这个作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/2620。
1.字符串操作:
- 解析身份证号:生日、性别、出生地等。
代码如下:
1 # -*- coding: utf-8 -*- 2 """ 3 Spyder Editor 4 5 This is a temporary script file. 6 """ 7 ID = input('请输入十八位身份证号码: ') 8 if len(ID) == 18: 9 print("你的身份证号码是 " + ID) 10 else: 11 print("错误的身份证号码") 12 13 ID_add = ID[0:6] 14 ID_birth = ID[6:14] 15 ID_sex = ID[14:17] 16 ID_check = ID[17] 17 18 # ID_add是身份证中的区域代码,如果有一个行政区划代码字典,就可以用获取大致地址# 19 20 year = ID_birth[0:4] 21 moon = ID_birth[4:6] 22 day = ID_birth[6:8] 23 print("生日: " + year + '年' + moon + '月' + day + '日') 24 25 if int(ID_sex) % 2 == 0: 26 print('性别:女') 27 else: 28 print('性别:男') 29 30 # 此部分应为错误判断,如果错误就不应有上面的输出,如何实现?# 31 W = [7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2] 32 ID_num = [18, 17, 16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2] 33 ID_CHECK = ['1', '0', 'X', '9', '8', '7', '6', '5', '4', '3', '2'] 34 ID_aXw = 0 35 for i in range(len(W)): 36 ID_aXw = ID_aXw + int(ID[i]) * W[i]
运行结果如下图:
- 凯撒密码编码与解码
凯撒加密法,或称恺撒加密、恺撒变换、变换加密,是一种最简单且最广为人知的加密技术。它是一种替换加密的技术,明文中的所有字母都在字母表上向后(或向前)按照一个固定数目进行偏移后被替换成密文。
代码如下:
1 def change(c,i): 2 c = c.lower() 3 num = ord(c) 4 if num >= 97 and num <= 122: 5 num = 97 + ((num - 97) + i) % 26 6 return chr(num) 7 8 9 def kaisa_jiami(string,i): 10 string_new = '' 11 for s in string: 12 string_new += change(s,i) 13 print(string_new) 14 return string_new 15 16 def kaisa_jiemi(string): 17 for i in range(25): 18 print('\n', i, '\n') 19 i += 1 20 kaisa_jiami(string,i) 21 22 23 def main(): 24 print('请选择需要的操作:') 25 print('1:凯撒加密') 26 print('2:凯撒解密') 27 choice = input() 28 if choice == '1': 29 string = input('请输入需要加密的字符串:') 30 num = int(input('请输入需要偏移的位数:')) 31 kaisa_jiami(string,num) 32 elif choice == '2': 33 string = input('请输入需要解密的字符串:') 34 kaisa_jiemi(string) 35 else: 36 print('输入错误,请重试!') 37 main() 38 39 if __name__ == '__main__': 40 main()
运行结果如下图:

- 网址观察与批量生成
代码如下:
1 import urllib.request 2 3 url="https://blog.csdn.net/qq_33160790" 4 req=urllib.request.Request(url) 5 resp=urllib.request.urlopen(req) 6 data=resp.read().decode('utf-8') 7 8 print(data)
运行结果如下图:

2.英文词频统计预处理
- 下载一首英文的歌词或文章或小说,保存为utf8文件。
- 从文件读出字符串。
- 将所有大写转换为小写
- 将所有其他做分隔符(,.?!)替换为空格
- 分隔出一个一个的单词
- 并统计单词出现的次数。
代码如下:
1 article =''' 2 Big data analytics and business analytics 3 by Duan, Lian; Xiong, Ye 4 Over the past few decades, with the development of automatic identification, data capture and storage technologies, 5 people generate data much faster and collect data much bigger than ever before in business, science, engineering, education and other areas. 6 Big data has emerged as an important area of study for both practitioners and researchers. 7 It has huge impacts on data-related problems. 8 In this paper, we identify the key issues related to big data analytics and then investigate its applications specifically related to business problems. 9 ''' 10 11 split = article.split() 12 print(split) 13 14 #使用空格替换标点符号 15 article = article.replace(",","").replace(".","").replace(":","").replace(";","").replace("?","") 16 17 18 #大写字母转换成小写字母 19 exchange = article.lower(); 20 print(exchange) 21 22 #生成单词列表 23 list = exchange.split() 24 print(list) 25 26 #生成词频统计 27 dic = {} 28 for i in list: 29 count = list.count(i) 30 dic[i] = count 31 print(dic) 32 33 #排除特定单词 34 word = {'and','the','with','in','by','its','for','of','an','to'} 35 for i in word: 36 del(dic[i]) 37 print(dic) 38 39 #排序 40 dic1= sorted(dic.items(),key=lambda d:d[1],reverse= True) 41 print(dic1) 42 43 #输出词频最大的前十位单词 44 for i in range(10): 45 print(dic1[i])
运行结果如下图:

