这一系列笔记已经记录很长一段时间了,种种原因没有贴出来,现在陆陆续续的贴出来。可能由于自己理解的
错误和疏忽,导致存在错误,欢迎大家指正,交流。
所有的源码分析都是基于OpenStack Folsom版本。
参考文档:http://hi.baidu.com/chenshake/item/184767c22c1231ba0d0a7bc7
这篇博客的前半部分基本上参照ibm(链接如上)的内容。
在理解OpenStack 授权机制之前,先明白其中的一些基本概念:
- User: 所谓的User代表着一些人或者能够通过keystone获取访问的something。User通过自身的证书例如username & password 或者 api keys来访问服务。
- Tenant:Tenant代表nova中的一个project,就是能够聚合一些服务中的一些资源。例如,一个tenant能够有一些nova中的虚拟机,glance中的一些images,quantum中的一些networks,users默认的绑定到某个tenant中。
- Role:代表一组用户能够一定程度的访问资源。例如能够访问nova中的vms,glance中的images。Users能够被添加到所有的tenants中或者某个tenant。用户就获取了对相应tenant中对应角色获取的访问资源的权限。
- service: 某类型的服务,例如nova, quantum, glance等等都是服务
- endpoint: 访问服务的入口点,一个http路径。例如:catalog.RegionOne.image.internalURL = http://10.10.102.14:9292,可以通过此URL访问image服务
接下来,分析用户在访问一个服务的过程中,keystone都做了哪些工作,整个过程描述如下:
1. 获取token
首先,需要确认你将访问那个tenant,必须使用keystone来获取一个unscoped token(意味着这个token没有和特定的tenant绑定),这个unscoped token能够用来深入查询keystone service,确定你能访问哪些tenants。获取一个unscoped token,使用典型的REST API,在request的body中不指定tenantName。例如:

经过成功的验证,返回的response大致如下,其中的token id就是获取到的unscoped token(访问路径:/access/token/id),token id 将被在下一次的请求中作为X-Auth-Token的值,用来标识身份。

2. 获取tenants
接下来的一步是,使用unscoped token来获取能访问的tenants,其中租期已经由你分配的角色决定了,对于每个tenant,都有一个确定的角色。所有在service endpoint上执行的操作都需要一个scoped token。获取能访问的tenants,使用 GET /tenants keystone API,其中将unscoped token写入X-Auth-Token。例如:
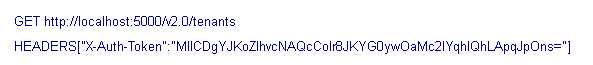
返回的响应如下:

这是一个tenants数组,包含了能够访问的tenants。
3. 获取scoped tokens
获取了能够访问的tenants之后,决定访问某个tenants,就开始需要获取一个scoped token,这个scoped token与某个特定的tenant绑定,能够提供这个tenant的metadata和在tenant中的角色。获取scoped token需要使用POST /tokens keystone API,像第一步一样,这有两种形式的API。
1. 使用第一步中一样的request body,传递user id 和 credentials,还指定tenantName

2. 使用包含unscoped token和tenant name的request body,这样无需再post credentials。

在返回的response中,包含一个scoped token和相关的metadata。



更重要的是,其中包含了一组service endpoints。这些endpoints 确定了获取的token能够访问的服务,Keystone service manage都是基于service/endpoing catalog的.通过这些endpoings,决定访问其中的service。
关于keystone 管理的endpoint/service catalog:
l Keystone管理了一些的service,这些service在keyston的service catalog中定义了,定义方式大致是,type,name,description
l 在service catalog中,endpoint包含了region中一些基本的URL。
l 每个endpoint与一个service关联。
l Endpoint url都是base urls,作为api方位的前缀。

4. 获取scoped tokens
现在已经获取了scoped tokens,并且知道了endpoint API的url,下一步就是调用这些service endpoint。在这一步,使用keystone来确证token的有效性。存在两种类型的token,一种基于UUID的,一种基于PKI(Public Key Infrastructure)。
l UUID Keystone 将维护一个token的UUID到他们的metadata和有效性的索引,token id没有携带嵌入的metadata,则endpoint service将调用keystone的service,应用这个token id的有效性,keystone将会返回这个token所相关联的metadata,包括角色,tenancy(租期),能够用在处理api请求的内部使用,endpoint service会为每个api request去调用keystone服务验证有效性。
l PKI PKI使得endpoint service不需要每次api request都进行调用keystone验证token的有效性。PKI使用public/private certificate pair,基于X.509 技术。Keystone 拥有Public private certificate。任何人都能通过REST API获取到public certificate,private certificate只能keystone拥有。当使用PKI,第一次使用endpoint service时,endpoint service将请求keystone的public certificate,并且保存起来。使用PKI模式,keystone将会创建json格式的对象,包含token的metadata,使用private certificate来加密token,再使用MD5来为加密的token创建指纹,这样的token将作为第三步中token ID返回,这样token ID包含了metadata而不仅是一个UUID字符串。Endpoint service将会确认签名,使用public certificate解密token。这样,token包含所有的metadata了,endpoint service不需要再去找keystone获取这些信息。
能够在keystone.conf配置文件中配置token_format.
5. 验证role metadata
Endpoint service 使用token的metadata来验证用户能够访问请求的服务。这一般都涉及到Role Base Access Control(RBAC)。基于服务的policy.json文件,使用rule engine来决定用户的token包含适当的角色访问。
6. service API request
到此,user就能够去通过api访问有权限访问的资源。
有了上面基本知识,下面结合具体的代码粗略的描述上面的流程。
从最开始的shell命令行开始,譬如,nova list命令,但在使用命令之前,我们需要配置一下环境变量:
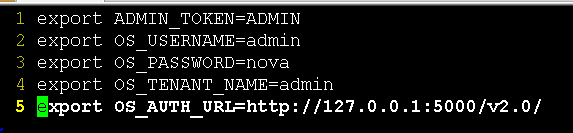
将这些参数配置正确,便能够正确的执行nova list命令了。从nova 命令启动之后,python-novaclient 的main函数首先获取一个base parser,用来解析命令行,在获取这个base parser的过程中,就会添加参数,例如os-username等等,并且设置其默认值为,从环境变量中读取出来的值。例如下面的os-username

接着,从命令行参数中去获取os_username,os_password,os_tenant_name,os_auth_url,endpoint_type等等和授权相关的参数,有些参数如endpoint_type为空,则获取默认的,若os_username,os_password,os_auth_url都为空,则命令报错。
如果endpoint_type是空的,则读取默认的值publicURL,前面介绍过service endpoint type的类型,有三类,publicURL,adminURL,internalURL。若service_type为空,则读取默认的值compute或者通过命令具体执行的命令是属于什么类型的service来确定。(在定义一个命令行将调用的函数时,可以为它添加装饰器,指定所属的service)

譬如通过命令 nova volume-list,就会获知service_type为volume,而不是默认的compute。
然后,从auth_url指定的服务中获取授权,程序运行到这儿之后,就到了前面介绍的第一步了,获取tokens,并且在body中指定了tenantName。

在返回的body中,就已经获取了所有的service catalog,根据service_type,endpoint_type则可以生成management_url.http://10.10.102.31:8774/v2/eacac8f7935348c7a6aa3ea6fe54e18c,此url则是访问nova compute服务的base url。然后在此url基础上,加上命令的具体参数,就访问此URL的服务--nova compute。
nova compute接受到此请求之后,会验证次请求,然后完成请求。