龙君蛋君
2015年5月24日
1.背景介绍
最近公司在用R 建模,老板要求用shiny 展示结果,建模的过程中用到诸如kmean聚类,时间序列分析等方法。由于之前看过一篇讨论kmenas聚类针对某一特定数据类型,聚类结果非常不靠谱的文章,于是这个周末突发奇想,用shiny可交互的展示kmeans聚类中的坑。。。这篇博文就当是记录学习shiny和加深对kmeans、层次聚类的理解吧。
2.知识引用与学习
2)Shiny Gallery-This gallery contains useful examples to learn from
3.代码与图形展示
一个完整的shiny app 包含两个.R文件,ui.R和server.R。园主大人的这篇文章Shiny的架构浅析解释的很详细,可帮助理解shiny。
part 1 : ui.R
library(shiny)
library(dplyr)
library(broom)
shinyUI(
pageWithSidebar(
# Application title
headerPanel("kmeans VS hclust"),
sidebarPanel(
numericInput('n', 'Number of obs', 500 ,min=200 ,max=1000),
selectInput("type", "Select a clust approach:",c("kmeans","hclust"),"kmeans")
),
mainPanel(plotOutput("plot"))
)
)
part 2 : server.R
library(shiny)
library(dplyr)
library(broom)
shinyServer(function(input, output,session) {
#----data 1 for kmeans clust----
set.seed(500)
selectedData <- reactive({
rbind(
data_frame(x = rnorm(input$n), y = rnorm(input$n)),
data_frame(r = rnorm(input$n, 5, .25), theta = runif(input$n, 0, 2 * pi),
x = r * cos(theta), y = r * sin(theta)) %>%
dplyr::select(x, y)
)
})
#----data2 for hclust use----
selectedData_clust <- reactive({
cbind(selectedData(),hclust_assignments=selectedData() %>%
dist() %>% hclust(method = "single") %>%
cutree(2) %>% factor()%>%as.data.frame()
)
})
#-----plot-----
output$plot <- renderPlot({
switch(input$type,
"kmeans" =( plot(selectedData(),
col = kmeans(selectedData(),2)$cluster,
pch = 20, cex = 1)
),
"hclust" = (plot(selectedData_clust()[,1:2],
col = selectedData_clust()[,3],
pch = 20, cex = 1)
)
)
})
#----end---
})
先解释下,用k-means进行聚类,常常假定数据是球状的,code中生成的数据集是非球状的,以便证明kmeans针对这种非球状数据集,会给出坑爹的结果。参考大数据分析之——k-means聚类中的坑。
part 3 :看图,也就是shiny的展示。
图1-kmeans聚类:
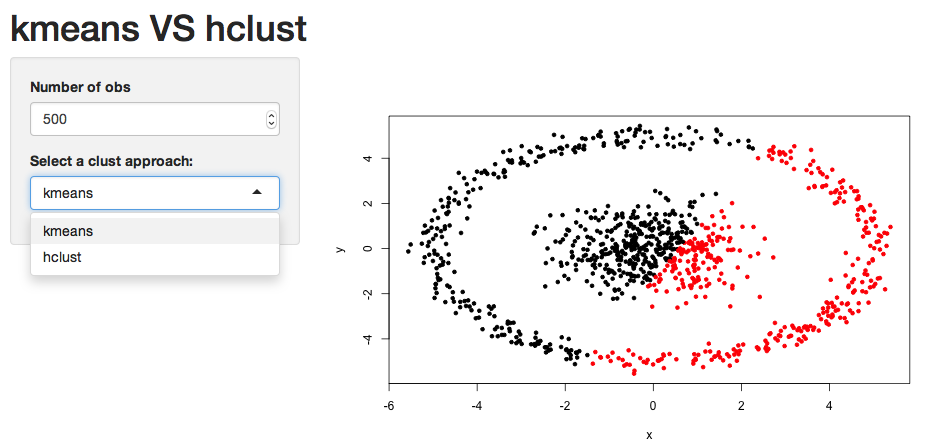
图2-hclust聚类(Hierarchical Clustering):

明显这种数据集,用层次聚类得出的结果才是正确的。
4.总结
1)要勤写博客,不能太懒!
2)Shiny Gallery-This gallery contains useful examples to learn from 这里有很多shiny 的例子,学习shiny的绝佳之地。
3)再推荐一个博客,r-bloggers 最前沿的R资讯分享,hadley都在上面写文章的哦!
4)Rstudio 真是个伟大的公司,开发了那么多好用,好玩的东西。
以上。