3.文件操作
- 同一目录下相对路径。
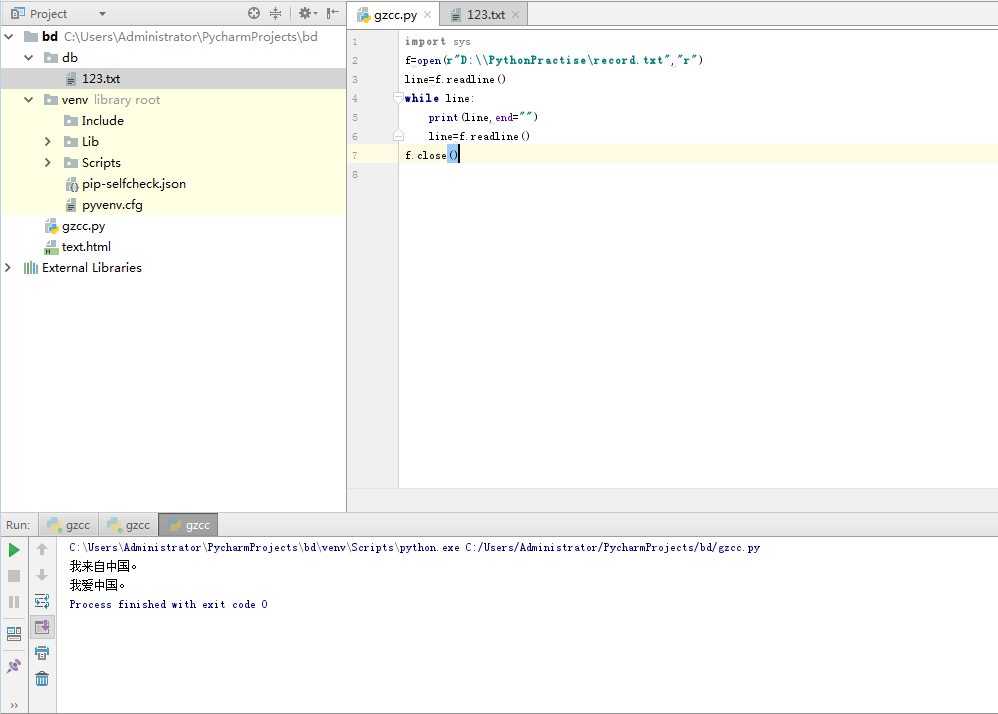
首先在同一目录下创建 123.txt 文件,代码和运行结果如下图:
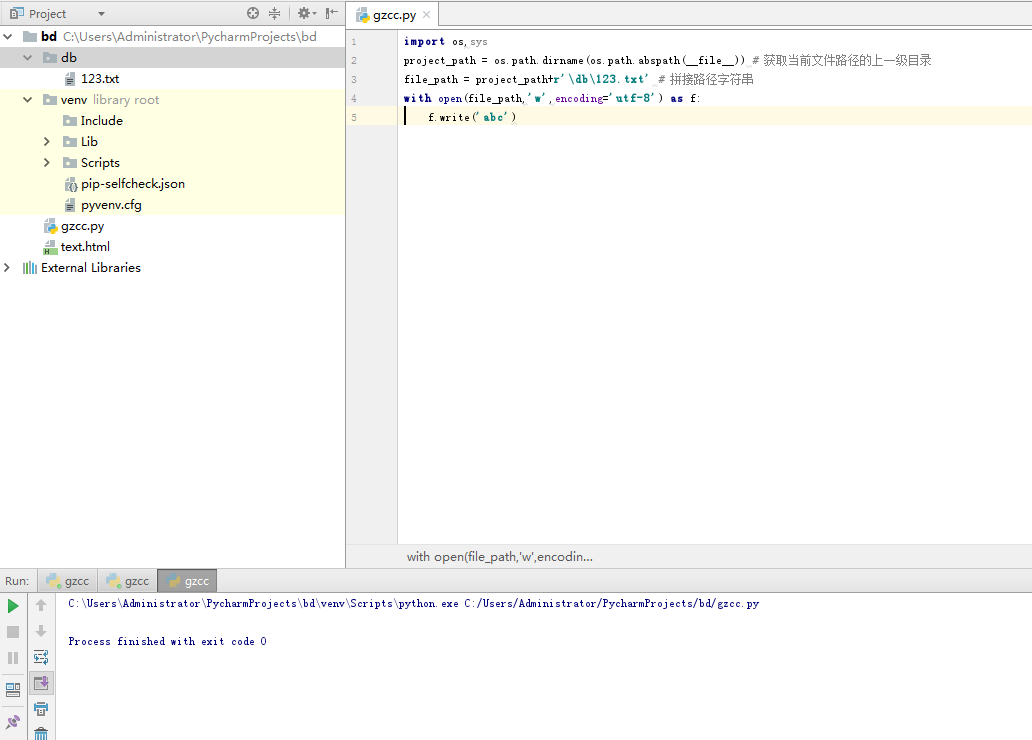
- 绝对路径。
首先在D盘文件夹 PythonPractise 下创建 record.txt 文件:

代码和运行结果如下图: