聚合函数 取名: field + __ + 聚合函数名字 ,如:price__avg;可传关键字参数修改名字:avg=Avg("price");
aggregate:不会返回一个 QuerySet 对象,而是返回一个字典,key为聚合函数的名字,value为聚合函数执行结果;
annotate:返回一个 QuerySet 对象;
相同点:
- 都可执行聚合函数;可在任何的‘QuerySet’对象上调用,因此只要返回了‘QuerySet’对象,即可进行链式调用,如 index5 中获取年度销售总额,可先过滤年份再求聚合函数;
不同点:
- aggregate 返回一个字典,字典中存储聚合函数执行的结果;而 annotate 返回一个 QuerySet对象 ,并在查找的模型上添加一个聚合函数的属性;
- aggregate 不会做分组,而 annotate 会使用 Group by 字句进行分组,只有调用该字句才能对每一条数据求聚合函数的值;
- 数据库中的内容:

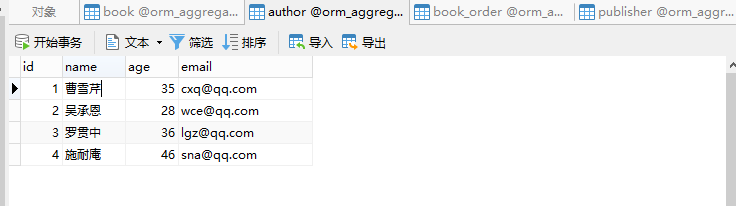
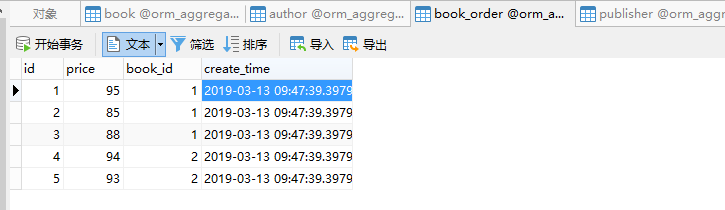
- models.py文件:
1 from django.db import models 2 3 class Author(models.Model): 4 '''作者模型''' 5 name = models.CharField(max_length=100) 6 age = models.IntegerField() 7 email = models.EmailField() 8 9 class Meta: 10 db_table = 'author' 11 12 class Publisher(models.Model): 13 '''出版社模型''' 14 name = models.CharField(max_length=300) 15 16 class Meta: 17 db_table = 'publisher' 18 19 class Book(models.Model): 20 '''图书模型''' 21 name = models.CharField(max_length=300) 22 pages = models.IntegerField() 23 price = models.FloatField() 24 rating = models.FloatField() 25 author = models.ForeignKey(Author,on_delete=models.CASCADE) 26 publisher = models.ForeignKey(Publisher,on_delete=models.CASCADE) 27 28 class Meta: 29 db_table = 'book' 30 31 class Bookorder(models.Model): 32 '''图示订单模型''' 33 book = models.ForeignKey('Book',on_delete=models.CASCADE) 34 price = models.FloatField() 35 create_time = models.DateTimeField(auto_now_add=True,null=True) 36 37 class Meta: 38 db_table = 'book_order'
- views.py文件:
1 from django.shortcuts import render 2 from django.http import HttpResponse 3 from .models import Author,Publisher,Book,Bookorder 4 from django.db.models import Avg,Count,Max,Min,Sum 5 from django.db import connection 6 7 def index(request): 8 # 获取所有图书定价的平均价(使用aggregate);Avg:平均值; 9 result = Book.objects.aggregate(Avg('price')) 10 print(result) 11 print(connection.queries) 12 return HttpResponse('index') 13 # >>>{'price__avg': 97.25} 14 # >>>{'price__avg': 97.25} 15 # {'sql': 'SELECT AVG(`book`.`price`) AS `price__avg` FROM `book`'; 16 17 def index2(requset): 18 # 获取每一本销售的平均价格(使用annotate); 19 books = Book.objects.annotate(avg=Avg('bookorder__price')) 20 for book in books: 21 print("%s:%s" % (book.name,book.avg)) 22 print(connection.queries) 23 return HttpResponse('index2') 24 #三国演义:89.33333333333333 25 # 水浒传:93.5 26 # 西游记:None 27 # 红楼梦:None 28 # `book_order` ON (`book`.`id` = `book_order`.`book_id`) GROUP BY `book`.