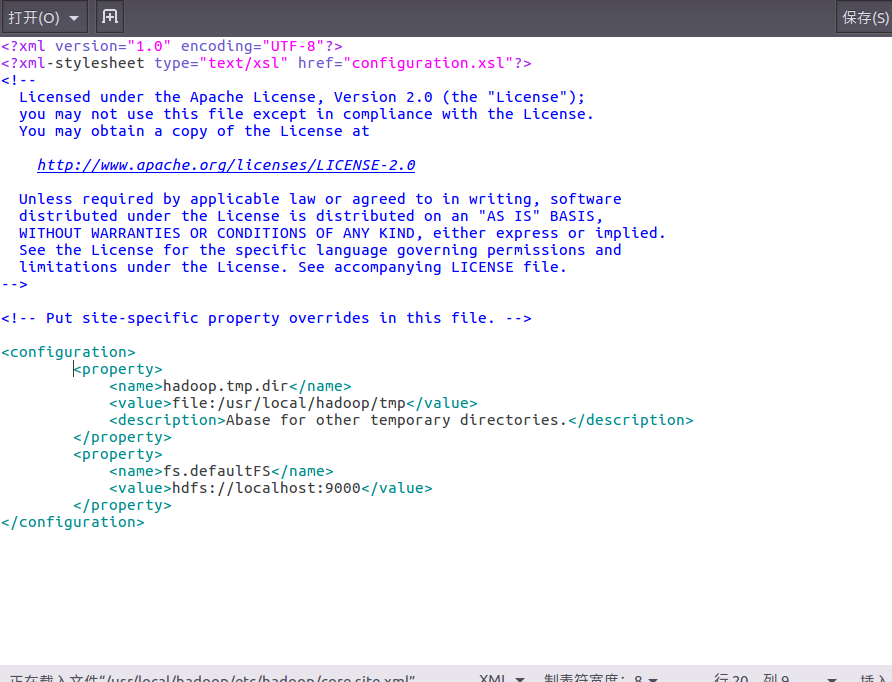
修改后的配置文件 core-site.xml:
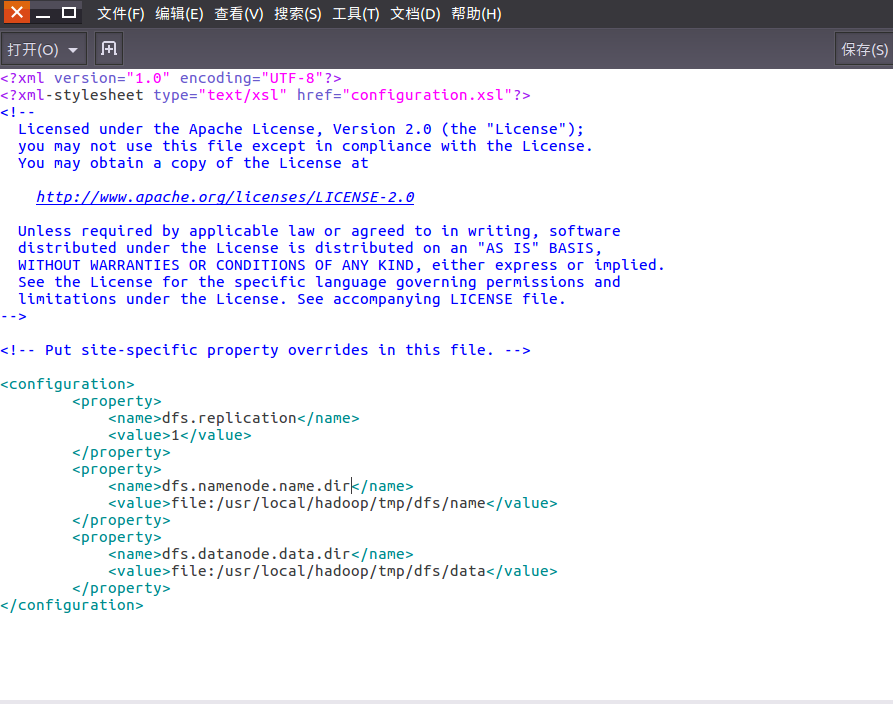
修改后的配置文件 hdfs-site.xml:
Hadoop伪分布式文件上传下载结果: