Hibernate核心:ORM(对象关系映射)
BeginSession关闭的时候要session.close(),而getCurrentsession不需要,它会自动关闭
Session.load(类.Class,id)方法和session.get(类.Class,id)方法
三种状态:
瞬时态:刚用new创建出来,还没有用到,存在于session缓存中
持久态:将数据存入到了(比如:数据库中,硬盘中),数据永久存在,并被session管理
脱管态:存在于数据库中,但没有被session管理
快照区: 临时存储持久化对象的副本。
在快照区中通过session.flush()强制刷新,将数据传到数据库中
Hibernate相关文件的配置:
- 1. hibernate.cfg.xml:包含hibernate和数据库的基本连接信息

2.XXX.hbm.xml映射文件配置
双向一对多配置:以一的一方作为对象把多的一方的对象存进来
两个类:区域类(一)和街道类(多)
区域:

街道类:

文件配置:
通用头文件:

区域配置:

街道配置:

测试类:

单项多对一配置:多的一方中当做对象存进一的一方的对象
区域类(一):

街道类(多):

区域配置:

街道配置:

测试类:

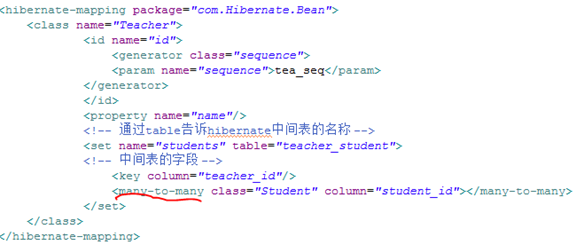
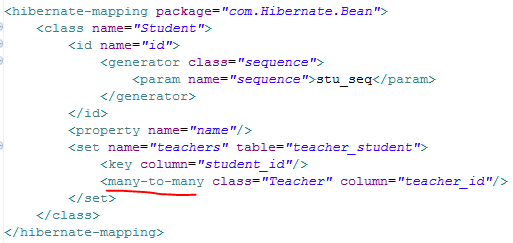
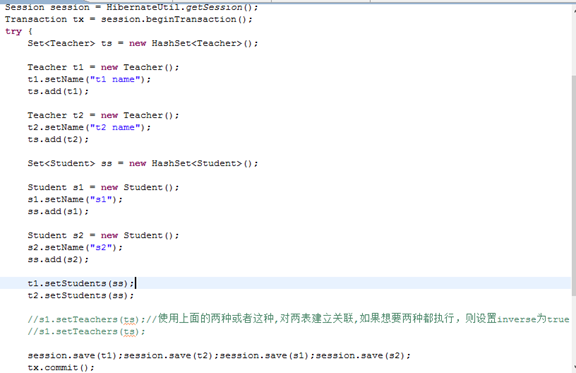
多对多配置:互相添加
老师类和学生类,在多对多中要借用中间表
数据库设计:
老师:teacher


学生:student


中间表:teacher_student


老师类:

学生类

老师配置:
学生配置:
测试类:
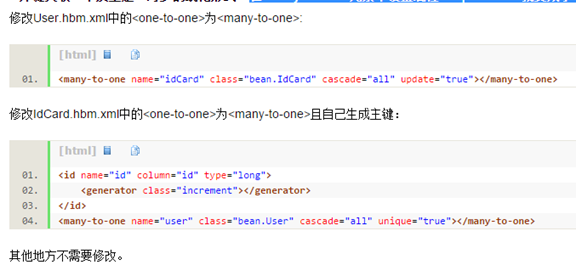
双向一对一配置:相互添加
用户类:

身份证类:

主键关联即其中一个表的主键参照另外一张表的主键而建立起一对一关联关系的配置:
用户配置:

身份证配置:

测试类:
外键关联:在<many-to-one>元素中设置属性unique=”true”就变成了一对一
Cascade级联:
All:所有操作进行级联删除
Save-update:执行保存和更改的操作时进行级联
Delete:执行删除操作进行级联
None:对所有操作不进行级联
Inverse:控制反转(是否维护关联关系或者说是是否把权力交给另一方)
True:是(放弃),由被动方来维护关联关系,比如:主动方要进行删除操作,被动方就不会跟着进行删除操作
False:否,由主动方来维护关联关系,比如:主动方要进行删除操作,被动方就会跟着进行删除操作
查询:
HQL查询:注意,查询中查询的不是数据库表名,而是pojo的类名
- 单一属性查询,返回String类型
session.createQuery("select name from Student").list();
- 多个属性查询,返回数据对象类型,对象数组的长度取决于属性的个数
session.createQuery("select id, name from Student").list();
- 实体对象查询,返回对象
session.createQuery("from Student").list();
几种参数:
(1)“?”占位符参数,注意下标从0开始
(2)“:name”命名参数
命名查询:在任何一个映射文件中加入都行,最好是在要查询的这一端配置
<hibernate-mapping>
<class name="com.msit.houserent.bean.User" table="users">
<!--省略其他配置-->
</class>
<query name="loginUser">
<![CDATA[
from User u where u.name =:name and u.password =:password
]]>
</query>
</hibernate-mapping>
注意:是在<class>标签外,name是名字,随意取名,查询的时候就直接通过sesison.getNameQuery(name)方法进行查询
本地sql查询(最原始的sql语句查询):session.createSQLQuery()方法返回SQLQuery对象
- 通过命名查询实现本地SQL查询
- 使用<sql-query>元素定义本地SQL 查询语句
- 与<class>元素并列
- 以<![CDATA[SQL]]>方式保存SQL 语句通过Session 对象的getNamedQuery()方法获取该查询语句
Criteria查询(对象查询):
- 查询方式:session.createCriteria(类.Class).list()
- 普通条件查询:Criteria.add(Restrictions.方法())
几种模糊查询:

- 排序查询:Criteria.addOrder(Order.方法())
- 统计查询:Criteria.setProjection(Projections.方法())
- 分组查询:Criteria.setProjection(Projections.groupPerporty())
- 结合统计和分组查询:
ProjectionList projectionList = Projections.projectionList();
projectionList.add(Projections.groupProperty("age"));想·
projectionList.add(Projections.rowCount());
Criteria.setProjection(projectionList);
- 针对实体类查询:Criteria.add(Example.create(对象))
在查询的时候对对象的属性进行赋值,查询出来的结果就是符合这些属性的结果
工具javaBean是专门用于操作的一个Bean类,通过setProperties(Object Bean)
- 当需要查询多个属性时,我们可以封装出一个专门用于操作的Bean来,类似于对象查询中的Example查询
就是从表单传入值时,把值放置Bean中,这样有些属性有值,有些属性没值,然后调用setProperties()方法进行查询,根据有的属性进行查询(符合这些属性的),将查询结果返回。这样根据不同个数的属性,查询出来的结果也就不一样
- 在Dao层中这样使用。

List查询和iterator查询的区别:
- list查询返回的是一条sql语句
- iterator返回的是n+1条语句,1是指查出来的id,n是指根据id查出来的结果
- 从缓存机制中看:
get和load的区别:
- get是立即加载
- load是延迟加载,先根据id把查出来的结果放在内存中,当想要调用哪个查询结果时,就从缓存中调出来
openSession和getCurrentsession的区别:
- getCurrentsession是获取上下文的一个对象,并且连续使用多次,获得的都是同一个对象,会自动执行session.close()方法
2.openSession是连续使用多次,获得的都不是同一个对象,要显示调用session.close()
Hibernate的优化:
- 对数据库的设计:一般在数据表中空留出5个空字段,当发现需要再添加某个字段的时候,就能在这5个空字段中增加
- HQL的优化:避免包含or(可以用in代替),not(可以用比较运算符代替),like,having,distinct关键字
- 配置参数:
- 方法使用:
- 缓存管理:
缓存机制:
一级缓存:针对对象查询
- 在同一个session中发出两次load(get)查询,第二次不会再发出查询语句,load使用缓存
- 在同一个session中发出两次iterator查询普通属性,会再次发出查询语句,因为一级缓存不会缓存属性
- 在两个session中法load查询,会再次发出查询语句session之间不能共享一级缓存
- 在同一个session中先调用save,在调用load查询刚刚save的数据,不会再次发出查询语句,因为save支持缓存
- 当有大批量数据时,我们可以指定在多少条数据的时候进行强制刷新(flush)到数据库中

