1.体系结构、源码编译
HDFS+MapReduce。共同点都是都是分布式的,主从关系结构。
HDFS是暴扣主节点NameNode,只有一个;还有从节点DataNode,有很多个。
NameNode含有我们用户存储的文件的元数据信息。把这些数据存放在硬盘上,但是在运行时是加载在内存中的。
缺点:
(1)当我们的NameNode无法在内存中加载全部元数据信息的时候,集群的寿命到头了。
(2)权限设计是不够彻底的。
(3)block 64MB,大量小文件的存储的话,会造成NameNode的内存压力剧增。
改进:
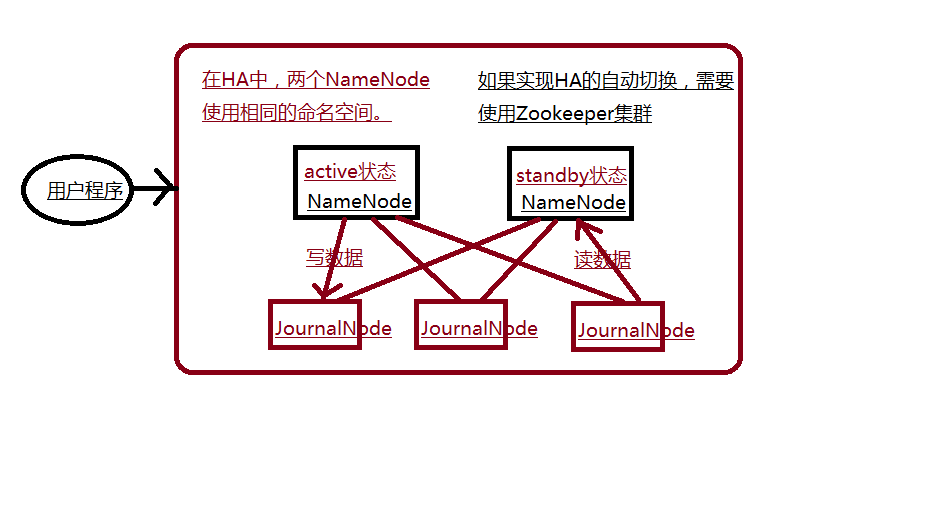
(1)2个NameNode一起共存,组成hdfs federation(联邦)
(2)HA 自动、手工
HDFS的HA(高可靠)
MapReduce包括主节点JobTracker,只有一个;还有从节点TaskTracker,有很多个。
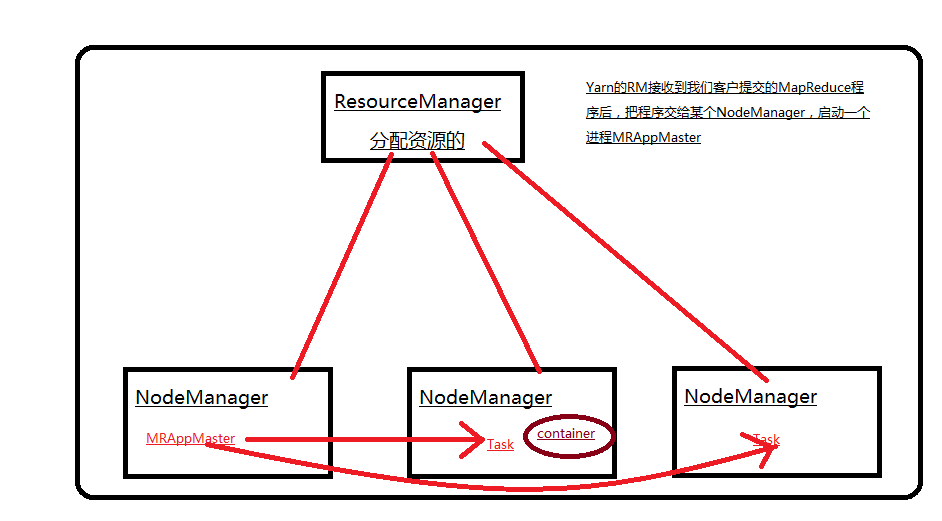
JobTracker主要的工作是管理用户提交的作业和分配资源。
slot
缺点:
(1)对于实时性作业和批处理作业,需要搭建不同的集群环境,每个集群的资源利用率不高。
(2)MapReduce职责过多,需要分解。
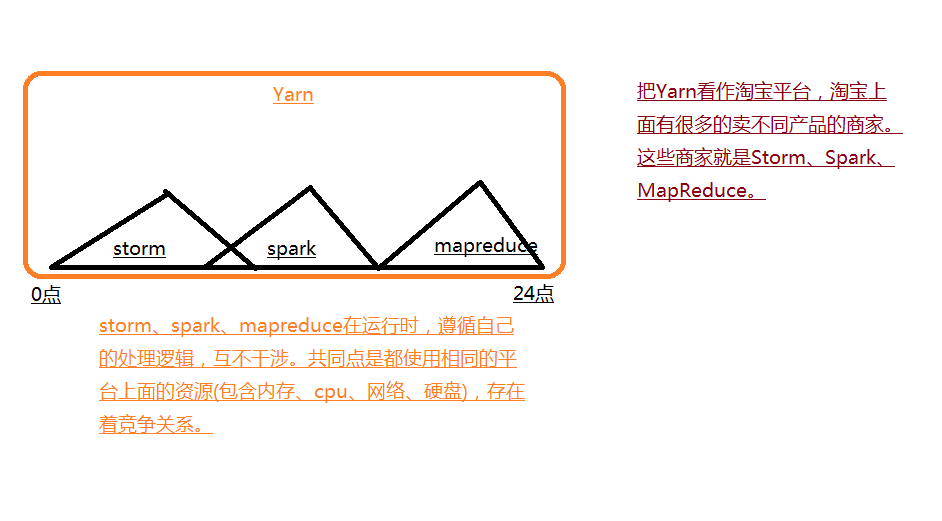
Yarn是一个平台,用于处理资源分配和运行任务的。
2.HDFS部署安装
3.Yarn
{kind=link}
{kind=link}
{kind=link}