一,程序的功能和适用人群
程序的功能是爬取豆瓣用户标记的想读或者读过的的图书,将图书信息保存为excel文件。适用于想备份在豆瓣上标记的图书的用户。
二,执行效果
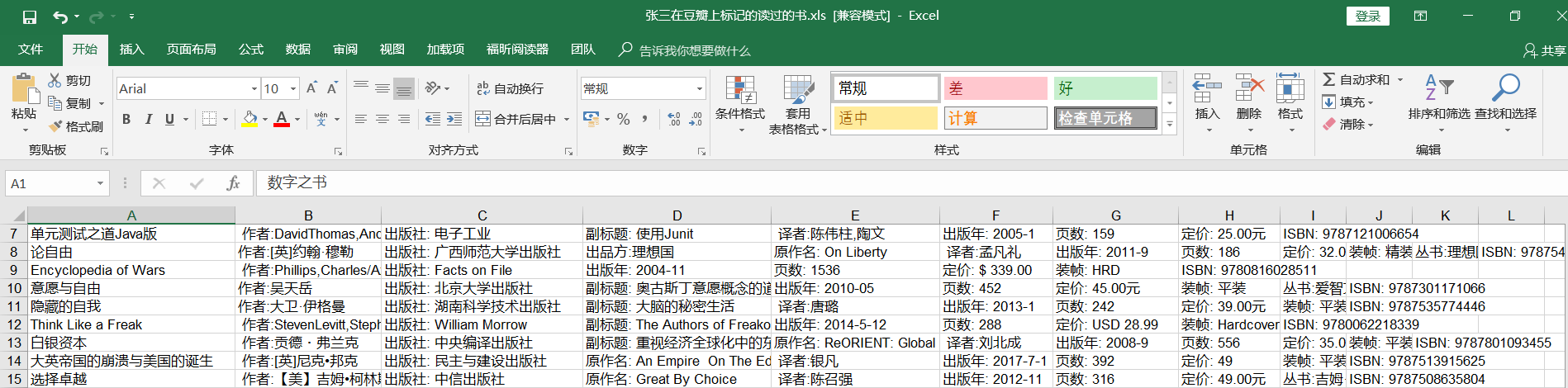
程序执行后会得到一个excel文件,保存了用户想要读的或者读过的图书信息,如下图:
三,技术路线
技术路线是选取用户在豆瓣上标记的想读的或者读过的图书的首页url作为种子url,如下图
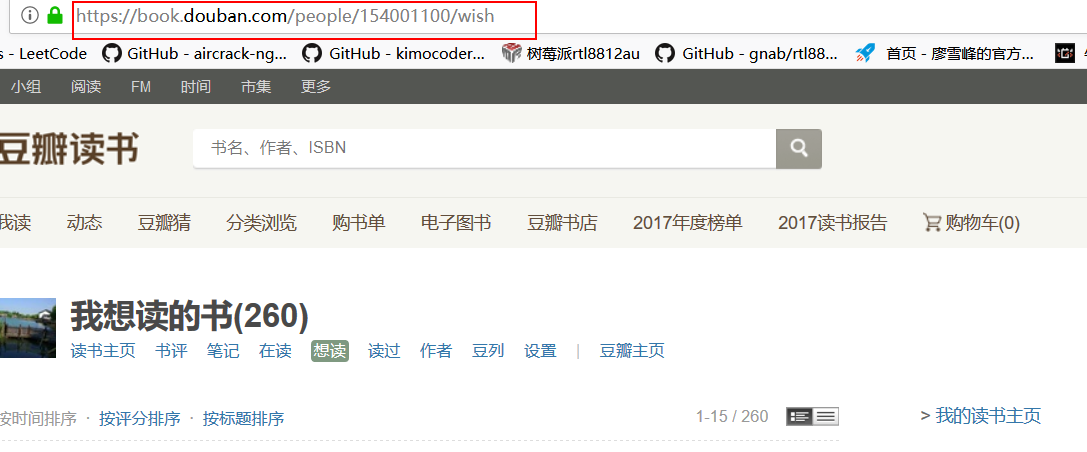
遍历这一页中所有的图书信息,通过每本图书链接抓取每本图书的具体信息,以下左图是首页的图书信息,右图是通过左图的链接进入的要爬取的具体的图书信息。


在爬取首页的url中的所有图书时,判断是否还有下一页,如果有,则爬取下一页的图书信息,直至没有要爬取的下一页图书信息。
四,发布方式和下载链接
源代码发布在github上,地址:https://github.com/041240515lq/python_spider/blob/master/spiderBook.py
程序编译成exe发布,exe程序下载地址 https://download.csdn.net/download/u014223772/10469357
五,未来的发展
未来准备爬取某个用户和他所关注的人的共同想读的书和共同读过的书。但需要控制规模,比如A关注了B,B关注了C,爬取A,B,C三者的共同读过的书。