`id` ORDER BY NULL'; 29 30 def index3(request): 31 # book 表中总共有多少本书; 32 # Count:求某个数据的的个数; 33 result = Book.objects.aggregate(nums=Count('id')) 34 # author 表中总共有多少个不同的邮箱; 35 # 使用‘distinct=True’剔除重复的值; 36 results = Author.objects.aggregate(book_num=Count('email',distinct=True)) 37 38 # 统计每本书的销量 39 books = Book.objects.annotate(book_nums=Count('bookorder')) 40 for book in books: 41 print("%s:%s" % (book.name,book.book_nums)) 42 print(books) 43 print(connection.queries) 44 return HttpResponse("index3") 45 # 三国演义:3 46 # 水浒传:2 47 # 西游记:0 48 # 红楼梦:0 49 50 51 def index4(request): 52 result = Author.objects.aggregate(max=Max('age'),min=Min('age')) 53 # 每本图书售卖前的最大及最小价格; 54 books = Book.objects.annotate(max=Max("bookorder__price"),min=Min("bookorder__price")) 55 for book in books: 56 print("%s:%s:%s" % (book.name,book.max,book.min)) 57 print(connection.queries) 58 return HttpResponse("index4") 59 60 # 三国演义:95.0:85.0 61 # 水浒传:94.0:93.0 62 # 西游记:None:None 63 # 红楼梦:None:None 64 65 66 def index5(request): 67 # 求所有图书的销售总额; 68 result = Book.objects.aggregate(total=Sum("price")) 69 print(result) 70 print(connection.queries) 71 # {'total': 389.0} 72 # {'sql': 'SELECT SUM(`book`.`price`) AS `total` FROM `book`', 'time': '0.001'}; 73 74 # 求每一本图书的销售总额; 75 books = Book.objects.annotate(total=Sum('bookorder__price')) 76 for book in books: 77 print("%s:%s" % (book.name,book.total)) 78 print(connection.queries) 79 # 三国演义: 268.0 80 # 水浒传: 187.0 81 # 西游记: None 82 # 红楼梦: None 83 84 85 # 求2018年度的销售总额; 86 result = Bookorder.objects.filter(create_time__year=2019).aggregate(total=Sum("price")) 87 # 求2018年度每一本图书的销售总额; 88 books = Book.objects.filter(bookorder__create_time__year=2019).annotate(total=Sum("bookorder__price")) 89 for book in books: 90 print("%s:%s" % (book.name,book.total) ) 91 print(connection.queries) 92 # 三国演义: 268.0 93 # 水浒传: 187.0 94 # `book_order`.`create_time` BETWEEN '2019-01-01 00:00:00' AND '2019-12-31 23:59:59.999999' GROUP BY `book`.`id`
- F表达式:动态获取某个字段上的值,不会真正到数据库中查询数据,只起一个标识的作用;
1 def index6(requset): 2 # 给每本书售价增加10元;update; 3 Book.objects.update(price=F('price')+10) 4 print(connection.queries[-1]) 5 # 'UPDATE `book` SET `price` = (`book`.`price` + 10)'; 6 7 # Author中name与email相同的内容; 8 authors = Author.objects.filter(name=F('emile')) 9 for author in authors: 10 print("%s:%s" % (author.name,author.email)) 11 return HttpResponse('index6')
- Q表达式:包裹查询条件,可在条件间进行多种操作:与 & 、或 | 、非 ~ 等查询操作;
1 def index7(requset): 2 # 1、获取价格大于100,评分大于4.5的图书; 3 # books = Book.objects.filter(price__gte=100,rating=4.5) 4 books = Book.objects.filter(Q(price__gte=100)&Q(rating__gte=4.5)) 5 for book in books: 6 print("%s:%s:%s" % (book.name,book.price,book.rating)) 7 8 --- 9 10 # 2、获取价格低于100,或者评分低于4.5分的图书; 11 books = Book.objects.filter(Q(price__lt=100)|Q(rating__lt=4.5)) 12 for book in books: 13 print("%s:%s:%s" % (book.name,book.price,book.rating)) 14 15 --- 16 17 # 3、获取价格大于100,并且图书名字不包含“传”字的图书; 18 books = Book.objects.filter(Q(price__gte=100)&~Q(name__icontains='传')) 19 for book in books: 20 print("%s:%s:%s" % (book.name,book.price,book.rating)) 21 return HttpResponse('index7')