Measuring Patient Similarities via a Deep Architecture with Medical Concept Embedding
Mothod proposed
Contextual Embedding of Medical Concepts
医学概念的语境嵌入
按照时间顺序把所有的medical events排序,得到一个包含所有单词的段落。然后使用word2vec将单词向量化。
word2vec仅考虑单词的上下文关系,这显然不够,我们还要考虑两个单词间的实际时间间隔大小。
另外,word2vec对于每个单词都有一样的window length,我们需要对不同的患者的不同疾病设置不同的window length,且区分慢性病和急性病,慢性病比急性病的出现频率高,所以慢性病应该比急性病有更大的window scope。

Temporal Patient Representation
有种简单的方法是将每个visit的medical concept转为vector后,将vector相加得到vector(visit),再把所有visit的vector相加得到一个简单的representation vector,但这样会失去时间信息。
本文提出一个表示矩阵X,它的shape是(d,Np),其中d是embedding的维度,Np是该患者的visit次数。对于每一个visit的vector相加(RNN???)得到vector(visit)然后拼接所有Np个vector(visit),得到矩阵X。
Measure Similarity
病人相似度计算
Unsupervised Patient Similarity
无监督方法
- RV coefficient : 通过计算矩阵的秩的比例,计算两个数据之间的线性关系
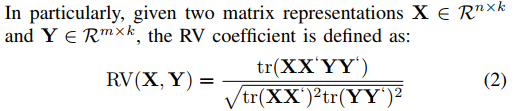
- dCov coefficient : 通过计算向量的欧氏距离得到矩阵的协方差,从而获得两个数据之间的非线性关系

Measure Similarities with Supervision
有监督方法,卷积神经网络处理文本数据,再进行相似度计算
基于ConvNets的模型学习,将输入的患者表示分别映射为表征向量,用于计算它们的相似性分数。
然后用它们来计算患者相似性评分,并与表征向量放在同一个表示中。
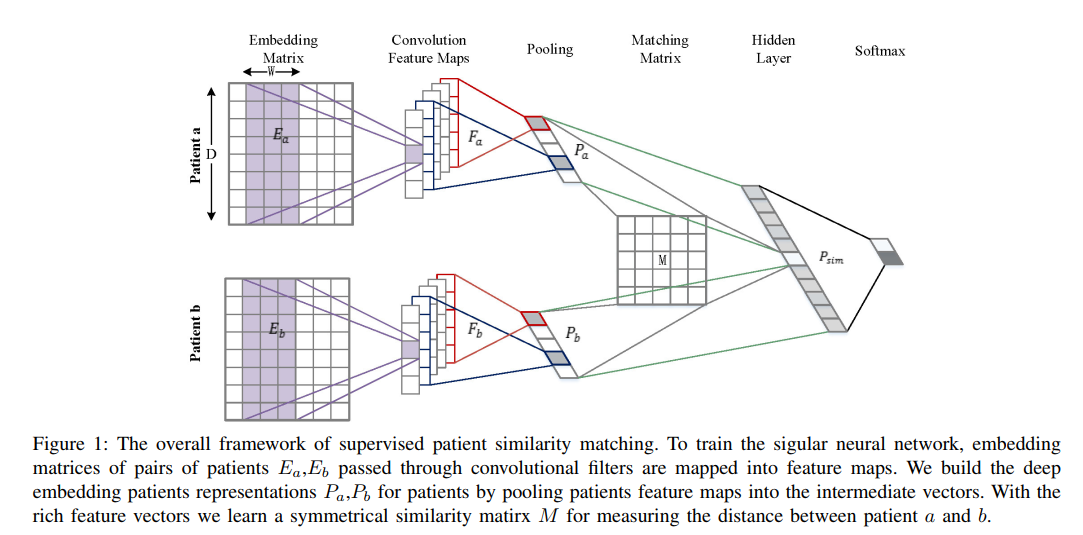
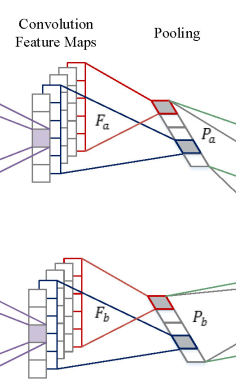
1.卷积操作
紫色部分代表filter权重W,shape(d,h),从左到右滑动得到所有的ci,拼接成一个向量c,shape(n-h+1,1),上图中visit次数n为7,h为3,所以得到向量c的尺度是5。那么多个filter就可以得到Fa和Fb

2.池化操作
对F中的每个c进行最大池化操作,并拼接为P
3.匹配矩阵
将Pa和Pb代入下方公式的x,经过权重m的计算得到相似度分数s

4.fc + dropout + softmax
拼接(Pa,s,Pb)得到x,将输入全连接层和softmax操作得到二分类别概率值
Optimization
优化方法,loss函数设计
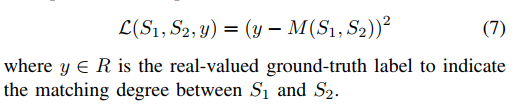
训练的参数有:word embedding, neural network, spatial RNN
Dataset
a real world longitudinal EHR database of 218,680 patients for the course of over four years.
