1.Partner link:
Partner: 黄毓明 点我
Github:点我
2.Division of labor:
丁水源:
字符统计;行数统计;单词统计;(不同于个人项目的做法。)主函数接口整合。
黄毓明:
单词及词组词频统计;附加题;爬取;
3.PSP Table:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 100 | 100 |
| · Estimate | · 估计这个任务需要多少时间 | 100 | 100 |
| Development | 开发 | 1260 | 1460 |
| · Analysis | · 需求分析 (包括学习新技术) | 300 | 350 |
| · Design Spec | · 生成设计文档 | 60 | 70 |
| · Design Review | · 设计复审 | 80 | 100 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 60 | 80 |
| · Design | · 具体设计 | 240 | 260 |
| · Coding | · 具体编码 | 380 | 420 |
| · Code Review | · 代码复审 | 60 | 80 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 80 | 100 |
| Reporting | 报告 | 170 | 200 |
| · Test Repor | · 测试报告 | 100 | 120 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 40 | 50 |
| 合计 | 1530 | 1760 |
4.Key Code & its Explanation:
爬取:
运行环境Windows 10 64 bit专业版
IDE:Anaconda3(64 bit)
我们选择用Python来完成网页信息爬取,主要思路是先解析出CVPR2018的网址结构,然后用select()通过类名'.ptitle'筛选出title对应元素,再遍历select()返回的list,筛选出href,得到相对网址,对所得到的网址进行内容爬取,也是利用select()进行筛选,将得到的Title与Abstract按指定格式写入result.txt
爬取部分截图:
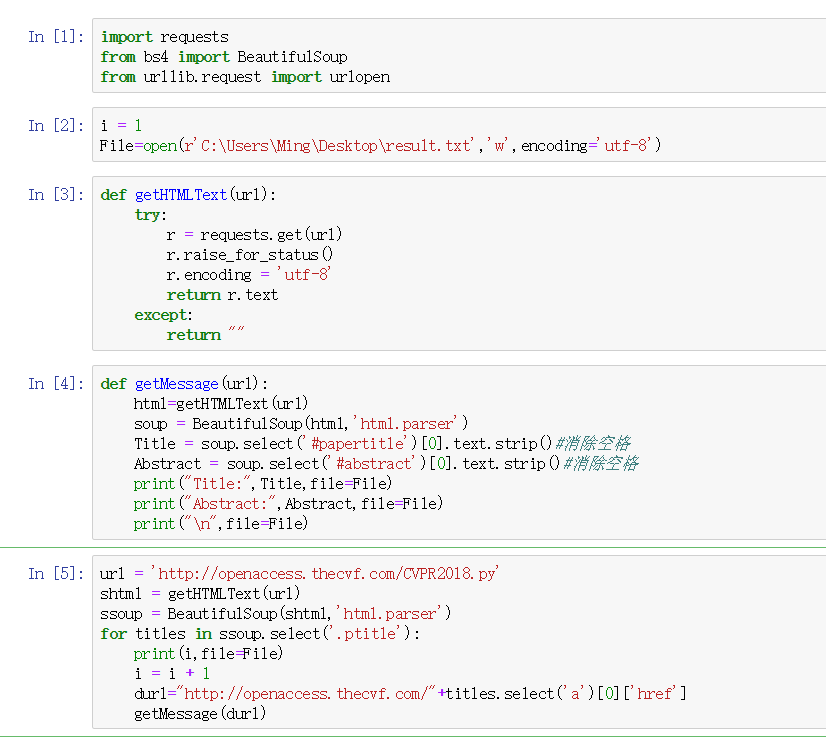

主要代码组织及其框架:
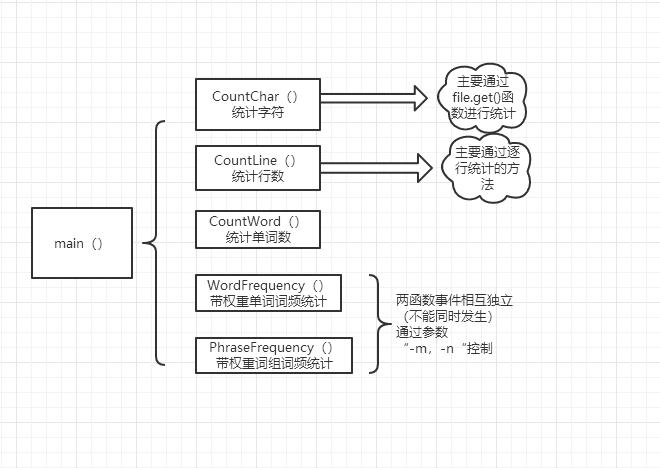
关键函数代码内部主要组织思想流程图:
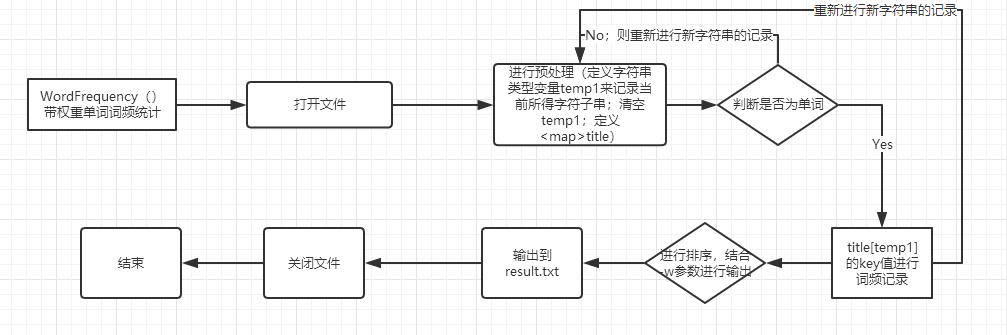
(WordFrequency() :带权重单词词频统计)
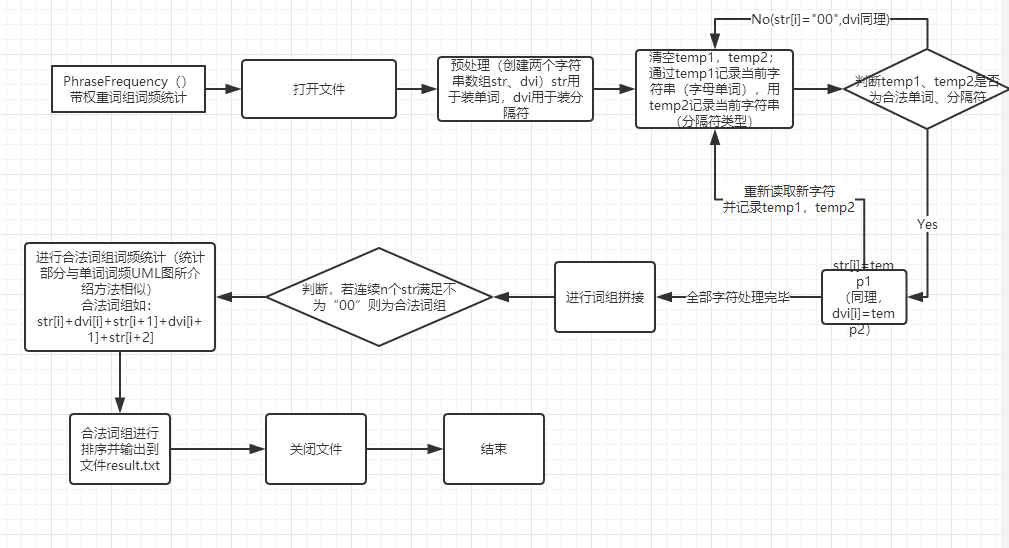
(PhraseFrequency() 带权重的词组词频统计)
main():整体内部函数框架及其命令行随机出现的实现:
#include<iostream>
#include<string>
#include<fstream>
#include"init.h"
#include"CountChar.h"
#include"CountLine.h"
#include"CountWord.h"
#include"WordFrequency.h"
#include"PhraseFrequency.h"
using namespace std;
int main(int argc,char **argv) {
int flag_m = -1, flag_n = -1,flag_i=-1,flag_o=-1,flag_w=-1;
int m = 0, n = 0,judgevalue = 0;
