前言分析目标网站的登录方式
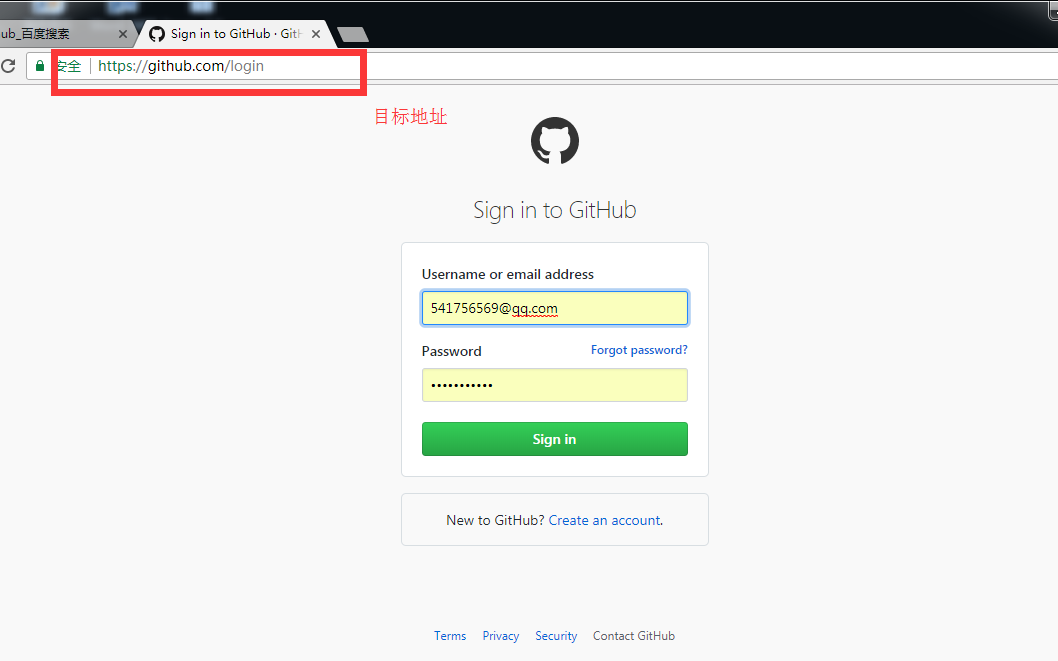
目标地址:https://github.com/login
登录方式做出分析:
第一,用form表单方式提交信息,
第二,有csrf_token,
第三 ,是以post请求发送用户名和密码时,需要第一次get请求的cookie
第四,登录成功以后,请求其他页面是只需要带第一次登录成功以后返回的cookie就可以。
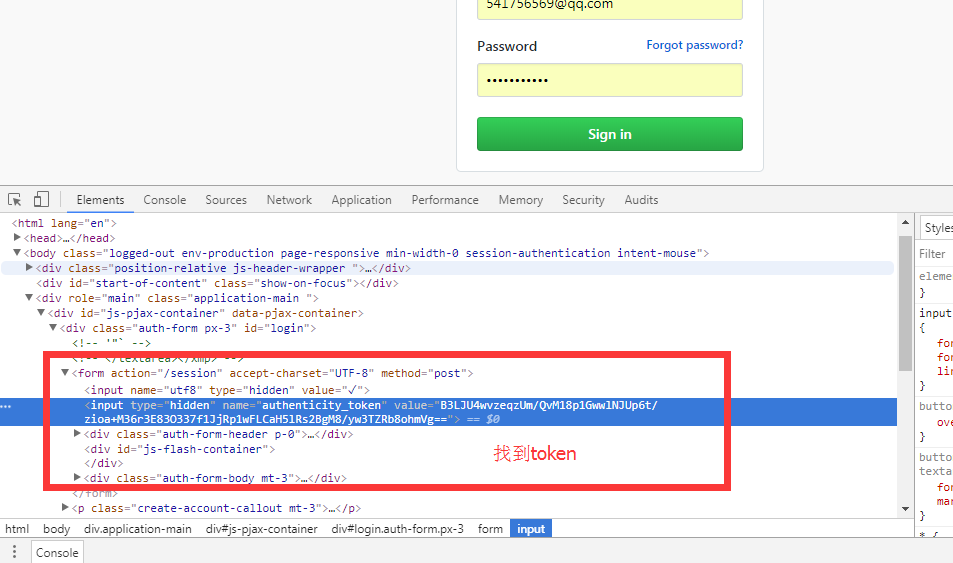
以get发送的请求获取我们想要的token和cookie
代码:
import requests
from bs4 import BeautifulSoup
r1 = requests.get('https://github.com/login')
soup = BeautifulSoup(r1.text,features='lxml') #生成soup 对象
s1 = soup.find(name='input',attrs={'name':'authenticity_token'}).get('value')
#查到我们要的token
r1_cookies = r1.cookies.get_dict() # 下次提交用户名时用的cookie
# print(r1_cookies)
# print(s1)
#结果::
{'logged_in': 'no', '_gh_sess': 'VDFWa2hJWjFMb1hpRUFLRDVhUmc3MXg1Tk02TDhsUnhDMERuNGpyT2Y4STlQZ2xCV1lCZEFhK21wdFR1bkpGYUV0WEJzcDEydWFzcm93
