**主要参考: http://www.bogotobogo.com/Linux/linux_process_and_signals.php **
译者:李秋豪
信号与进程几乎控制了操作系统的每个任务。
在shell中输入ps -ef命令,我们将得到如下结果:
(译者注:-e Select all processes. Identical to -A; -f Do full-format listing. This option can be combined with many other UNIX-style options to add additional columns. It also causes the command arguments to be printed.)
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 2010 ? 00:01:48 init
root 21033 1 0 Apr04 ? 00:00:39 crond
root 24765 1 0 Apr08 ? 00:00:01 /usr/sbin/httpd
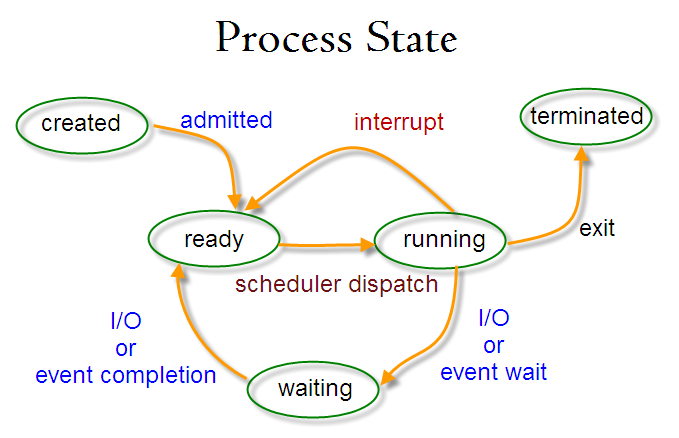
每一个进程都会被赋予一个特殊的整数,称为进程标识符 (process identifier PID) ,PID的范围是2~32768。当一个进程启动的时候,数字最少会从2开始算,因为1是为init进程保留的——正如上面这个例子可以看到的,init进程会管理其他的进程。
当我们运行一个程序时,保存在硬盘上的可执行指令集就会被加载到内存中的一个区块中,通常来说,一个linux进程是不能向这个区块进行写操作的。(所以说,这个区块可以被安全地共享)
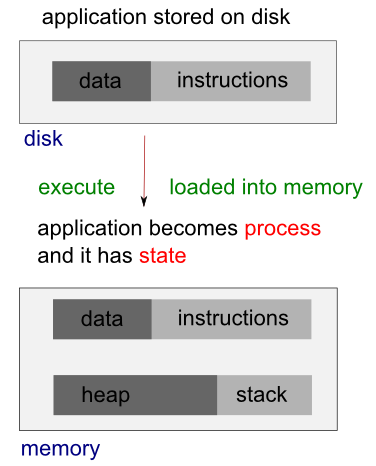
同样,系统的库也可以被共享。因此,即使很多程序都用到了printf这个函数,在内存中只要有一份拷贝就够了。
与能够共享的库不同,一个程序或许会有自己的内部变量,这些变量是保存在程序自己独有的栈空间中的,无法和另外的进程共享。每个进程也有自己管理的独有的环境变量。另外,每个进程也应该有自己独有的程序计数器(PC)——用来记录程序执行到哪里了。(执行线程请参考 linux pthread)
进程表
进程表中保存了当前内存中加载的所有进程,我们可以使用ps命令将其显示出来。但是,默认情况下ps只会显示和终端或者伪终端或者串行链接(serial line)保持连接的进程。其他不需要和用户终端交互的进程是由操作系统负责管理共享资源的。为了显示所有的程序,我可以使用-e和-f参数。
(译者注:To see every process on the system using standard syntax: ps -ef)
系统进程
$ ps -ax
PID TTY STAT TIME COMMAND
1 ? Ss 1:48 init [3]
2 ? S< 0:03 [migration/0]
3 ? SN 0:00 [ksoftirqd/0]
....
2981 ? S<sl 10:14 auditd
2983 ? S<sl 3:43 /sbin/audispd
....
3428 ? SLs 0:00 ntpd -u ntp:ntp -p /var/run/ntpd.pid -g
3464 ? Ss 0:00 rpc.rquotad
3508 ? S< 0:00 [nfsd4]
....
3812 tty1 Ss+ 0:00 /sbin/mingetty tty1
3813 tty2 Ss+ 0:00 /sbin/mingetty tty2
3814 tty3 Ss+ 0:00 /sbin/mingetty tty3
3815 tty4 Ss+ 0:00 /sbin/mingetty tty4
.....
