介绍feature, py文件和之间关系:
example01.feature文件包括5行: Feature行: 介绍这个feature用来干什么的; Scenario行:介绍这个scenario用来干什么的;Given: 一般数据的初始化在这里执行;When:执行操作;Then:验证结果。
example01.py文件包括@given, @when, @then. 具体步骤实现在每一个对应的步骤里面实现。
接下来我们使用selenium来启动firefox浏览器,做一些页面上的操作和验证。 --可以使用exclipse或者Notepad++工具来写代码
一、新建文件夹example02,在文件夹里面新建example02.feature文件:
#../feature/example02/example02.feature
Feature:Search behave results in
baidu
Scenario: Search behave results in baidu
Given Access baidu
website
When Input behave characters
Then There are more than 1
results displaying
二、在example02文件夹里面新建steps文件夹,然后创建example02.py文件:
# This Python file uses the following encoding: utf-8 #../feature/example02/steps/example02.py
from selenium import webdriver
import time
import sys
@Given('Access baidu website')
def step_impl(context):
reload(sys)
sys.setdefaultencoding('utf-8') #设置python的编码方式为utf-8,它默认的是ACSII, 否则会报UnicodeDecodeError
context.driver = webdriver.Firefox()
context.driver.get("http://www.baidu.com")
@when('Input behave characters')
def step_impl(context):
context.ele_input = context.driver.find_element_by_xpath("//input[@id = 'kw']")
context.ele_input.send_keys("behave")
context.ele_btn = context.driver.find_element_by_xpath("//input[@id = 'su']")
context.ele_btn.click() time.sleep(10)
@Then('There are more than 1 results displaying')
def step_impl(context):
context.ele_results = context.driver.find_element_by_css_selector("div.nums")
context.expected_results = '相关结果'
if context.expected_results in context.ele_results.text:
assert True
else:
assert False
三、打开cmd,cd到example02.feature所在的路径,然后输入behave, 结果运行正常:
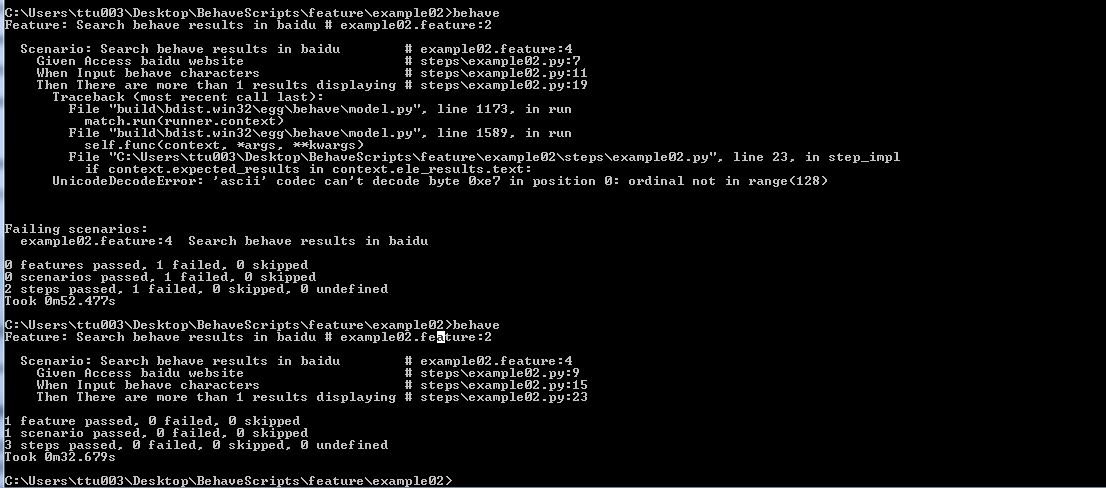
你会发现第一次我运行失败,原因是没有设置python的默认编码方式。
问题解决:
- 当使用中文字符的时候,会出现 SyntaxError: Non-ASCII character '/xe6' 错误,这个时候,在python语句的第一行加上 # This Python file uses the following encoding: utf-8 或者 #encoding: utf-8 即可以解决这个问题。以下为参考网址:
http://blog.csdn.net/mayflowers/article/details/1568852
https://www.python.org/dev/peps/pep-0263/
- 出现 UnicodeDecodeError: 'ascii' codec can't decode byte 0xe7 in position 0: ordinal not in range(128):加入以下代码进去,即可以解决问题。
import sys
reload(sys)
sys.setdefaultencoding('utf-8')