病种:
- Chronic Obstructive Pulmonary Disease (COPD), 慢性阻塞性肺疾病
- Diabetes, 糖尿病
- Heart Failure, 心力衰竭
- Obesity, 肥胖
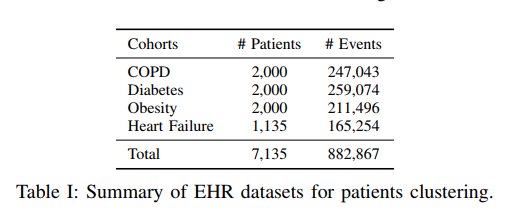
使用ICD-9数据,每个患者至少有40次medical event,删除患有多种疾病的患者信息,删除百分之90患者都有或者不到5个患者拥有的medical event,剩下8000个患者和6064个visit信息。
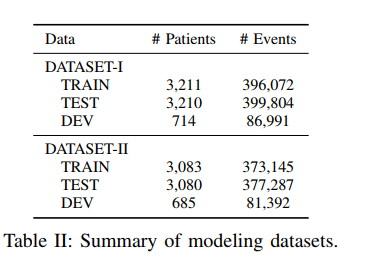
创建了两个数据集:DATASET-I使用完整的medical event。DATASET-II保留历史事件,但删除了作为队列标识符的事件。(不大明白)
将数据集分成具有相同数量患者的训练集和测试集,以及验证集。
Experiment
超参