19874 pts/1 R+ 0:00 ps -ax
19875 pts/1 S+ 0:00 more
21033 ? Ss 0:39 crond
24765 ? Ss 0:01 /usr/sbin/httpd
STAT对应的字符含义如下表所示:
| STAT Code | Description |
|---|---|
| R | 正在运行或者有能力运行。 |
| D | 不间断的睡眠 (等待中) - 通常是为了等待完成输入输出。 |
| S | 睡眠中. 通常是在等待一个事件, 例如一个信号或者输入变成可获得的。 |
| T | 已停止. 通常是被shell的job控制了或者正在被一个调试器进行调试。 |
| Z | 死亡/失效的僵尸进程. |
| N | 低优先级, nice(译者注:nice后面会提到). |
| W | 分页. |
| s | 这个进程是会话中的首进程. |
| + | 这个进程在前台工作组中。 |
| l | 这个进程是多线程的。 |
| < | 高优先级的任务。 |
观察下面这个进程:
1 ? Ss 1:48 init [3]
每一个子进程都是由父进程fork出来的。当linux开始运行时,它只运行了一个进程:init, PID为1。init是系统的进程管理者,并且它是其他所有进程的直接/间接父进程。当init fork出进程后,这些进程又开始fork进程(类似于病毒传播)。登录就是一个例子:init会为每个终端通过fork出getty这个进程,通过它我们可以进行登录操作。如下所示:
3812 tty1 Ss+ 0:00 /sbin/mingetty tty1
getty进程会等待被终端激活,为用户输出登录时候的提示符,然后把控制交给登录相关的程序,这些程序会建立起用户的环境然后启动一个shell。当用户从这个shell退出的时候,init会启动另一个getty进程。
启动新的进程并等待他们结束是一个操作系统的基本任务。我们也可以通过使用系统调用fork(), exec(), wait(), 完成这些工作。
一个系统调用相当于一个可控的和内核交流的入口,通过这些调用,进程可以要求内核提供一些服务和工作。
事实上,一个系统调用会将处理器的用户状态转化为内核状态,因此cpu可以访问内存中被保护的内核模块。内核通过系统调用API为进程提供了非常丰富的服务。
进程调度
让我看看ps ax本身的STAT:
23603 pts/1 R+ 0:00 ps ax
R代表进程23603处于runnable状态。换句话说,它监测了自己的状态。指示器只是表明了这个程序处于可运行状态,并不一定正在运行(参见下面的资料,可能在runqueue中)。R+表示出这个进程是在前台工作组中,所以它不会等待其他的进程完成也不会等待输入输出完毕。这也是为什么我们可能在ps的输出中看到两个以上R+的进程。
(译者:这个地方感谢胡尧学长指点,之前有几句话没有理解正确)
译者:参考一下Process State Definition和Runnable Process Definition :(有时间我会把这两篇翻译一下)(更新:已经翻译了:Linux 进程状态标识和Linux 可运行进程 )
1.节选Process State Definition中前一部分:
Process state is the state field in the process descriptor.
A process descriptor is a task_struct-type data structure whose fields contain all of the information about a single process. A process, also referred to as a task, is an instance of a program in execution.
A data structure is a way of storing data in a computer so that it can be used efficiently. task_struct is a relatively large data structure (roughly 1.7 kilobytes on a 32-bit machine) that is designed to hold all the information that the kernel (i.e., the core of the operating system) has and needs about a process.
The state field in the process descriptor describes what is currently happening to a process. This field contains one of the following five flags (i.e., values):
TASK_RUNNING: The process is runnable, and it is either currently running or it is on a runqueue waiting to run. This is the only possible state for a process executing in user space (i.e., that portion of system memory in which user processes run); it can also apply to a process in kernel space (i.e., that portion of memory in which the kernel executes and provides its services) that is actively running. A runnable process is a process that is in the TASK_RUNNING process state.
A runqueue is the basic data structure in the scheduler, and it contains the list of runnable processes for the CPU (central processing unit), or for one CPU on a multiprocessor system. The scheduler, also called the process scheduler, is a part of the kernel that allocates the scare CPU time among the various runnable processes on the system.
2.Runnable Process Definition
A runnable process is a process which is in the TASK_RUNNING process state.
A process, also referred to as a task, is an instance of a program in execution. A process state is a field in the process descriptor. This field can accept any of five possible flags (i.e., values), one of which is TASK_RUNNING.
A process descriptor is a task_struct-type data structure whose fields contain all of the information regarding a single process. Its process state field describes what is currently happening to the process. A data structure is a way of storing data in a computer so that it can be used efficiently. A task_struct data structure is a data structure that is used to describe a process on the system.
The TASK_RUNNING state means that the process is runnable, and it is either currently running or on a runqueue waiting to run. This is the only possible state for a process executing in user space (i.e., that portion of system memory in which user processes run); it can also apply to a process in kernel space (i.e., that portion of memory in which the kernel executes and provides its services) that is actively running.
A runqueue is the basic data structure in the scheduler, and it contains the list of runnable processes for the CPU (central processing unit), or for one CPU on a multiprocessor system. The scheduler, also called the process scheduler, is a part of the kernel that allocates the scare CPU time among the various runnable processes on the system.
Linux内核使用一个叫做进程调度器的程序通过进程的优先级判断哪个进程会获得下一个cpu时间片。
通常情况下,几个程序会同时竞争计算资源。如果一个程序只占用少量的计算资源并且会停下来等待输入,我们就说它是“安分守己的”——与此相反,有的进程会不断的霸占系统的计算资源。术语上我们把“安分守己”的程序称作美好(nice)程序。同时,这种美好程度(niceness)也是可计量的。
操作系统通过进程的nice值来判断该进程的优先级。长时间不暂停的程序通常会有更低的优先级(译者:没懂,如果这样的程序是非常不nice的——需要很多计算资源的进程,还是给它很小的优先级吗?),相反地,暂停的程序会得到“奖赏”——这保证了交互式进程可以很快的相应用户,当它在等待用户输入时,操作系统会提高的它的优先级,这样当它准备恢复运行的时候就已经是高优先级了。
nice值(niceness)是一个从-20到20的整数,-20代表最高的优先级,19或者20代表最低的优先级。一个子进程的默认优先级是从它的父进程继承来的,通常是0。我们可以通过nice命令设置nice值,也可以使用renice命令更改nice值。nice命令每次会把进程的nice值提高10,使得它的优先级降低。只有root权限的用户可以降低进程的nice值(提高优先级)。在Linux上你可以改变 /etc/security/limits.conf来允许别的用户或者组降低nice值。
我们可以通过ps和参数-l或-f查看进程的nice值:
(译者注:-l Long format. The -y option is often useful with this. -y Do not show flags; show rss in place of addr. This option can only be used with -l.)
