这个作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319。
1.用自己的话阐明Hadoop平台上HDFS和MapReduce的功能、工作原理和工作过程。
HDFS
功能:分布式文件系统,用来存储海量数据。
工作原理和过程:HDFS是Hadoop的分布式文件系统,HDFS中的文件会默认存储3份,存储在不同的机器上,提供容错机制,副本丢失或者宕机的自动恢复。HDFS总体上采用Master/Slave的架构,整个HDFS架构由Client、NameNode、Secondary NameNode和DataNode构成。NameNode负责存储整个集群的元数据信息,Client可以根据元数据信息找到对应的文件,DataNode负责数据的实际存储。当一个文件上传到HDFS的时候,DataNode会按照Block为基本单位分布在各个DataNode中,而且为了保护数据的一致性和容错性,一般一份数据会在不同的DataNode上默认存储三份。如下图所示:

MapReduce
功能:并行处理框架,实现任务分解和调度。
工作原理和过程:MapReduce的工作过程分成两个阶段,map阶段和reduce阶段。每个阶段都有键值对作为输入输出,map函数和reduce函数的具体实现由程序员完成。MapReduce的框架也是采用Master/Slave的方式组织,如下图所示。由四部分组成,分别为Client、JobTracker、TaskTracker以及Task。JobTracker主要负责资源监控和作业调度。JobTracker监控TaskTracker是否存活,任务执行的状态以及资源的使用情况,并且把得到的信息交给TaskSceduler。TaskSceduler根据每个TaskTracker的情况给分配响应的任务。TaskTracker会周期性通过heartbeats向JobTracker发送资源的使用情况,任务的执行状况等信息,同时会接收JobTracker的指令,TaskTracker把自己可支配的资源分成若干个Slot,Task只有拿到一个Slot资源才能执行任务。Task任务分成Map Task和Reduce Task两种任务,都是由TaskTracker进行调度的。

2.HDFS上运行MapReduce
mapper.py
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class Map extends Mapper<LongWritable, Text, Text,IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key,Text value,Context context) throws IOException, InterruptedException {
word.set(value.toString());
context.write(word, one);
}
}

reduce.py
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Iterator;
public class Reduce extends Reducer<Text, IntWritable, Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int sum = 0;
for(IntWritable intWritable : values){
sum += intWritable.get();
}
context.write(key, new IntWritable(sum));
}
}
#!/usr/bin/env python cd /home/hadoop/wc sudo gedit reduce.py #赋予权限 chmod a+x /home/hadoop/map.py
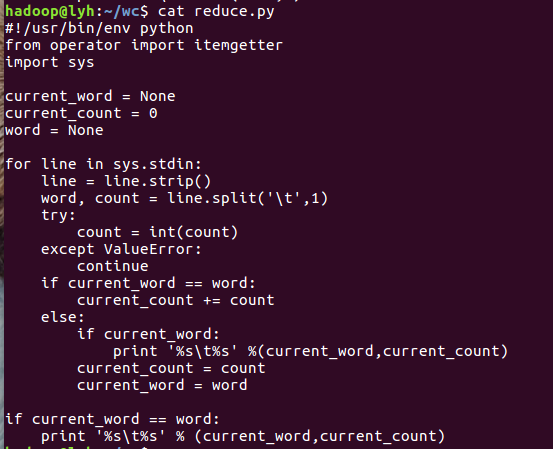
本机上测试运行代码:
echo "foo foo quux labs foo bar quux" | /home/hadoop/wc/mapper.py echo "foo foo quux labs foo bar quux" | /home/hadoop/wc/mapper.py | sort -k1,1 | /home/hadoop/wc/reducer.p
启动Hadoop,HDFS, JobTracker, TaskTracker:


放到HDFS上运行
下载并上传文件到hdfs上:
#上传文件 cd /home/hadoop/wc wget http://www.gutenberg.org/files/5000/5000-8.txt wget http://www.gutenberg.org/cache/epub/20417/pg20417.txt #下载文件 cd /usr/hadoop/wc hdfs dfs -put /home/hadoop/hadoop/gutenberg/*.txt /user/hadoop/input
新建一个文件5000-8.txt,运行结果如下:
![]()
