一、背景
平常开发会员一次性的需求,列入将一个大文件导入到CK中进行数据分析,以下记录一下CSV导入到CK的过程:
二、创建表结构
CREATE TABLE default.test_table (
`index` String,
`uuid` String,
`variables` String,
`title` String,
`title_explain` String,
`title_meaning` String
) ENGINE = MergeTree() PARTITION BY sipHash64(uuid)%20 ORDER BY sipHash64(uuid)%20 SETTINGS index_granularity = 8192
注:由于此表没有年月日,所以按照sipHash64(uuid)%20分成20个分区,若这里直接用uuid分区会产生太多的分区,有可能导致分区过多报错,我刚开始没注意的时候,就是因为产生了太多的分区导入失败,报错信息为:
Too many partitions for single INSERT block (more than 100),所以需要注意一下。
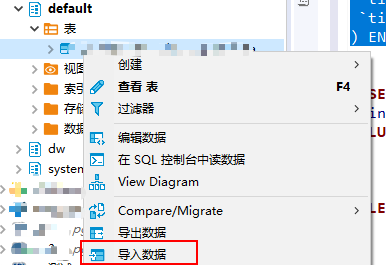
三.导入数据
方式一:登录服务器使用客户端
clickhouse-client -h xxx.x.x.x --database="default" --query="select * from default.test_table FORMAT CSV" < test.csv
方式二:直接连接数据库,例如用dbserver客户到,创建表之后,直接导入数据即可