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
0 S 601 12649 12648 0 75 0 - 1135 wait pts/0 00:00:00 bash
0 S 601 12681 12649 0 76 0 - 1122 wait pts/0 00:00:00 myTest.sh
0 S 601 12682 12681 0 76 0 - 929 - pts/0 00:00:00 sleep
0 R 601 12683 12649 0 76 0 - 1054 - pts/0 00:00:00 ps
:这里我们可以看到 myTest.sh程序是运行在默认nice值0下(译者注:NI列)。但如果它是这么启动的:
$ nice ./myTest.sh &
那么它的nice值就会+10。
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
0 S 601 9835 9834 0 75 0 - 1135 wait pts/1 00:00:00 bash
0 S 601 12744 12649 0 86 10 - 1122 wait pts/0 00:00:00 myTest.sh
0 S 601 12745 12744 0 86 10 - 929 - pts/0 00:00:00 sleep
0 R 601 12746 12649 0 76 0 - 1054 - pts/0 00:00:00 ps
也可以这样做:
$ renice 10 12681
12681: old priority 0, new priority 10
有了更高的nice值,这个程序会更少的运行。如下图所示,STAT列的值多了一个N标记,说明这个进程的nice值和默认不同了。
$ ps x
12649 pts/0 Ss 0:00 -bash
12744 pts/0 SN 0:00 /bin/bash ./myTest.sh
12745 pts/0 SN 0:00 sleep 100
12867 pts/0 R+ 0:00 ps x
The PPID field of ps output indicates the parent process ID, the PID of either the process that caused this process to start or, if that process is no longer running, init (PID 1).ps输出中PPID列表示了该进程父进程的PID,如果那个父进程没有运行了,就会是init(PID 1) 。
init进程 / 守护进程
(译者注:守护来自于daemon这个词,它有两个含义:1.(esp in Greek mythology) supernatural being that is half god, half man (尤指希腊神话中的)半人半神的精灵. 2. spirit that inspires sb to action or creativity 守护神.)
当我们启动系统的时候,内核会创建一个叫做init的进程(来自于/sbin/init),它是所有其他进程的“祖宗”。
系统上所有的其他进程都是通过调用fork()从init或者它的后代生成的。init进程总是拥有为1的PID和超级用户的权限。它也不能被终止掉,除非机器关机。inti的主要功能就是相应操作系统生成其他进程并监视管理所有进程。
守护进程是一个有着特殊目的的进程(例如syslogd, httpd等等),它也是由操作系统负责生成并管理的,但它和普通的进程有以下两个不同:
- 长寿命。一个守护程序通常会在系统启动的时候就开始运行,直到机器关机。
- 它是在后台运行的,也就是说没有一个和它连接的终端可以用来输入输出。
创建一个新进程
我们可以在一个程序中启动另一个程序,system库函数就是用来创建新进程的。下面这个例子就通过调用system运行了ps.
// mySysCall.c
#include <iostream>
int main()
{
system("ps ax");
std::cout << "Done." << std::endl;
exit(0);
return 0;
}
如果运行这个程序,输出如下:
$./mySysCall
PID TTY STAT TIME COMMAND
1 ? Ss 1:48 init [3]
....
24447 pts/0 S+ 0:00 ./mySysCall
24448 pts/0 R+ 0:00 ps ax
Done.
因为system是通过一个shell启动新的进程的,我们也可以做一个改变:
system("ps ax &");
运行这个新的版本,输出如下:
Done.
PID TTY STAT TIME COMMAND
1 ? Ss 1:48 init [3]
....
24849 pts/1 Ss+ 0:00 -bash
25802 pts/1 R 0:00 ps ax
现在,system在shell命令完成后就立即返回了。因为它要求shell将这个新程序放在后台运行,shell会在ps程序启动后立即返回。这和我们在shell中输入相同的命令是一样的:
$ps ax &
shell返回后,我们的程序就打印出“Done.“并在ps命令有机会完成输出前退出。这看起来有些难以理解,所以我们也需要完全控制进程的行为。
exec() 系统调用
exec函数会将当前的进程替换为一个新的进程,这个新的进程可以由路径或者文件参数指定。我们可以使用exec将我们正在执行的程序切换到另一个。
如下图所示,我们在bash中发起ls命令。在这种情况下,shell作为父进程,通过调用fork()创建出一个子进程,这个子进程随之调用exec()将之变为ls 。
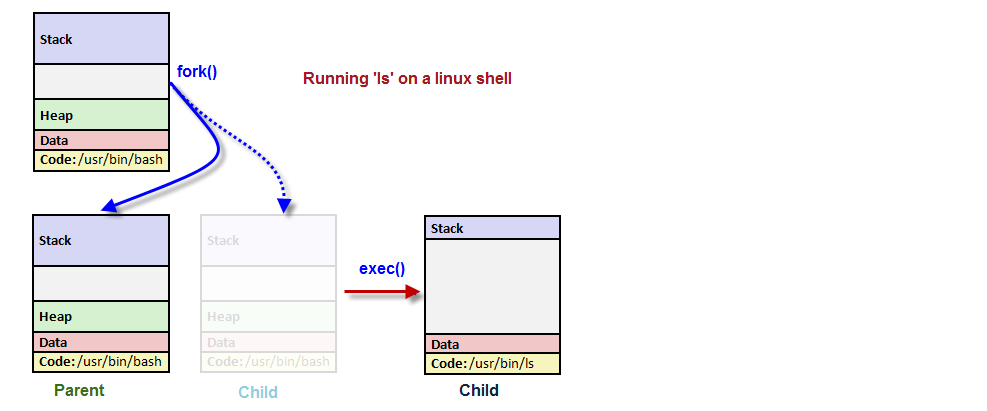
exec会比system更加有效率,因为调用exec后父进程就不会再运行了。
(译者注: The exec() family of functions replaces the current process image with a new process image. )
/* Execute PATH with arguments ARGV and environment from `environ'. */
extern int execv (__const char *__path, char *__const __argv[])
__THROW __nonnull ((1));
/* Execute PATH with all arguments after PATH until a NULL pointer,
and the argument after that for environment. */
extern int execle (__const char *__path, __const char *__arg, ...)
