一、背景
在Flink开发中,上线的任务经常会无故挂掉,刚开始对任务无故挂掉的原因,一无所知,排查起来也比较困难,网上资料也比较模糊不清,后面通过查阅资料和自己的一些经验,总算是有了一些结果,所以想总结一下近段时间所遇到的问题和解决方法。
二、问题陈列
1.Flink On YARN中任务挂掉后,YARN的Web UI显示还在运行,但实际上已经挂掉了
原因:这是由于Flink提交给YARN之后,YARN后续并没有继续监控Flink任务的状态
解决办法:在提交任务时,命令行加一个参数 -d 即可,例如:run -m yarn-cluster -d -p 2 -yn 2 -yjm 1024m -ytm 2048m -ynm xxxx -c xxxx
2.java.lang.Exception: Container released on a *lost* node

原因:YARN队列压力过大或者磁盘满了之后,可能会导致Flink申请的节点标记为失败,导致taskmanager挂掉
解决办法:如果有配置重启策略的话,taskmanager会进行重启,如果没有配置重启策略但是配置了checkpoint,默认的重启策略是无限次重启,但是需要注意一点的是,taskmananger成功重启的前提是jobmanager没有挂掉,如果jobmanager也挂掉了,那么taskmanager重启成功之后也是无效的。
3.生产上的任务频繁挂掉,一开始以为是问题二导致的,但是实际上问题二配置了checkpoint或者重启策略之后会自己重启,所以证明主要原因并不是以上的问题,其实主要的原因就是当YARN的队列资源紧张的时候,也有可能导致jobmanager挂掉,我们生产上的集群并没有配置Flink On YARN的高可用,即jobmanager挂掉之后是不会进行重启的,所以需要配置Flink On YARN的高可用,配置如下(此配置适用于Flink On YARN的yarn-cluster模式):
1)首先配置 yarn-site.xml,配置resourcemanager重启次数
<property> <name>yarn.resourcemanager.am.max-attempts</name> <value>4</value> <description> The maximum number of application master execution attempts. </description> </property>
2)配置flink-conf.yaml ,这里必须添加zookeeper 信息,官方文档yarn-cluster模式只要求添加重启参数,不添加的话,task manager 会和job manager 一起挂掉, 只会重启对应的job manager
# flink job manager次数 这个参数必须小于yarn.resourcemanager.am.max-attempts
yarn.application-attempts: 3
# 添加zookeeper 配置
high-availability: zookeeper
high-availability.zookeeper.quorum: xx.x.x.xxx:2181
# job manager元数据在文件系统储存的位置
high-availability.storageDir: hdfs:///flink/recovery
三、测试
1.启动flink 程序

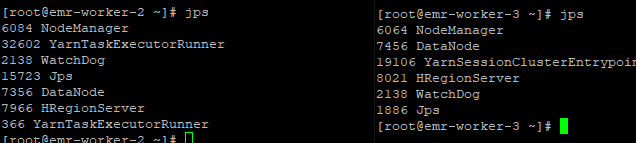
2. kill 掉对应的 YarnSessionClusterEntrypoint (对应job manager)所在进程


3.新的job manager,已经被重启,恰巧也和task Manager一个一个节点
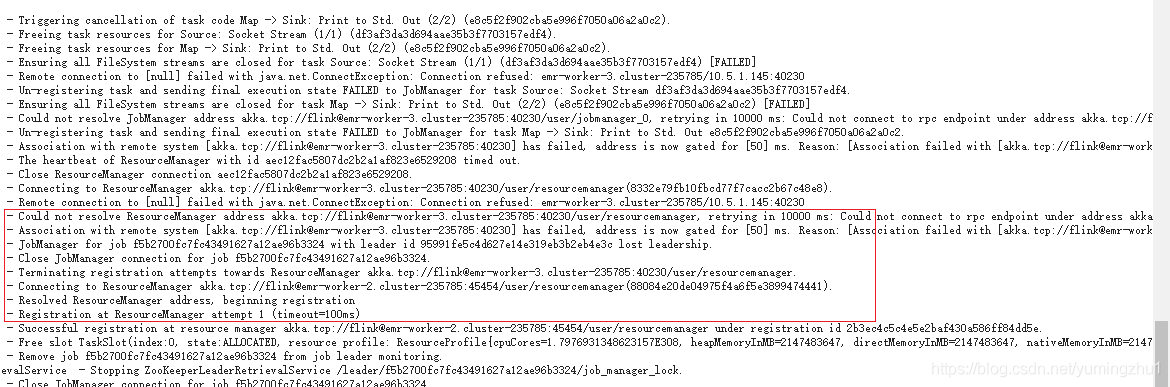
4.task manager 上对应日志如上,与旧的job manager 的ResourceManager通信,当超时大于10s后,将其标记为失败,之后根据zookeeper去注册到新的job manager
注:此配置只能降低Flink的失败次数,如果想让Flink稳定运行,应该还是需要在YARN上单独划分一个队列给实时任务使用,避免因其他因素导致实时任务失败
参考文档:https://blog.csdn.net/yumingzhu1/article/details/118994625