string input;
string output;
string buffer[20];
// 预先处理命令行传入参数: 用flag_x 进行记录:
for (int i = 0; i < argc; i++) {
buffer[i] = argv[i];
if (buffer[i] == "-i") {
flag_i = i;
input = argv[i + 1];
}
else if (buffer[i] == "-o") {
flag_o = i;
output = argv[i + 1];
}
else if (buffer[i] == "-w") {
flag_w = i;
if (argv[flag_w + 1] == "0") judgevalue = 0;
if (argv[flag_w + 1] == "1") judgevalue = 1;
}
else if (buffer[i] == "-m") {
flag_m = i;
m = atoi(argv[flag_m + 1 ]) ;
}
else if (buffer[i] == "-n") {
flag_n = i;
n = atoi(argv[flag_n + 1]) ;
}
}
// 初始化各个函数的输出;并赋值;
int cnt_char=CountChar(argv[flag_i + 1]);
int cnt_line=CountLine(argv[flag_i + 1]);
int cnt_word=CountWord(argv[flag_i + 1]);
//将部分结果先输出到result.txt文档
ofstream fout(output, ios::app);
fout << "characters: " << cnt_char << endl;
fout << "words: " << cnt_word << endl;
fout << "lines: " << cnt_line << endl;
fout.close();
//单词词组词频的统计分类(共分为4类) 如下所示;
if (flag_n == -1 && flag_m == -1) { //未出现 - n 参数时,不启用自定义词频统计输出功能,默认输出10个
int jj = 10;
int a = WordFrequency(input,output, judgevalue, jj);
}
if (flag_n != -1 && flag_m == -1) { //未出现 - m 参数时,不启用词组词频统计功能,默认对单词进行词频统计
int jj = n;
WordFrequency(input,output, judgevalue, jj);
}
if (flag_n != -1 && flag_m !=-1) {
int jj = 10;
PhraseFrequency(input, output,m,judgevalue,10 );
}
if (flag_n == -1 && flag_m != -1) {
PhraseFrequency(input, output, m, judgevalue,n);
}
//结束:
return 0;
}
通过如上代码注释,可以比较清晰的看出,本次作业我们所组织的整体内部函数结构。分块清晰明确。各个功能分块合理明确。
WordFrequency() :带权重的词频统计代码解释;
int WordFrequency(string filename_in,string filename_out,int judgevalue,int jj)
{
//int judgevalue = 0;
//cin >> judgevalue; ////111111
int i;
//int paperCount = 4;//论文数 //1111