__THROW __nonnull ((1));
/* Execute PATH with all arguments after PATH until
a NULL pointer and environment from `environ'. */
extern int execl (__const char *__path, __const char *__arg, ...)
__THROW __nonnull ((1));
/* Execute FILE, searching in the `PATH' environment variable if it contains
no slashes, with arguments ARGV and environment from `environ'. */
extern int execvp (__const char *__file, char *__const __argv[])
__THROW __nonnull ((1));
/* Execute FILE, searching in the `PATH' environment variable if
it contains no slashes, with all arguments after FILE until a
NULL pointer and environment from `environ'. */
extern int execlp (__const char *__file, __const char *__arg, ...)
__THROW __nonnull ((1));
这些函数大多是通过使用execve实现的,以p作为后缀的函数会在环境变量PATH对应的地方搜寻那个要运行的程序,如果没有找到可运行的那个程序,你必须给这个函数传入一个文件的绝对路径作为参数。
全局变量environ可以给新的程序传递环境参数。execle和execve有另外的方法:你可以传入一个字符串数组用来建立新程序的环境。
下面是使用execlp的一个例子:
(译者注:unistd.h 是 C 和 C++ 程序设计语言中提供对 POSIX 操作系统 API 的访问功能的头文件的名称。该头文件由 POSIX.1 标准(单一UNIX规范的基础)提出,故所有遵循该标准的操作系统和编译器均应提供该头文件(如 Unix 的所有官方版本,包括 Mac OS X、Linux 等)。)
// my_ps.c
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
int main()
{
printf("ps with execlp
");
execlp("ps", "ps", 0);
printf("Done.
");
exit(0);
}
当我们运行这个程序,输出将会只有ps的标准输出而没有"Done", 同样的,我们在ps的输出中也找不到my_ps这个进程。
$./my_ps
ps with execlp
PID TTY TIME CMD
12377 pts/0 00:00:00 bash
18304 pts/0 00:00:00 ps
这个程序打印出了第一个“ps with execlp”,然后调用了execlp() ——在PATH环境变量对应的地方搜索一个叫做ps的程序。最后它执行ps以代替my_ps ,就像我们在shell中执行以下命令一样:
$ ps
(译者注:举个例子,实际上,bash里面就有一个exec命令,我们平时在bash中执行的命令都是在生成了子进程,并没有替换当前shell的进程,如果在bash中直接使用exec ps会马上”退出“bash——输出你也来不到,如果我们在一个bash中输入bash,然后输入exec ps ,就会得到正确的输出,但是这个时候实际上已经在第一个bash里面了,输入一个exit就能退出shell了。)
所以,当ps进程完毕时,我们会得到一个shell的提示符而不是返回到my_ps 。因此,第二个printf没有打印出”Done“这个消息。exec得到的新进程的PID和nice值都是和”父进程“一样的。
为了让一个进程可以同时进行多个函数,我们可以使用threads或者完全创建另一个进程,就像init做的,而不是像exec一样替换现有进程。
其中的一种方法就是调用fork().
fork() 与 execv()
在下面的代码中,fork先在父进程中穿创建子进程,随后这个子进程调用exec将父进程的代码替换为path中指定的值。
void main(char *path, char *argv[]) (译者:main函数第一个参数还可以指针类型?)
{
pid_t pid = fork();
if (pid == 0)
{
printf("Child
");
execv(path, argv);
}
else
{
printf("Parent %d
", pid);
}
printf("Parent prints this line
");
}
fork() 系统调用
(译者注:可以先看一下中文的一个教程linux中fork()函数详解(原创!!实例讲解),觉得讲解的不错,特别是fork的时候流缓冲区的问题和fork返回值的问题很有意思。)
我们可以调用fork()来创建一个新的进程。这个系统调用会”复制“当前的进程,在进程表中产生一个新的入口,新的进程的很多属性和负进程是相同的。
理解fork()的关键点在于当它返回时,会存在两个进程,并且,在两个进程中,程序会从fork()返回的地方继续开始执行。
Linux会复制父进程完整的地址空间并把它赋值给子进程。因此,父进程和子进程拥有完全相同内容的地址空间/代码。但是这两个进程是互相独立的,它们有自己的独立的环境,数据空间,文件描述符等等。所以,和exec()相结合,fork()就是我门需要用来创建新程序的调用。
另外,要注意的是,fork()被调用一次会返回两次!(译者注,这句话本来放在前面,但放在这好像好一些)
对于父进程,fork()会返回新创建的子进程的PID ——这是很有用的,因为父进程可能会创建很多进程并监视它们的状态(通过wait()函数)(译者注:wait, waitpid, waitid - wait for process to change state),对于子进程,fork()会返回0。如果必要的话,进程可以通过getpid()获得本进程的PID ,通过getppid()获得父进程的PID (译者注:如果父进程已经死亡,PPID将会是1)。如果fork()调用失败会返回-1,这要么是因为子进程数量上的限制(CHILD_MAX ,errno会被设置成EAGAIN) ,要么是因为进程表中没有足够的空间再创建一个入口或者(虚拟)内存不足(errno会被设置成ENOMEM )。
那么,在fork()之后哪一个进程会先运行呢?
