
Class文件常量池
了解
Class文件中除了有类的版本、字段、方法、接口等描述等信息外,还要一项信息是常量池(Constant Pool Table),用于存放编译器生成的各种字面量和符号引用(不是对象),这部分内容将在类加载后存放到方法区的运行时常量池中。Class文件常量池每个类只有一个,在类被编译时初始化。
字面量就不多说了,符号引用是一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用时能无歧义地定位到目标即可。(它与直接引用区分一下,直接引用一般是指方法区的本地指针,相对偏移量或是一个能间接定位到目录的句柄)。
Class文件常量池的每一项常量都是一个表,一共有如下表所示的12种各不相同的表结构数据,这每个表的第一位都是一个字节的标志符(取值1-12),代表当前这个常量属于哪种常量类型。一般概括为下面三类常量:
-
- 类和接口的全限定名
- 字段的名称和描述符
- 方法的名称和描述符
1.1.0
1 // 代码段1.2.0 2 3 public static void main(String[] args) { 4 String str = "Hello"; 5 String str2 = new String("Bey"); 6 } 7 8 // 字节码 9 public static void main(java.lang.String[]); 10 Code: 11 0: ldc #2 // String Hello 12 2: astore_1 13 3: new #3 // class java/lang/String 14 6: dup 15 7: ldc #4 // String Bey 16 9: invokespecial #5 // Method java/lang/String."<init>":(Ljava/lang/String;)V 17 12: astore_2 18 13: return
Java虚拟机规范中对Class文件常量池概述如下:
Java 虚拟机指令执行时不依赖与类、接口,实例或数组的运行时布局,而是依赖常量池
(constant_pool)表中的符号信息。
所有的常量池项都具有如下通用格式:
cp_info { u1 tag; u1 info[]; }
【引自:虚拟机规范SE7 pdf版4.4章节】
1.2.0:虚拟机规范中所说的"符号信息"指的是什么?
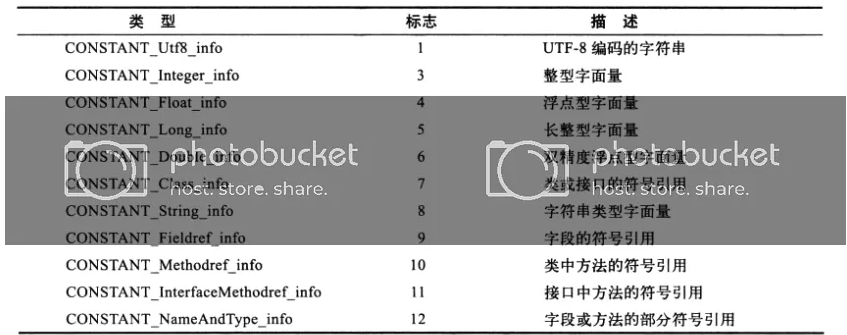
上面了解的时候说了,常量池的每一项常量都是一个表,一共有12种各不相同的表结构数据,拿上面的代码段1.2.0来分析,在Class文件常量池中与字符串有牵扯的通用格式结构(也就是表结构)有两种:CONSTANT_Utf8_info和CONSTANT_String_info。我们分别来看一下这两种结构的官方描述:

1.2.0
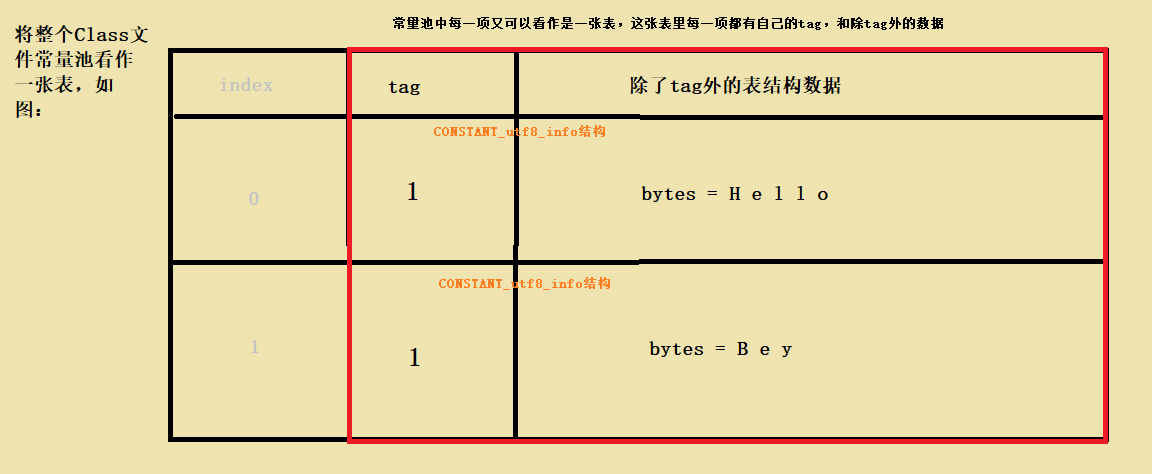
关键部分我已经用黄色高亮了,CONSTANT_utf8_info它用于表示字符串常量的值,也就是代码中的"Hello"和"Bey"值,在结构各项说明中tag意思是图1.1.0中的标志,CONSTANT_Utf8(1)即tag值为1。bytes才是真正存储我们常量 值 的地方。对于以上代码臆想图如下
1.2.1
真实的结构和bytes并不像我图中那样表示,这里只是为了直观的演示,希望能有更好的理解。