int cnt1 = 0, n = 0;
string temp11;
int flag = 0;
//fstream fin("result.txt", ios::in);//输入文件
// ofstream fout("result2.txt", ios::app);//输出文件
fstream fin(filename_in, ios::in);//输入文件
ofstream fout(filename_out, ios::out);//输出文件
if (!fin) {
cout << "Can't open file" << endl;
return -1;
}
map<string, int> title;
int wordvalue = 0;
char temp;
string temp1;
map<string, int>::iterator iter;
for (; ; )
{
flag = 0;
while (fin.get() != '
');//读完论文标号行
while (fin.get() != ':');// 读完Title:
while ((temp = fin.get()) != '
')//读完Title:以后的内容
{
if ('A' <= temp && temp <= 'Z')
temp = temp + 32; //转换成小写;
switch (wordvalue) {
case 0: {
if (temp >= 'a'&&temp <= 'z') {
temp1 = temp1 + temp;
wordvalue = 1;
}
break;
}
case 1: {
if (temp >= 'a'&&temp <= 'z')
{
temp1 = temp1 + temp;
wordvalue = 2;
}
else { wordvalue = 0; temp1 = ""; }
break;
}
case 2: {
if (temp >= 'a'&&temp <= 'z')
{
temp1 = temp1 + temp;
wordvalue = 3;
}
else { wordvalue = 0; temp1 = ""; }
break;
}
case 3: {
if (temp >= 'a'&&temp <= 'z')
{
temp1 = temp1 + temp;
wordvalue = 4;
}
else { wordvalue = 0; temp1 = ""; }
break;
}
case 4: {
if (temp >= 'a'&&temp <= 'z' || (temp >= '0'&&temp <= '9')) { temp1 = temp1 + temp; }
else {
title[temp1] += 1 + judgevalue * 9;
temp1 = "";
wordvalue = 0;
}
break;
}
}
}
if (wordvalue == 4) {
title[temp1] += 1 + judgevalue * 9;
wordvalue = 0;
temp1 = "";
}
while (fin.get() != ':');//读完Abstract:
while ((temp = fin.get()) != '
')//读完 Abstract:之后的内容
{
if (temp == EOF)
{
break;
}
if ('A' <= temp && temp <= 'Z')
temp = temp + 32;
switch (wordvalue) {
case 0: {
if (temp >= 'a'&&temp <= 'z') {
temp1 = temp1 + temp;
wordvalue = 1;
}
break;
}
case 1: {
if (temp >= 'a'&&temp <= 'z')