是子进程?还是父进程?
事实上,这是未定义的!
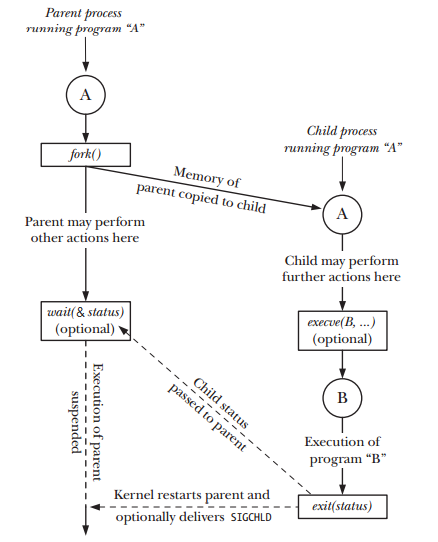
上面的参考图来自于 "The Linux Programming Interface"
下面是个总结:
系统调用fork()不需要参数转入并且会返回一个PID. 使用fork()的目的在于创建一个新的进程,也就是其父进程的子进程。在新的子进程创建后,父与子都会从fork()调用的下一条指令开始执行。因此,我们必须区分哪一个是父进程,哪一个是子进程,这可以通过fork()的返回值来判断:
- 如果返回一个负值,那么调用失败。
- 如果返回的是0,那么当前处于新创建的子进程。
- 如果返回一个正数,那这个数代表新创建的子进程的PID(这个正数是pid_t类型的,声明在sys/types.h)。正常情况下,这个正数是一个整数。另外,一个进程可以使用
getpid()来获取本进程的PID。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
//译者注:还应该包括unistd.h
#define BUF_SIZE 150
int main()
{
int pid = fork();
char buf[BUF_SIZE];
int print_count;
switch (pid)
{
case -1:
perror("fork failed");
exit(1);
case 0:
/* When fork() returns 0, we are in the child process. */
print_count = 10;
sprintf(buf,"child process: pid = %d", pid);
break;
default: /* + */
/* When fork() returns a positive number, we are in the parent process
* (the fork return value is the PID of the newly created child process) */
print_count = 5;
sprintf(buf,"parent process: pid = %d", pid);
break;
}
for(;print_count > 0; print_count--) {
puts(buf);
sleep(1);
}
exit(0);
}
Output is:
child process: pid = 0
parent process: pid = 13510
child process: pid = 0
parent process: pid = 13510
child process: pid = 0
parent process: pid = 13510
child process: pid = 0
parent process: pid = 13510
child process: pid = 0
parent process: pid = 13510
child process: pid = 0
child process: pid = 0
child process: pid = 0
child process: pid = 0
child process: pid = 0
正如输出中所看到的,fork()在父进程中返回了子进程的PID,在子进程中返回了0. 我们使用fork()创建的子进程独立于父进程运行。但是有些时候,我们想要知道子进程是否运行完了,如果父进程提前于子进程运行完毕,就像上面这个例子,这会很让人困惑。所以,我们需要通过wait()函数来等待子进程执行完毕。
译者注:在我的机器(Ubuntu 16.04 gcc 5.4 bash 4.3.48)上运行结果如下:
frank@under:~/tmp$ ./a.out
parent process: pid = 24238
child process: pid = 0
parent process: pid = 24238
child process: pid = 0
parent process: pid = 24238
child process: pid = 0
parent process: pid = 24238
child process: pid = 0
parent process: pid = 24238
child process: pid = 0
child process: pid = 0
frank@under:~/tmp$ child process: pid = 0 #这里
child process: pid = 0
child process: pid = 0
child process: pid = 0
ls
a.out hellolinux hellolinux.c test.c test.s
frank@under:~/tmp$
这其中标识的那一行很有意思,bash的提示符先于子程序结束前出现了,我猜想是因为bash只是等待父进程执行完毕然后开始接受新的输入,对于这个父进程产生的子进程它并不关心。于是乎我做了一个小实验:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#define BUF_SIZE 150
int main()
{
int pid = fork();
char buf[BUF_SIZE];
int print_count;
switch (pid)
{
case -1:
perror("fork failed");
exit(1);
case 0:
/* When fork() returns 0, we are in the child process. */
print_count = 10;
sprintf(buf,"child process: pid = %d", pid);
break;
default: /* + */
/* When fork() returns a positive number, we are in the parent process
* (the fork return value is the PID of the newly created child process) */
print_count = 5;
sprintf(buf,"parent process: pid = %d", pid);
break;
}
for(;print_count > 0; print_count--) {
puts(buf);
sleep(1);
}
if(pid)
{
return 1;//the parent process
}
else
{
return 0;//the child process
}
}
如果bash也监控子进程,那么由于子进程是后来完成的,bash得到的返回值应该是0,否则就是1.结果输出如下:
frank@under:~/tmp$ ./a.out
parent process: pid = 26290
child process: pid = 0
parent process: pid = 26290
child process: pid = 0
parent process: pid = 26290
child process: pid = 0
parent process: pid = 26290
child process: pid = 0
parent process: pid = 26290
child process: pid = 0
child process: pid = 0
frank@under:~/tmp$ child process: pid = 0
child process: pid = 0
child process: pid = 0
child process: pid = 0
echo $?
