Q-learning是强化学习中一种经典的无监督学习方法,通过与环境交互来指导学习;
大部分强化学习都是基于马尔科夫决策(MDP)的。MDP是一个框架,而Q学习是应用了这种框架的一个具体的学习方法。
Q学习的四要素:(agent,状态 s,动作 a,奖励 r)
简而言之,agent从当前状态选择一个动作,转移至一个新的状态,这个过程会获得一个即时奖励 r,agent再据此更新动作值函数Q,并将Q值储存在Q表中。
这里关键的有一个即时奖励矩阵R,和一个存储动作值函数值的Q表;两个表都是二维,行表示状态,列表示动作;
Q学习中的Q值更新函数(其实基于MDP中的值函数):
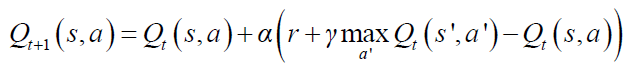
α:学习速率; γ:折扣因子 ,表示对未来奖励的重视程度;
不过我个人而言,常用α=1的情况,因为α的值对于算法对比和优化的效果差别不大(在迭代次数足够多的情况下);
一下这个小例子用的是动态规划的方法迭代计算Q,因为模型已知;模型未知的情况常采用蒙特卡洛算法 & 时序差分算法(TD,常用);
简单的一个迷宫例子就是这个走迷宫了~从任意状态开始,走到房间5就算成功了~


python实现Q学习走迷宫:
1 # an example for maze using qlearning, two dimension 2 import numpy as np 3 4 # reward matrix R 5 R = np.array([[-1, -1, -1, -1, 0, -1], [-1, -1, -1, 0, -1, 100], 6 [-1, -1, -1, 0, -1, -1], [-1, 0, 0, -1, 0, -1], 7 [0, -1, -1, 0, -1, 100], [-1, 0, -1, -1, 0, 100]]) 8 9 Q = np.zeros((6, 6), float) 10 gamma = 0.8 # discount factor 11 12 episode = 0 13 while episode < 1000: 14 state = np.random.randint(0, 6) # from a random start state 15 for action in range(6): 16 if R[state, action] > -1: 17 Q[state, action] = R[state, action] + gamma*max(Q[action]) # this time, action is the next state 18 episode = episode + 1 19 20 print(Q)