二、计算向数据移动如何实现?
Hadoop1.x(已经淘汰):
hdfs暴露数据的位置
1)资源管理
2)任务调度
角色:JobTracker&TaskTracker
JobTracker: 资源管理、任务调度(主)
TaskTracker:任务管理、资源汇报(从)
Client:
1.会根据每次计算数据,咨询NN的元数据(block)。算:split 得到一个切片的清单
map的数量就有了
2.split是逻辑的,block是物理的,block身上有(offset,locatios),split和block是有映射
关系的。
结果:split包含偏移量,以及split对应的map任务应该移动到哪些节点(locations)
可以支持计算向数据移动了~!
生成计算程序未来运行时的文件
3.未来的移动应该相对可靠
cli会将jar,split清单,配置xml,上传到hdfs的目录中(上传的数据,副本数为10)
4.cli会调用JobTracker,通知要启动一个计算程序了,并且告知文件都放在了hdfs的哪个地方
JobTracker收到启动程序后:
1.从hdfs中取回【split清单】
2.根据自己收到的TT汇报的资源,最终确定每个split对应的map应该去到哪一个节点
3.未来TT再心跳的时候会取回分配自己的任务信息
TaskTracker
1.在心跳取回任务后
2.从hdfs下载jar,xml到本机
3.最终启动任务描述中的Map/Reduce Task(最终,代码在某个节点被启动,是通过cli上传,TT下载)
问题:
JobTracker3个问题:
1.单点故障
2.压力过大
3.集成了资源管理和任务调度,两者耦合
弊端:未来新的计算框架不能复用资源管理
1.重复造轮子
2.因为各自实现资源管理,因为他们不熟在同一批硬件上,因为隔离,所以不能感知
所以造成资源争抢
思路:(因果关系导向学习)
计算向数据移动
哪些节点可以去?
确定了节点对方怎么知道,一个失败了应该在什么节点重试
来个JobTracker搞定了2件事。但是,后来,问题暴露了
Hadoop2.x yarn的出现
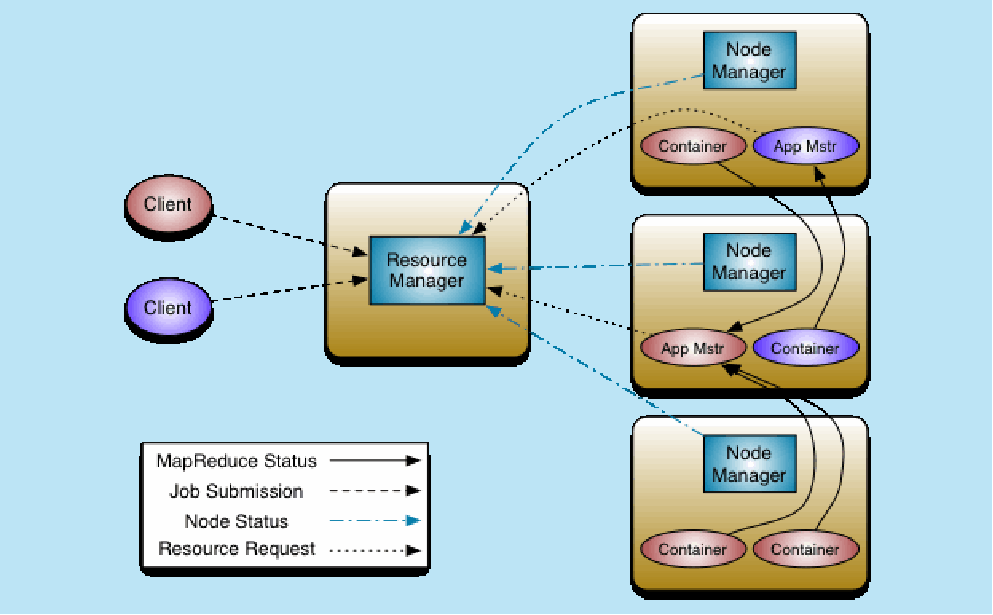
yarn架构图
查看架构图的方法:
1.确定实主从架构还是无主架构
2.查看如何调度进程
Hadoop2.x yarn:
模型:
container 容器 不是docker
虚的
对象:属性:cpu,mem,io量
物理的:JVM->操作系统进程(1,NN会有线程监控container资源情况,超额,NM直接kill掉
1.NM会有线程监控container资源情况,超额,NM直接kill掉
2.cgroup内核级技术:在启动jvm进程,由kernel约束死
架构: 架构/框架
ResourceManger 主
负责整体资源的管理
NodeManager 从
向RS汇报心跳,提交自己的资源情况
MR运行 MapReduce on yarn
1.MR-cli(切片清单/配置/jar/上传到HDFS)
访问RM中申请AppMaster
2.RM选择一台不忙的节点通知NM启动一个Container,在里面反射一个MRAppMaster
3.启动MRMaster,从hdfs下载切片清单,向RM申请资源
4.由RM根据自己掌握的资源情况得到一个确定清单,通知NM来启动container
5.container启动后会反向注册到已经启动的MRAppMaster进程
6.MRAppMaster(曾经的JobTracker阉割版不带资源管理)最终将任务Task发送container(消息)
7.container会反射相应的Task类作为对象,调用方法执行,其结果就是我们的业务逻辑代码的执行
结论:
问题:
1.单点故障(曾经是全局的,JT挂了,整个计算层没有了调度)
yarn:每一个APP由一个自己的AppMaster调度(计算 程序级别)、
2.压力过大
yarn中每个计算程序自由AppMaster,每个AppMaster只负责自己计算程序的任务调度,轻量了
AppMaster在不同节点中启动的,默认有了负载的光环
3.继集成了【资源管理和任务调度】,两者耦合
因为Yarn只是资源管理,不负责具体的任务调度
是公立的,只要计算框架继承yarn的AppMaster,大家都可以使用一个统一视图的资源层!!
总结感悟:
从1.x到2.x
JT,TT是MR的常服务
2.x之后没有了这些服务
相对的:MR的cli,调度,任务,这些都是临时服务了。