1
frank@under:~/tmp$
可以看到,其返回值是1,猜想正确。
wait() 系统调用
使用wait()的主要是为了和子进程的同步性。
- 暂时将父进程挂起,直到某一个子进程终止。
- 返回值是终止子进程的PID,对于一个成功返回的进程,父进程将会回收子进程 。
- 如果child_status != NULL , status 的值将会反映子进程终止的原因。
- 如果父进程有多个子进程,那么
wait()将会在任何一个子进程终止的时候返回。 waitpid()可以被用来等待特定的子进程。
父进程需要知道什么时候它的子进程终止了或者状态改变了或者接收到一个信号而停止了。wait()就是监视子进程的其中一个方法(另一个是SIGCHLD信号)。
(译者注:SIGCHLD 20,17,18 Ign Child stopped or terminated)
wait()会锁住调用的进程直到它的子进程退出或者接收到了一个信号,wait()会接受一个整型的地址参数并返回完成的子进程的PID 。
#include <sys/wait.h>
pid_t wait(int *child_status);
再一次说明。调用wait()的一个主要目的就是等待子进程执行完毕。
wait()的执行可以分为两种情况:
- 如果调用
wait()的时候存在子进程,调用者将暂时被挂起,直到其中一个子进程终止它才会恢复运行。 - 如果调用
wait()的时候没有子进程,那么wait()相当于不起作用。
系统调用wait(&status) 有两个目的:
- 如果调用子进程没有调用 exit()退出,调用者将暂时被挂起,直到其中一个子进程终止它才会恢复运行。(译者:这他妈不都讲了几遍啊,严重怀疑作者凑字数)
- 子进程的终止状态返回到了
wait()的status变量里。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
//译者:#include <unistd.h>
//译者:#include <sys/wait.h>
//译者:这作者是不是喝酒了啊,自己都说wait在sys/wait.h里面。。)
#define BUF_SIZE 150
int main()
{
int pid = fork();
char buf[BUF_SIZE];
int print_count;
switch (pid)
{
case -1:
perror("fork failed");
exit(1);
case 0:
print_count = 10;
sprintf(buf,"child process: pid = %d", pid);
break;
default:
print_count = 5;
sprintf(buf,"parent process: pid = %d", pid);
break;
}
//if(!pid) { 译者注:又TMD写错了,这是子进程,醉了。。
if(pid) {
int status;
int pid_child = wait(&status;);
}
for(;print_count > 0; print_count--) puts(buf);
exit(0);
}
现在父进程会等待子进程执行完毕才会开始打印:
child process: pid = 0
child process: pid = 0
child process: pid = 0
child process: pid = 0
child process: pid = 0
child process: pid = 0
child process: pid = 0
child process: pid = 0
child process: pid = 0
child process: pid = 0
parent process: pid = 22652
parent process: pid = 22652
parent process: pid = 22652
parent process: pid = 22652
parent process: pid = 22652
译者注:稍微改了一下,看看wait()的返回值和对status做的改变:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/wait.h>
#define BUF_SIZE 150
int main()
{
int pid = fork();
char buf[BUF_SIZE];
int print_count;
int status = 12345;
int pid_child;
switch (pid)
{
case -1:
perror("fork failed");
exit(1);
case 0:
print_count = 10;
sprintf(buf,"child process: pid = %d", pid);
break;
default:
print_count = 5;
sprintf(buf,"parent process: pid = %d", pid);
break;
}
if(pid) {
pid_child = wait(&status);
}
for(;print_count > 0; print_count--) puts(buf);
if (pid)
{
printf("pid = %d
", pid);
printf("pid_child = %d
", pid_child);
printf("status = %d
", status);
}
exit(0);
}
运行输出:
frank@under:~/tmp$ ./a.out
child process: pid = 0
child process: pid = 0
child process: pid = 0
child process: pid = 0
child process: pid = 0
child process: pid = 0
child process: pid = 0
child process: pid = 0
child process: pid = 0
child process: pid = 0
parent process: pid = 842
parent process: pid = 842
parent process: pid = 842
parent process: pid = 842
parent process: pid = 842
pid = 842
pid_child = 842
status = 0
frank@under:~/tmp$
很明显,status被改变为0,wait()返回的值就是子进程的PID 。
exit() 库函数调用 / _exit() 系统调用
exit(status)库函数是用来终止进程的,同时使得进程占用的所有资源(内存,打开的文件描述符等待)释放掉,被内核进行再分配处理,以便被别的进程所使用。传入的status参数决定了这个进程结束时候的状态,这个状态是可以被wait()所捕获的。
另外,exit()是_exit()系统调用的抽象......在fork()之后,通常情况下只有一个父进程的子进程会通过exit()终止掉,其余的进程应该使用_exit() 。” — The Linux Programming Interface
译者:参考 "Linux Programmer's Manual" :
The function _exit() terminates the calling process "immediately". Any open file descriptors belonging to the process are closed; any children of the process are inherited by process 1, init, and the process's parent is sent a SIGCHLD signal.
The value status is returned to the parent process as the process's exit status, and can be collected using one of the wait(2) family of calls.
The function _Exit() is equivalent to _exit().