aVc4Nk91Q2JicmtRV0NIQ0lRSWM4aFhrSVFYbCtCczBwdnhVN0YySVJJNUFpQnhyTzNuRkJwNDJZUWxUcEk2M2JkM3VSMDdXVHNOY1htQkthckJQZDJyUVR2RzBNUkU3VnltRVF2U
m1admU3c3YzSGlyVnVZVm0ycnA1eUhET1JRVWNLN0pSbndKWjljMGttNG5URWJ1eU8rQjZXNEMxVEthcGVObDFBY2gvc2ZzWXcvWWZab29wQWJyU0l6cmZscWhBQUlzYTA3dTRtb
3l1S0hDYytHY2V1SUhEWlZvVlZoSWZpTzBjNmlidFF2dzI2bWgtLTJON1lqbm5jWUtSYmtiVEM1clJPakE9PQ%3D%3D--897dbc36c123940c8eae5d86f276dead8318fd6c'}
pRz0wapEbu5shksGCeSN0FijWoU9ALw8EPUsXlqgcw1Ezirl0VbSKvkTYqIe8VhxhPH2H/uzGaV6XX+yjTGoVA==
获取这两个值就可以,进行下一步发送登录请求:
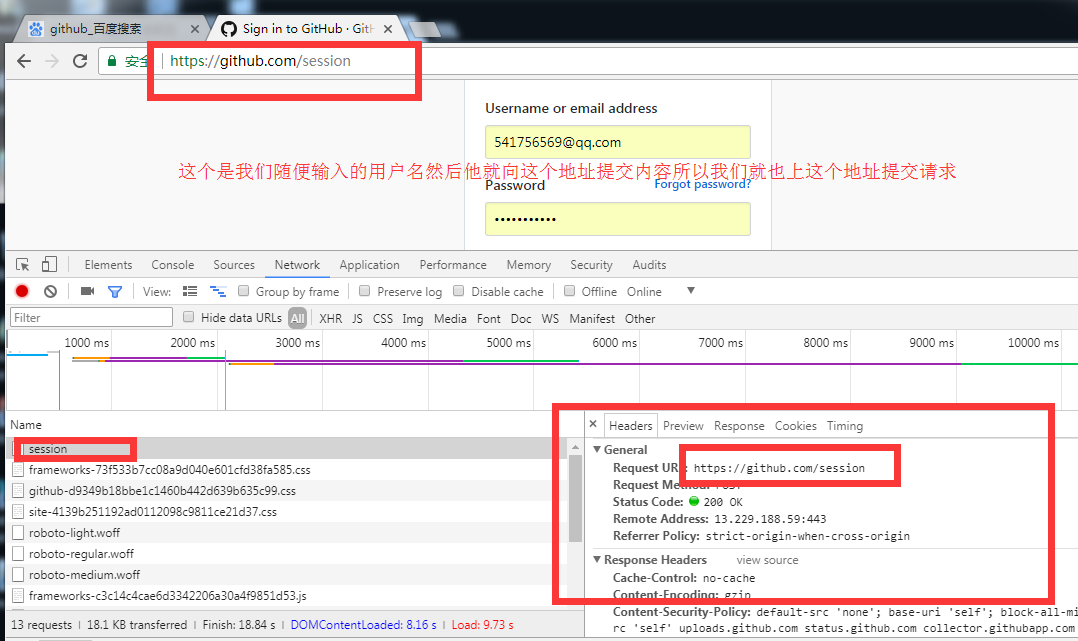
第二步post方式提交用户名密码
代码::
这个代码接着上面的get请求,只是post请求的部分,
r2 = requests.post(
'https://github.com/session',
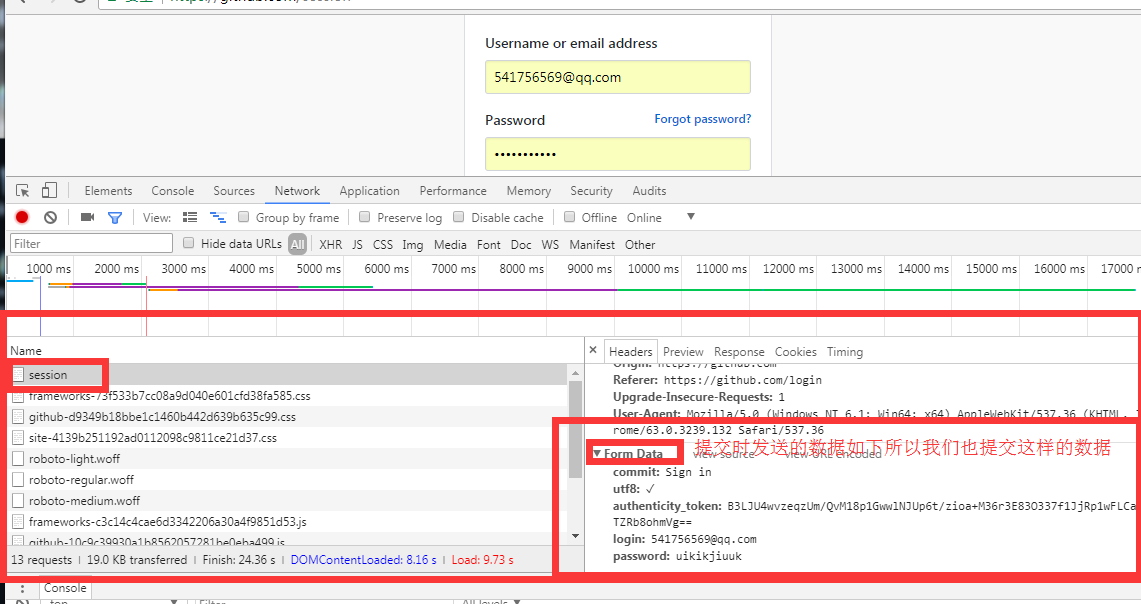
data ={
'commit':'Sign in',
'utf8':'✓',
'authenticity_token':s1,
'login':'541756569@qq.com',
'password':'用户名密码' # 填上正确的用户名即可
},
cookies = r1.cookies.get_dict(), # 这里需要第一次的cookie
)
print(r2.cookies.get_dict()) # 这个是成功以后的cookie
成功以后就返回登录页面的信息。
基于post登录成功后查看个人详情页。
这里只需要带着登录成功以后的cookie 就可以
#完整代码
import requests
from bs4 import BeautifulSoup
r1 = requests.get('https://github.com/login')
soup = BeautifulSoup(r1.text,features='lxml')
s1 = soup.find(name='input',attrs={'name':'authenticity_token'}).get('value')
r1_cookies = r1.cookies.get_dict()
print(r1_cookies)
print(s1)
r2 = requests.post(
'https://github.com/session',
data ={
'commit':'Sign in',
'utf8':'✓',
'authenticity_token':s1,
'login':'541756569@qq.com',
'password':'密码'
},
cookies = r1.cookies.get_dict(),
)
查看个人详情页
print(r2.cookies.get_dict())
r3 = requests.get(
'https://github.com/13131052183/product', #查看个人的详情页
cookies = r2.cookies.get_dict()
)
print(r3.text)