二级缓存:针对对象查询
二级缓存的配置:
*添加架包ehcache-1.2.3.jar和commons-logging-1.1.1.jar
* 将ehcache.xml文件拷贝到src下
*在hibernate.cfg.xml中配置:

- 开启二级缓存,在两个session中法load(get)查询,返回一条sql语句,因为二级缓存可共享
- 在二级缓存中调用evict()方法:

此方法写在两个session中间,不是开头处
3.禁止将一级缓存中的数据放到二级缓存中

此方法放在第一个session开头处
查询缓存:针对查询出来的结果进行缓存
查询缓存的配置:
在hibernate.cfg.xml中配置:

1.开启查询缓存,关闭二级缓存,用list()方法查询普通属性,在两个session中将只返回一条sql语句,因为查询缓存可以针对属性
2. 开启查询缓存,关闭二级缓存,用iterator()方法查询普通属性,在两个session中发iterator查询,将返回2条sql语句,因为查询缓存只对list()方法有效果
3.开启查询缓存,关闭二级缓存,用list()方法查询实体,在两个session中查询,会发出n条语句,查询缓存会缓存实体对象的id,第二次执行将查询缓存中id依次取出来,分别到一级和二级缓存中去查询相对应的实体对象,如果存在就使用缓存中的实体对象,否则就根据id发出查询语句
4.开启查询缓存,开启二级缓存,list()方法在两个session中,第二次执行不会再发出sql句,因为开启了二级缓存
锁机制:
- 悲观锁:在load(get)查询中的第三个参数设置成lockmode.force,注意:使用悲观锁时,每个load都要加入此参数。含义:当第一个在执行此操作的时候,第二个操作者必须等第一个操作者执行完才执行
- 乐观锁
配置:在数据表中加入version这一字段,然后在Bean中也加上,最后在映射文件中加入<version name=””>这一个。含义:当第一个操作者在操作时,第二个操作者也可以操作,就看谁先完成,谁就成功,当成功后,另一个操作者就会报异常

各个jar包的含义:
1.antlr-2.7.6.jar的作用
项目中如果没有添加antlr-2.7.6.jar,那么相关的hibernate映射不会执行hql语句
并且会报NoClassDefFoundError:antlr/ANTLRException错误。
- hibernate3.jar:Hibernate的核心库
- dom4j.jar: dom4j是一个Java的XML API,类似于jdom,用来读写XML文件的。
- commons-collections.jar:包含了一些Apache开发的集合类,功能比java.util.*强大
- jta.jar:JTA规范,当Hibernate使用JTA的时候需要,不过App Server都会带上, 标准的 JAVA 事务处理接口
- ehcache-1.1.jar :缓存工具,用于hibernate二级缓存中的.
6.Javassist.jar: 动态编译,动态生成二进制字节码(.class)动态创建新类或新接口的二进制字节码, 动态扩展现有类或接口的二进制字节码 7.ojdbc14.jar:用于连接oracle数据库的jar包
8. commons-logging-1.0.4.jar Apache 软件基我组所提供的日志工具
问题
1.no-session问题;
解决方法一:在映射文件中,将要调用的那一方的lazy属性设为false
解决方法二:在读取想要调用的属性时,可以先拿出来
2.在多对一中如何获取一这边的值:
如果用的是el表达式的话:
多:private Users users;
一:private Set<House> houses;
private String telephone;
那么可通过${session名.users.telephone;}
注意:在dao层获得值的时候必须
List<House> hList = session.createQuery("from House h").setFirstResult((currentpage-1)*pageSize).setMaxResults(currentpage*pageSize).list();
for(House house : hList){
String telephone=house.getUsers().getTelephone();
houses.add(house);
}
必须重新写telephone,否侧会报:
Error reading 'telephone' on type com.Hibernate.Bean.Users_$$_javassist_1错误
注意2:
在查询语句中,在多对一的情况下,想根据一的一方的属性去查询多的一方的值,可以直接用对象.属性来查询
如:
多:House
private Street street;
一:Street
Private int id;
from House where street.id=?
- 3. insert fail: filed depid doesnot have default value:depid为空
- 4. myeclipse中没有报错,但是就是数据库中楞写不进去数据,这是原因呢?
原因一:你忘记把映射文件加入到hibernate.cfg.xml文件中了
原因二:映射文件配置错了