僵尸进程
父进程和子进程的存活时间一般都不相同:要么父进程活得长要么相反。
那么,如果子进程在父进程还没有调用wait()之前终止了会怎么样?事实是,即使子进程已经终止了,父进程应该还是允许调用wait()查看这个子进程的终止状态。内核通过将子进程变为一个僵尸进程来处理这样的情况。这意味着大多数子进程占用的资源都被释放掉以便系统再分配利用。
事实上,当一个进程终止后,它不会立即从内存中消失——它的进程描述符 (译者注:进程描述符我以后会在另一篇定义进程状态的文章中列出的)还会驻留在内存中(这只会占用很少内存)。进程的状态会变为 EXIT_ZOMBIE 并且通过信号 SIGCHLD 告知其父进程它已经“死亡”了。父进程应该通过调用wait()来读取这个僵尸进程的退出状态和其他信息。在wait()调用之后,这个僵尸进程就会完全从内存中消失掉。
这通常发生的非常快,所以你不会看到僵尸进程在你的电脑上不断增加。然而,如果一个父进程从来不调用wait() ,它产生的僵尸进程就会在程序结束前一直驻留内存。 -来自 what-is-a-zombie-process-on-linux.
// file - zombie.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
//译者注:少了#include <unistd.h>
#define BUF_SIZE 150
int main()
{
int pid = fork();
char buf[BUF_SIZE];
int print_count;
switch (pid)
{
case -1:
perror("fork failed");
exit(1);
case 0:
print_count = 2;
sprintf(buf,"child process: pid = %d", pid);
break;
default:
print_count = 10;
sprintf(buf,"parent process: pid = %d", pid);
break;
}
for(;print_count > 0; print_count--) {
puts(buf);
sleep(1);
}
exit(0);
}
如果你运行以上代码,子进程会在父进程结束前结束,并且会变成一个僵尸进程直到父进程结束。如下所示:
译者注(PID为25351,S为Z,CMD为<defunct>)
$ ./zombie
$ ps -la
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
0 S 601 25350 12377 0 75 0 - 381 - pts/0 00:00:00 zombie
1 Z 601 25351 25350 0 78 0 - 0 exit pts/0 00:00:00 zomb <defunct>
0 R 601 25352 12377 0 77 0 - 1054 - pts/0 00:00:00 ps
以下描述来自于 what-is-a-zombie-process-on-linux.
僵尸进程不会消耗任何系统资源(事实上,每一个僵尸进程只会使用一丁点内存来保存进程描述符)。然而,每一个僵尸进程还是会保留它的PID。Linux在32位系统上有一个固定的PID范围:32767。如果僵尸进程以很快的速度累计——例如,一个编写错误的服务程序,那么很快就将没有剩余的PID可以使用,其他正常的进程也启动不了了。
所以,少部分僵尸进程还是无伤大雅的,虽然在一定程度上反映了其父进程存在一些bug。
如果父进程非正常终止,它的子进程会变成init的子进程。僵尸进程会驻留在内存中直到init将其释放。虽然只是一小段时间,它们也会再释放前占用PID。
我们不能像终止正常进程那样使用 SIGKILL 信号终止一个僵尸进程。对于僵尸进程,UNIX像电影中的那样——它不能被信号终止,甚至是(silver bullet,译者注:银色子弹是指一种鸡尾酒。援引自西方的魔幻故事中驱魔的银色子弹,在魔幻故事中有驱魔效果。) SIGKILL 都不行。事实上,这是一个故意为之的特性,为了确保父进程总是可以最终调用wait() 。记住,我们不需要为一小撮僵尸进程担忧,除非它们快速累计起来了。但是,还是有一些方法拜托僵尸进程的。
其中的一种方法就是像僵尸进程的父进程发送SIGCHLD 信号。这个信号告诉父进程执行wait()然后清除僵尸子进程。可以使用kill命令发送这个信号:(其中的pid是父进程的PID )
kill -s SIGCHLD pid
然而,如果父进程没有正确处理SIGCHLD信号,这就不会有效果。我们必须终止父进程——这些剩下的僵尸子进程的父进程会变成init,而init会定期执行wait() 系统调用去清理僵尸子进程,所以init会使得僵尸进程不那么“嚣张”。
如果父进程持续创造僵尸进程,我们就必须debug它了,让它正确的调用wait()来回收它的僵尸子进程。
僵尸进程并不同于孤儿进程(orphan process)。孤儿进程是指一个持续运行的程序,但是它的父进程已经终止了。它们不是僵尸——它们会被init收养。(译者:哈哈,生动形象)
换句话说,在父进程终止后,对子进程调用getppid() 会得到1(init )。这可以用来判断一个进程的父进程是否已经终止。(假设这个子进程不是一开始就是init创建的)
Signals
信号是一种通知,一种由操作系统或者应用程序发出的消息。信号是一种单向异步通知方法,其可能是由内核传给进程的,也可能是由进程传给进程的,也可能是自己传给自己的。信号一般都是用来告知进程一些事件,例如分段错误或者用户按下了CTRL-C。
Linux内核实现了大概30种信号,每一种信号都标记为一个整数,从1到31.信号不会有任何参数,它们自己的名字也大概解释了它们的含义。例如SIGKILL 或者9号信号告诉程序有人想要杀死它, SIGHUP体现出发生了一个终端上的挂起操作,它在i386架构上是1号信号。
除了SIGKILL 和 SIGSTOP 总是终止或者停止进程,进程可以控制如何处理它们收到的信号。它们可以:
- 接受信号默认的操作,例如终止进程、终止并coredump、停止进程、什么都不做等等。
- 或者,进程可以选择忽略或者处理信号。
- 默默丢弃信号。
- 程序收到信号后跳到用户实现的信号处理模块,处理完成后控制重新回到之前被打断的地方并继续执行程序。
| Signal | Name | Description |
|---|---|---|
| SIGHUP | 1 | Hangup (POSIX) |
| SIGINT | 2 | Terminal interrupt (ANSI) |
| SIGQUIT | 3 | Terminal quit (POSIX) |
| SIGILL | 4 | Illegal instruction (ANSI) |
| SIGTRAP | 5 | Trace trap (POSIX) |
| SIGIOT | 6 | IOT Trap (4.2 BSD) |
| SIGBUS | 7 | BUS error (4.2 BSD) |
| SIGFPE | 8 | Floating point exception (ANSI) |
| SIGKILL | 9 | Kill(can't be caught or ignored) (POSIX) |
| SIGUSR1 | 10 | User defined signal 1 (POSIX) |
| SIGSEGV | 11 | Invalid memory segment access (ANSI) |
| SIGUSR2 | 12 | User defined signal 2 (POSIX) |
| SIGPIPE | 13 | Write on a pipe with no reader, Broken pipe (POSIX) |
| SIGALRM | 14 | Alarm clock (POSIX) |
| SIGTERM | 15 | Termination (ANSI) |