word2vec + Bag of Words : embedding维度:50
dropout概率: 0.5
卷积filter的宽度w:5, 10, 15, 20, 25
filter(feature map个数m:50, 100, 150, 200
优化器
SGD优化器
聚类评估指标
-
Rand index
-
Purity
-
normalized mutual information
结果分析
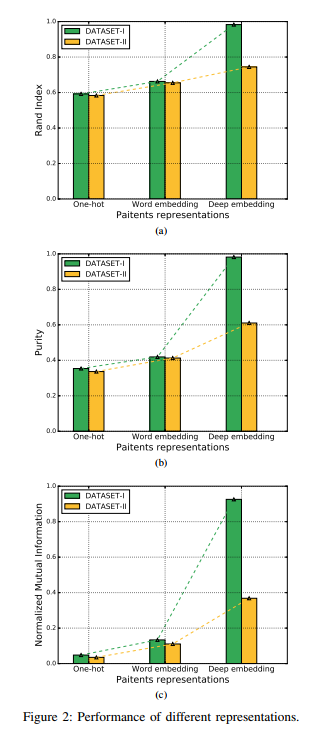
- 不同阶段的feature进行试验比较: (不知道是用的哪个模型)
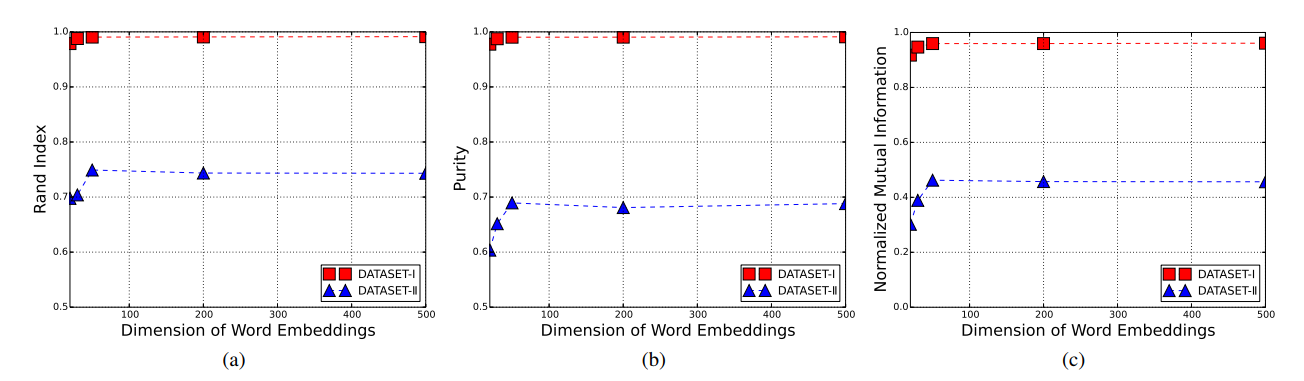
- 超参选择
50 dimensionality embedding, 100 feature maps, and 5 convolution filter width
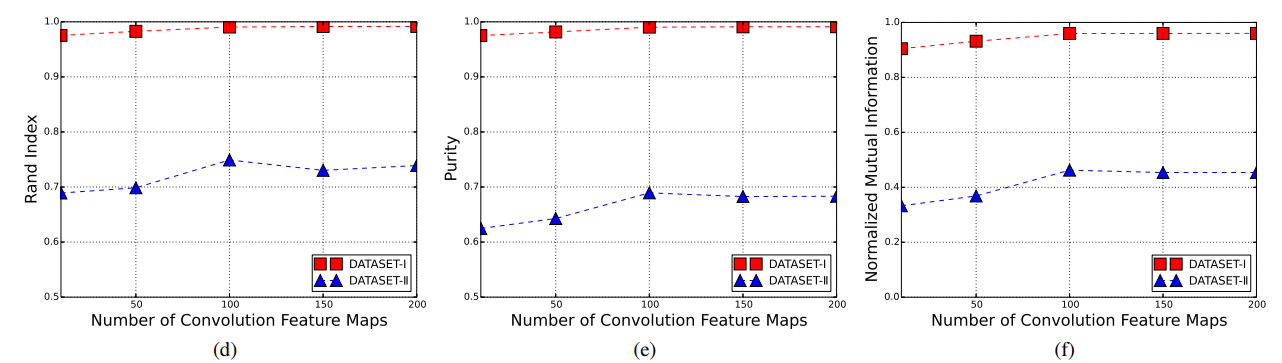