{
temp1 = temp1 + temp;
wordvalue = 2;
}
else { wordvalue = 0; temp1 = ""; }
break;
}
case 2: {
if (temp >= 'a'&&temp <= 'z')
{
temp1 = temp1 + temp;
wordvalue = 3;
}
else { wordvalue = 0; temp1 = ""; }
break;
}
case 3: {
if (temp >= 'a'&&temp <= 'z')
{
temp1 = temp1 + temp;
wordvalue = 4;
}
else { wordvalue = 0; temp1 = ""; }
break;
}
case 4: {
if (temp >= 'a'&&temp <= 'z' || (temp >= '0'&&temp <= '9')) { temp1 = temp1 + temp; }
else {
title[temp1] ++;
temp1 = "";
wordvalue = 0;
}
break;
}
}
}
if (wordvalue == 4) {
title[temp1] ++;
temp1 = "";
wordvalue = 0;
}
while (1)//读过空行或者判定结束
{
if ((temp = fin.get()) == EOF)
{
flag = -1;
break;
}
if (temp == '
')
{
continue;
}
if (temp <= '9'&&temp >= '0')
{
break;
}
}
if (flag == -1)break;
}
//按词频数输出;
int max2;
string max1;
int j;
int max = 0;
for (j = 0; j < jj; j++)
{
max2 = 0;
for (iter = title.begin(); iter != title.end(); iter++)
{
if (max2 < iter->second)
{
max2 = iter->second;
max1 = iter->first;
}
}
if (max2 != 0)
fout << '<' << max1 << '>' << ": " << max2 << endl;
if (max < max2)max = max2;
title[max1] = -1;
}
fin.close();
fout.close();
return 0;
}
首先,打开文件,进行预处理,通过temp1来记录当前所读得的字符串,搭配wordvalue来进行读取, 一次读取一个字符,若满足条件则将当前读取字符加入temp1,形成最新的temp1,若temp1满足成为单词的条件,且当前单词读取完毕则将temp1记录至之前定义的 map<string,int> title里(即title[temp1]),同时通过传入参数judgevalue来判断此单词的词频,并将此词频记录到title的key值里,(即title[temp1]+=最新所得词频值)之后将temp1清空=“”,重复操作,直至文件全部读取完毕。
PhraseFrequency()代码及其解释:
int PhraseFrequency(string filename_in, string filename_out, int phraseLength, int judgeValue,int sortLength)
{
//int phraseLength;//词组长读
//int judgeValue;//权重 0时都为1 1时Title为10 Abstract为1
//int sortLength; //前TOP N
//cin >> phraseLength;
//cin >> judgeValue;