| SIGSTKFLT | 16 | Stack fault |
| SIGCHLD | 17 | Child process has stopped or exited, changed (POSIX) |
| SIGCONTv | 18 | Continue executing, if stopped (POSIX) |
| SIGSTOP | 19 | Stop executing(can't be caught or ignored) (POSIX) |
| SIGTSTP | 20 | Terminal stop signal (POSIX) |
| SIGTTIN | 21 | Background process trying to read, from TTY (POSIX) |
| SIGTTOU | 22 | Background process trying to write, to TTY (POSIX) |
| SIGURG | 23 | Urgent condition on socket (4.2 BSD) |
| SIGXCPU | 24 | CPU limit exceeded (4.2 BSD) |
| SIGXFSZ | 25 | File size limit exceeded (4.2 BSD) |
| SIGVTALRM | 26 | Virtual alarm clock (4.2 BSD) |
| SIGPROF | 27 | Profiling alarm clock (4.2 BSD) |
| SIGWINCH | 28 | Window size change (4.3 BSD, Sun) |
| SIGIO | 29 | I/O now possible (4.2 BSD) |
| SIGPWR | 30 | Power failure restart (System V) |
术语产生(raise)代表信号的生成,术语捕获(catch)代表信号的接受。
信号是由错误的条件引发的,它们可能是由shell和终端的处理程序发出的终端指令,也可能是由一个进程向另一个进程传送的修改行为的指令。
信号可以被:
- 产生
- 捕获
- 采取行动
- 忽略
如果一个进程收到了像 SIGFPE, SIGKILL, 这样的信号,进程会立即终止,并且会创建一个 core dump文件,这个文件是该进程的内存镜像,我们可以利用它进行debug。
举个常见的栗子,当我们输出 interrupt character 的时候(即Ctrl+C),ISGINT 信号就会被送给前台程序 (即目前正在运行的程序)。这会使得程序终止,除非它有捕获该信号的安排。
kill命令可以用来给进程发送信号。例如我们想要给PID为pid_number发送 hangup信号:
kill -HUP pid_number
kill命令有一个好用的变体killall ,它可以向所有运行了一个命令的进程发送同一个信号。例如,我们给所有运行了 inetd的进程发送一个 reread信号:
$ killall -HUP inetd
上面这个命令可以使得inetd程序重新读取他的配置文件。
在下面这个例子中,程序会对Ctrl+C做出反应而不是终止前台程序。但是如果我们再次输入Ctrl+C的话,它就会终止:
译者注:(关于signal这个函数)
SYNOPSIS
#include <signal.h>
typedef void (*sighandler_t)(int);
sighandler_t signal(int signum, sighandler_t handler);
DESCRIPTION
The behavior of signal() varies across UNIX versions, and has also varied historically across different versions of Linux. Avoid its use: use sigaction(2) instead. See Portability below.
signal() sets the disposition of the signal signum to handler, which is either SIG_IGN,SIG_DFL, or the address of a programmer-defined function (a "signal handler").
If the signal signum is delivered to the process, then one of the following happens:
* If the disposition is set to SIG_IGN, then the signal is ignored.
* If the disposition is set to SIG_DFL, then the default action associated with the signal(see signal(7)) occurs.
* If the disposition is set to a function, then first either the disposition is reset to SIG_DFL, or the signal is blocked (see Portability below), and then handler is called with argument signum. If invocation of the handler caused the signal to be blocked, then the signal is unblocked upon return from the handler.
The signals SIGKILL and SIGSTOP cannot be caught or ignored.
程序:
#include <stdio.h>
#include <unistd.h>
#include <signal.h>
void my_signal_interrupt(int sig)
{
printf("I got signal %d
", sig);
(void) signal(SIGINT, SIG_DFL);
}
int main()
{
(void) signal(SIGINT,my_signal_interrupt);
while(1) {
printf("Waiting for interruption...
");
sleep(1);
}
}
输出如下:
Waiting for interruption...
Waiting for interruption...
Waiting for interruption...
Waiting for interruption...
Waiting for interruption...
Waiting for interruption...
I got signal 2
Waiting for interruption...
Waiting for interruption...
Waiting for interruption...
Waiting for interruption...
Waiting for interruption...
Waiting for interruption...
Waiting for interruption...
Waiting for interruption...
Waiting for interruption...
当我们按下Ctrl+C的时候SIGINT信号被传入进该进程,由于我们设置了由my_signal_interrupt()处理这个信号,程序不会终止,而是进入my_signal_interrupt() ,在my_signal_interrupt() 中,我们打印出“I got signal %d
”,并将对 SIGINT的处理重新变为信号默认的动作,所以第二次传入 SIGINT信号时,程序就会执行终止操作。