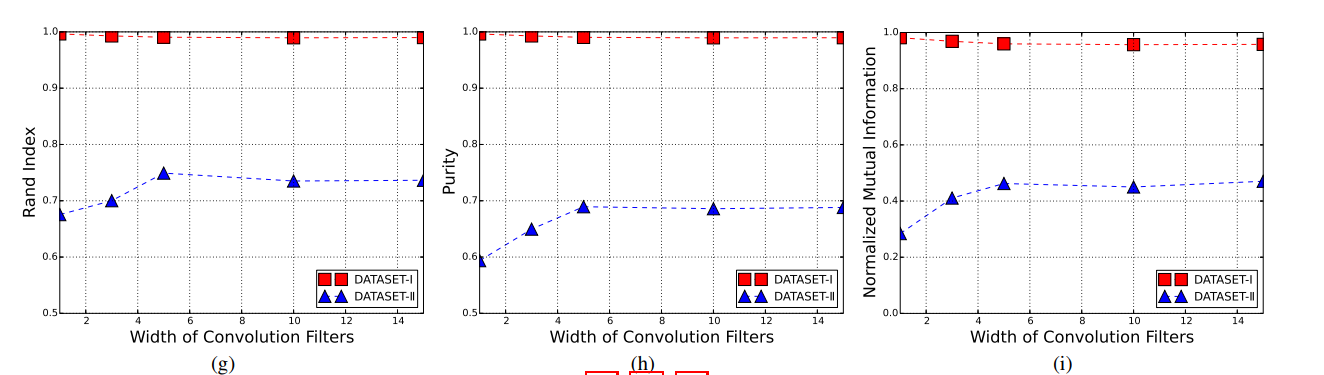
- 实验结果
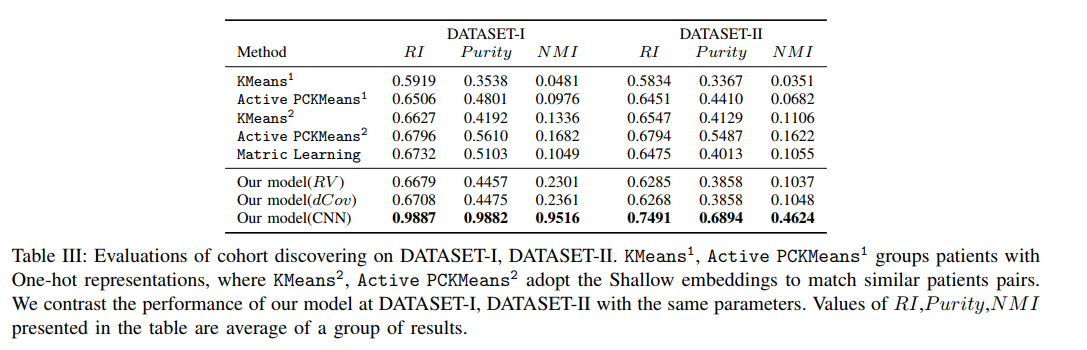
在数据集II上用较少的医疗事件训练模型,正如预期的那样,患者队列受我们处理的数据的影响很小。(不大明白)
与DATASET-I上的标准性能相比,据集II下降到0:75,损失为0:23。从数据集中删除部分数据,造成许多医学特征的丢失。
- 可视化
为了发现EHR背后隐藏的医学模式,从COPD中选出100名相似的患者队列,根据我们的方法将他们分为不同的聚类。
SanKey diagram 桑基图显示了患者EHR中的医疗事件。
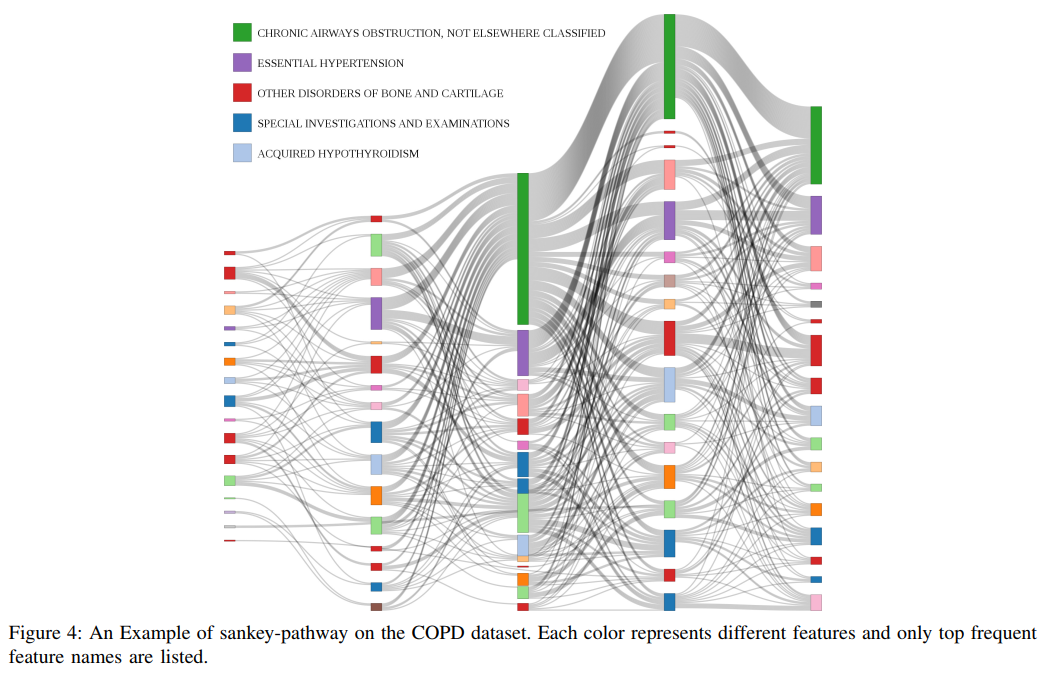
如图所示,绿,紫,红三种颜色有着密切的联系,分别代表慢性气道阻塞,原发性高血压,其他骨和软骨疾病。图中显示的这些疾病的相互作用在现实世界中被大量的医学研究所证实,这使我们相信我们模型的适用性。