//cin >> sortLength;
int i, j;
ifstream fin(filename_in, ios::in);
ofstream fout(filename_out, ios::app);
if (!fin) {
cout << "Can't open file" << endl;
return -1;
}
map<string, int> phrase;
map<string, int>::iterator iter;
char temp;//临时存放读入的字符
string temp1 = "";//临时存放可能成为合法单词的串
string temp2 = "";//临时存放分隔符
string str[400];//存放合法单词与非法单词
string dvi[400];//存放分隔符
int phraseValue = 0;//判定str连续的n个字符串是否满足成为词组条件
int wordValue = 0;//判定连续的字符是否可以成为合法单词
int unwordValue = 0;//判断分隔符
int lineWord = 0;//用于计数每篇论文的Title/Abstract的合法单词与非法单词数量,遇到换行符清零
int lineUnword = 0;//用于计数每篇论文的Title/Abstract的分隔符数量,遇到换行符清零
int flag = 0;//文件读入结束判定
while (true)//读入文件
{
flag = 0;
while (fin.get() != '
');//读完标号行
while (fin.get() != ':');//读完Title:
while (fin.get() != ' ');//读完:后的空格
for (i = 0; i <= lineWord; i++)//初始化有效单词数组
{
str[i] = "";
}
for (i = 0; i <= lineUnword; i++)//初始化分隔符数组
{
dvi[i] = "";
}
lineWord = 0; //初始化各项参数
lineUnword = 0;
unwordValue = 0;
while ((temp = fin.get()) != '
')//读完Title:后的内容
{
if (!((temp <= 'z'&&temp >= 'a') || (temp >= '0'&&temp <= '9') || (temp >= 'A'&&temp <= 'Z')))//判断是否为分隔符
{
temp2 = temp2 + temp;
unwordValue++;
}
else if (unwordValue > 0)
{
dvi[lineUnword++] = temp2;
temp2 = "";
unwordValue = 0;
}
if ('A' <= temp && temp <= 'Z')//判断是否为合法单词
temp = temp + 32;
switch (wordValue) {
case 0: {
if (temp >= 'a'&&temp <= 'z') {
temp1 = temp1 + temp;
wordValue = 1;
}
break;
}
case 1: {
if (temp >= 'a'&&temp <= 'z')
{
temp1 = temp1 + temp;
wordValue = 2;
}
else { wordValue = 0; temp1 = ""; str[lineWord] = "00"; lineWord++; }
break;
}
case 2: {
if (temp >= 'a'&&temp <= 'z')
{
temp1 = temp1 + temp;
wordValue = 3;
}
else { wordValue = 0; temp1 = ""; str[lineWord] = "00"; lineWord++; }
