一、统计方法和字符串离散化
假设现在我们有一组从2006年1000部最流行的电影数据,我们想知道这些电影数据中的评分的平均分,导演的人数等信息,我们应该怎么获取?
数据来源:https://www.kaggle.com/damianpanek/sunday-eda/data
import pandas as pd from matplotlib import pyplot as plt file_path = "./IMDB-Movie-Data.csv" df = pd.read_csv(file_path) print(df.info()) print(df.head()) #获取平均评分 print(df["Rating"].mean()) #获取导演的人数 print(len(set(df["Director"].tolist()))) #print(len(df["Director"].unique())) #获取演员的人数 temp_actors_list = df["Actors"].str.split(", ").tolist() actor_list = [i for j in temp_actors_list for i in j] actor_num = len(set(actor_list)) print(actor_num)
获取电影时长最大值,最小值。

对于这一组电影数据,如果我们想要Rating,runtime的分布情况,应该如何呈现数据?
获取runtime分布情况:
import pandas as pd from matplotlib import pyplot as plt file_path = "./IMDB-Movie-Data.csv" df = pd.read_csv(file_path) print(df.head(1)) print(df.info()) #rating runtime分布情况 #选择图形 直方图 #准备数据 runtime_data = df["Runtime (Minutes)"].values max_runtime = runtime_data.max() min_runtime = runtime_data.min() num_bin = (max_runtime-min_runtime)//5 #设置图形的大小 plt.figure(figsize=(20,8),dpi=80) plt.hist(runtime_data,num_bin) plt.xticks(range(min_runtime,max_runtime+5,5)) plt.show()

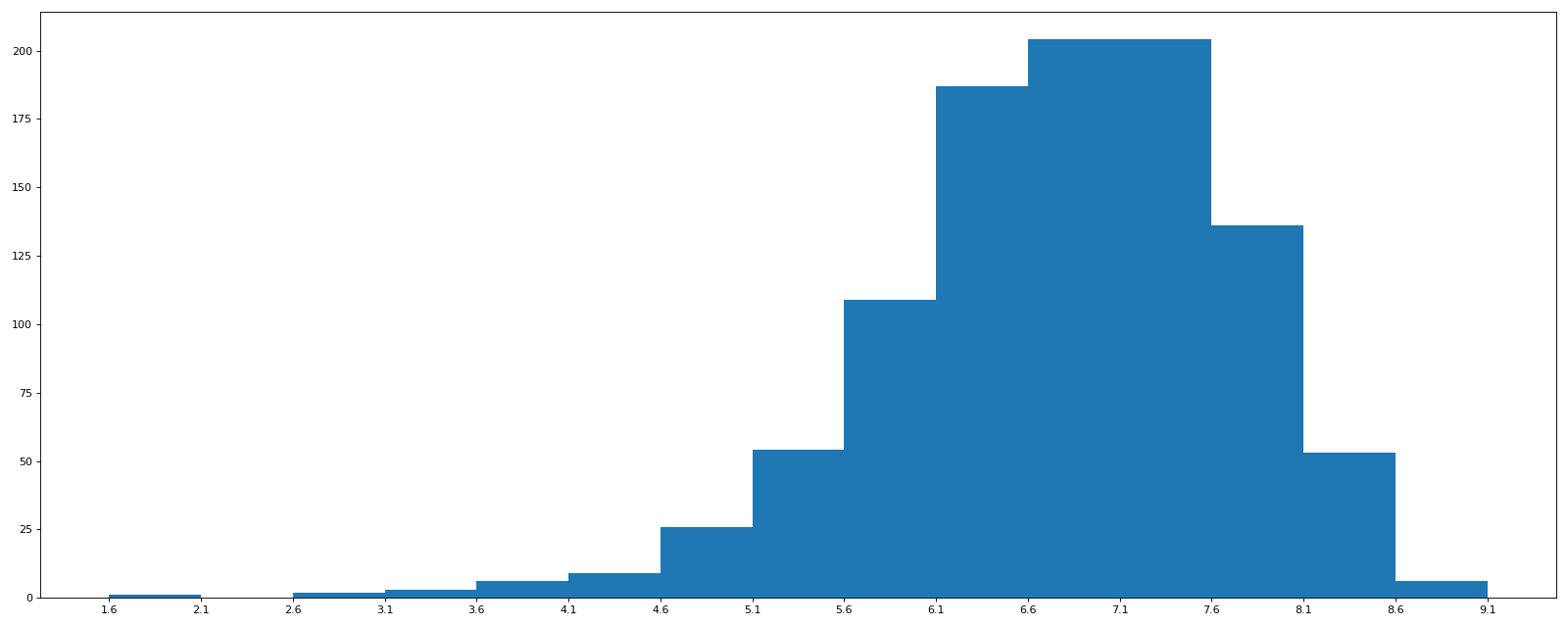
获取Rating情况:
import pandas as pd from matplotlib import pyplot as plt file_path = "./IMDB-Movie-Data.csv" df = pd.read_csv(file_path) print(df.head(1)) print(df.info()) #rating runtime分布情况 #选择图形 直方图 #准备数据 runtime_data = df["Rating"].values max_runtime = runtime_data.max() min_runtime = runtime_data.min() print(min_runtime,max_runtime) print(max_runtime-min_runtime) num_bin_list = [1.6] i = 1.6 for m in range(15): i += 0.5 num_bin_list.append(i) print(num_bin_list) #设置图形的大小 plt.figure(figsize=(20,8),dpi=80) plt.hist(runtime_data,num_bin_list) plt.xticks(num_bin_list) plt.show()