break;
}
case 3: {
if (temp >= 'a'&&temp <= 'z')
{
temp1 = temp1 + temp;
wordValue = 4;
}
else { wordValue = 0; temp1 = ""; str[lineWord] = "00"; lineWord++; }
break;
}
case 4: {
if (temp >= 'a'&&temp <= 'z' || (temp >= '0'&&temp <= '9')) { temp1 = temp1 + temp; }
else {
str[lineWord] = temp1;
lineWord++;
temp1 = "";
wordValue = 0;
}
break;
}
}
}
if (wordValue == 4) {
str[lineWord] = temp1;
lineWord++;
wordValue = 0;
temp1 = "";
}
for (i = 0; i <= lineWord - phraseLength; i++)//词组匹配
{
for (j = 0; j < phraseLength; j++)
{
if (str[i + j] != "00")
{
phraseValue++;
}
}
if (phraseValue == phraseLength)
{
for (j = 0; j < phraseLength - 1; j++)
{
temp1 = temp1 + str[i + j];
temp1 = temp1 + dvi[i + j];
}
temp1 = temp1 + str[i + phraseLength - 1];
phrase[temp1] +=1+judgeValue*9;
temp1 = "";
}
phraseValue = 0;
}
for (i = 0; i < lineWord; i++)//初始化有效单词数组
{
str[i] = "";
}
for (i = 0; i < lineUnword; i++)//初始化分隔符数组
{
dvi[i] = "";
}
lineWord = 0; //初始化各项参数
lineUnword = 0;
unwordValue = 0;
temp1 = "";
temp2 = "";
while (fin.get() != ':');//读完Abstract:
while (fin.get() != ' ');//读完:后的空格
while ((temp = fin.get()) != '
')//读完Abstract:的内容
{
if (temp == EOF)
{
break;
}
if (!((temp <= 'z'&&temp >= 'a') || (temp >= '0'&&temp <= '9') || (temp >= 'A'&&temp <= 'Z')))
{
temp2 = temp2 + temp;
unwordValue++;
}
else
{
if (unwordValue > 0)
{
dvi[lineUnword++] = temp2;
temp2 = "";
unwordValue = 0;
}
}
if ('A' <= temp && temp <= 'Z')
temp = temp + 32;
switch (wordValue) {
case 0: {
if (temp >= 'a'&&temp <= 'z') {
temp1 = temp1 + temp;
wordValue = 1;
}
break;
}
case 1: {
if (temp >= 'a'&&temp <= 'z')
{
temp1 = temp1 + temp;
wordValue = 2;
}
else { wordValue = 0; temp1 = ""; str[lineWord] = "00"; lineWord++; }
break;
}
case 2: {
if (temp >= 'a'&&temp <= 'z')
{
temp1 = temp1 + temp;
wordValue = 3;
}
else { wordValue = 0; temp1 = ""; str[lineWord] = "00"; lineWord++; }
break;
}
case 3: {
if (temp >= 'a'&&temp <= 'z')
{
temp1 = temp1 + temp;
wordValue = 4;
}
else { wordValue = 0; temp1 = ""; str[lineWord] = "00"; lineWord++; }
break;
}
case 4: {
if (temp >= 'a'&&temp <= 'z' || (temp >= '0'&&temp <= '9')) { temp1 = temp1 + temp; }
else {
str[lineWord] = temp1;
lineWord++;
temp1 = "";
wordValue = 0;
}
break;
}
}
}
if (wordValue == 4) {
str[lineWord] = temp1;
lineWord++;
wordValue = 0;
temp1 = "";
}
for (i = 0; i <= lineWord - phraseLength; i++)
{
for (j = 0; j < phraseLength; j++)
{
if (str[i + j] != "00")
{
phraseValue++;
}
}
if (phraseValue == phraseLength)
{
for (j = 0; j < phraseLength - 1; j++)
{
temp1 = temp1 + str[i + j];
temp1 = temp1 + dvi[i + j];
}
temp1 = temp1 + str[i + phraseLength - 1];
phrase[temp1]++;
//cout << temp1 << endl;
temp1 = "";
}
phraseValue = 0;
}
while (1)//读过空行或者判定结束
{
if ((temp = fin.get()) == EOF)
{
flag = -1;
break;
}
if (temp == '
')
{
continue;
}
if (temp <= '9'&&temp >= '0')
{
break;
}
}
if (flag == -1)break;
}
int max2;
string max1;
int max = 0;
for (j = 0; j < sortLength; j++)//输出TOP n
{
max2 = 0;
for (iter = phrase.begin(); iter != phrase.end(); iter++)
{
if (max2 < iter->second)
{
max2 = iter->second;
max1 = iter->first;
}
}
if (max2 != 0)
fout << '<' << max1 << '>' << ": " << max2 << endl;
if (max < max2)max = max2;
phrase[max1] = -1;
}
fin.close();
fout.close();
return 0;
}
可结合搭配上方UML图来进行代码等的理解分析。(由于代码注释比较详尽,这里重点说一下整体算法核心思想。)算法核心思想:创建两个字符串数组str,dvi,一个装单词,一个装分隔符,如果匹配到的是单词且合法,则str[i]=该单词,不合法则str[i]="00",分隔符同理。词组拼接时,如果连续n个单词满足不为“00”,则为合法词组。以长度为3的词组为例,str[i]+dvi[i]+str[i+1]+dvi[i+1]+str[i+2]。
5.Additional Question Section:
我们又额外爬取了各篇论文的作者信息,为了方便起见,我将作者信息单独放在一个文本中。

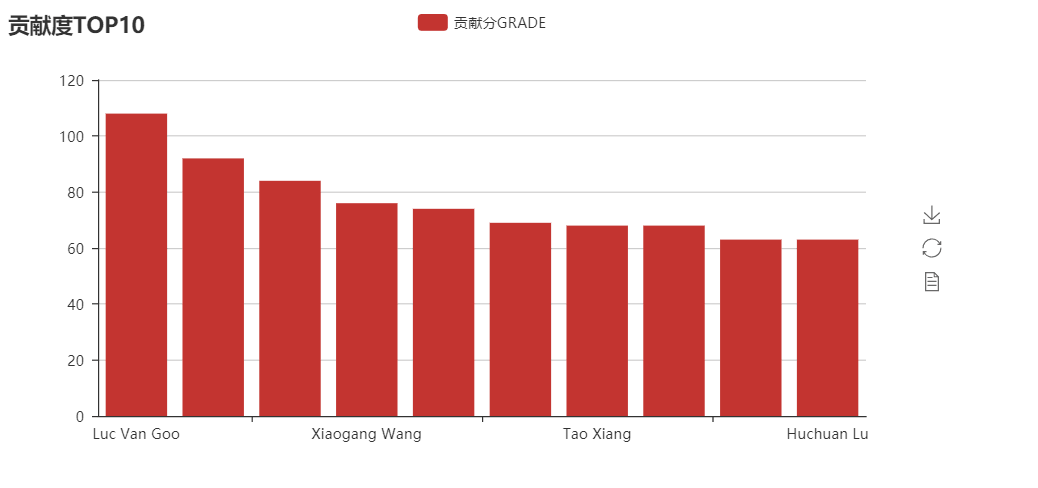
对作者信息进行分析,我们在这里定义两个值为贡献值和参与次数,若为某篇论文的第一作者,则可获得贡献值10,依次递减1,到1为止。另外也统计了参与次数与参与人数。


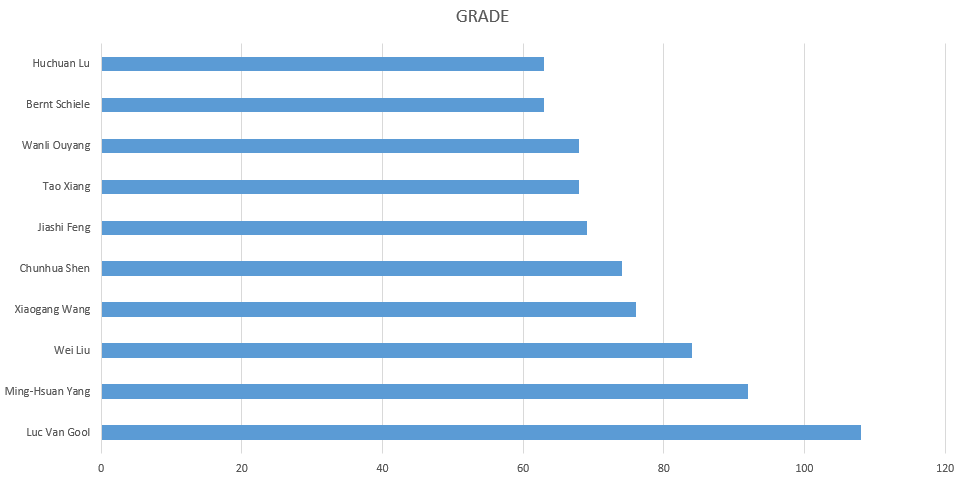
作者贡献值排名:
代码:
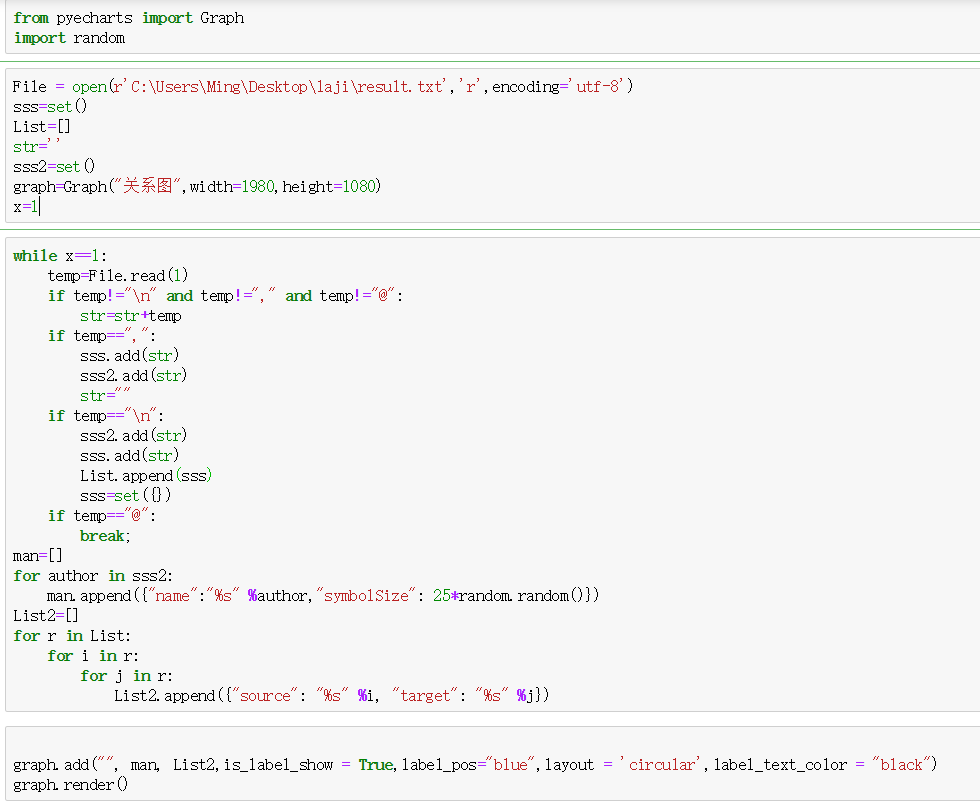
使用Python的pyecharts的Bar和Graph完成的。
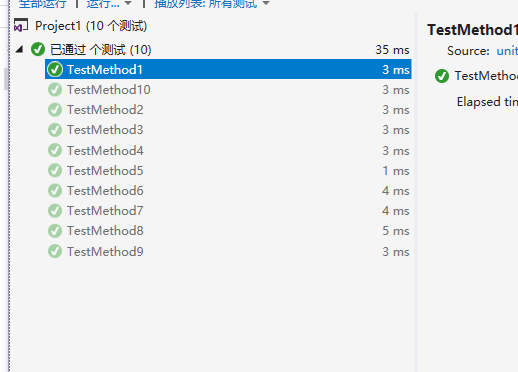
6.Performance analysis & unit testing:
| 测试编号 | 说明 |
| 1 | 空文本 |
| 2 | 无有效单词 |
| 3 | 无权值 |
| 4 | 有权值 |
| 5 | 文件不存在 |
| 6 | 长词组 |
| 7 | 多个词组 |
| 8 | 多篇论文 |
| 9 | 全分隔符 |
| 10 | 分隔符与非法单词 |
单元测试 & 部分代码截图 :
性能分析:
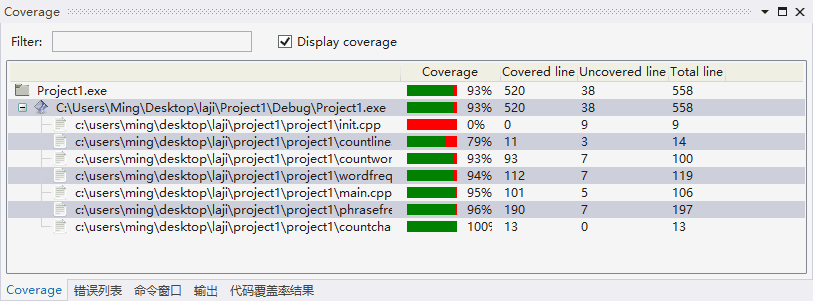
代码覆盖率
7.Difficulties & Gains:
1.爬取,其实一开始我们是比较烦恼该如何去进行爬取的,但是后来经过小伙伴的努力,我们还是解决了这个问题!(开心~O(∩_∩)O
2.对题目的整体把握。本次的题目其实比较有把握去完成,(十分感谢前几次实践的积累~~~!!)但是尽管如此,我们还是在函数接口上,以及一些函数细节上把握出现了一些偏差,以至于我们花了不少时间进行调试。但是最终还是全部完成啦~~
3.附加题的想法。关于附加题,我们一开始还是比较迷茫的。但是当我们在完成主要任务的过程中,我们便萌发了一些想法,最终也比较顺利的完成附加题的展示。
4.对于细节的把握不够。在制作的过程中,我们时不时地会发现,我们漏了题目的哪些细节,以至于我们必须随着项目的进度一次一次的阅读题目,我们感觉对于“读透题目”也是一个十分重要的技能!!能节约十分多的时间和资源!
8.Evaluation:
我的小伙伴“黄毓明”同学: 虽然他自称他是佛系队友,但是!!!!我还是十分敬佩他的,他总能够在我们项目的一些“瓶颈”期时提出一些比较新颖的想法,以及解决问题的方法,总能够给我们这个两人小团体带来一些方向和曙光!和黄毓明同学一起合作,我感觉我自己也学到了很多,也成长了很多,十分荣幸能和他结对完成项目!@黄毓明~~ 一起加油鸭~!!!!
9.Schedule:
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 500 | 500 | 15 | 15 | 学习VS2017,GitHub使用,复习C++相关知识 |
| 2 | 500 | 1000 | 20 | 35 | 阅读《构建之法》,从零开始学Java语言 |
| 3 | 1000 | 2000 | 15 | 50 | 阅读《构建之法》,学习Java,学习墨刀等工具使用 |
| 4 | 700 | 2700 | 35 | 85 | 复习C++知识,学习STL的使用。 |
| 5 | 300 | 3000 | 20 | 105 | 学习STL相关知识,以及使用VS,Process On 等工具 |