1.2.2
对比图1.2.0可以看出一个明显的区别是,CONSTANT_String_info表示的结构是java.lang.String类型的常量对象,也就是new出来的String对象,见代码段1.2.0中字节码13行。注意看它的string_index说明,string_index项的值必须是对常量池的有效索引,也就是我在图2.1中隐约画出的index列,对于new String("Bey")它的string_index值显然应该是图1.2.1中的index为1的项。接着黄色高亮又强调了,这个索引处的项即图1.2.1中index=1的项必须是CONSTANT_Utf8_info结构。用一张直观图描述如下:
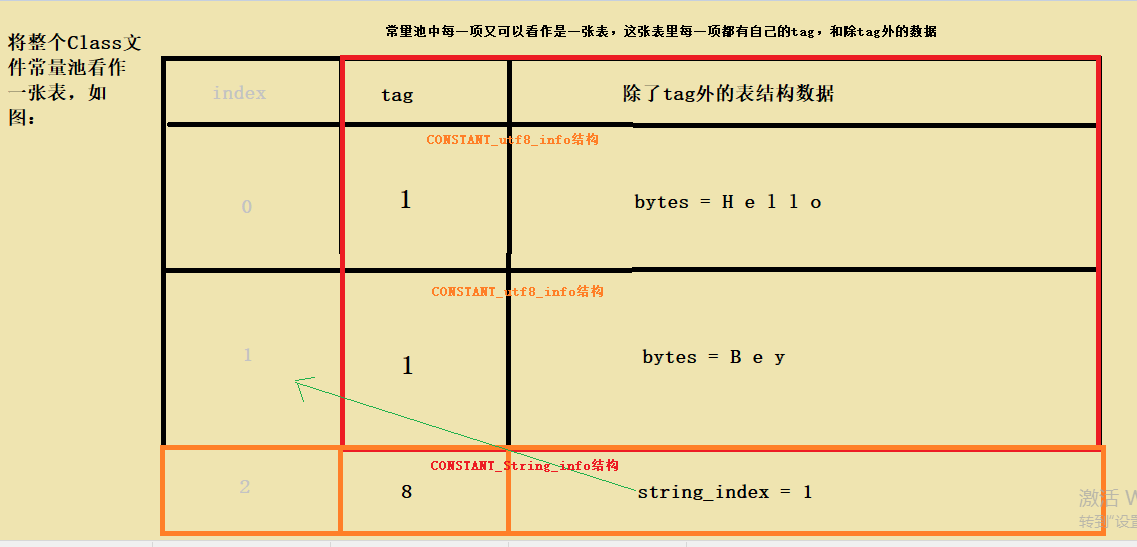
1.2.3
抛出问题1.2.0中"符号信息"指的就是这些常量表信息。关于Class文件常量池,如上也只是介绍了和String相关的结构,还有其他10种结构也很简单,说白了就是针对不同的结构定义不同存储数据的格式(表)而已,这里就不在赘述了。总结一句废话就是:Class文件常量池用于存放编译器生成的各种字面量和符号引用。(常量池内常量结构刨析到此结束,下面在抛出的这个问题,推荐读者洗脑清醒后再看。)
有一件细思极恐的事情:在图1.2.0中最后有关bytes的介绍中说:bytes[]是表示字符串值的byte数组。
1.2.1:java什么时候又突然多了一个bytes类型?表示byte类型的数组不应该是byte[]吗?
我们在看看规范里下面的描述:

1.2.4
图1.2.4说了,字符串常量采用改进过的UTF-8编码表示:

1.2.5
改进版的UTF-8格式码点范围在:
'u0001'-'u007F'的字符用单字节表示(十进制0-127)
'u0000'或'u0080'-'u07FF'的字符用双字节表示(十进制128-2047)
'u0800'-'uFFFF'的字符用三个字节表示(十进制2048-65535)
超过'uFFFF'的(称为补充字符)在UTF-16编码中需要用2个UTF-16字符单元表示,而UTF-16中每个字符单元占3个字节,即总共需要6个字节来表示。(十进制65535-2097151)
具体ASCII码、Unicode编码对照表参见百度。
为解决上面编号为1.2.1的问题,我们在先来看看字节和字符的概念:

1.2.6

1.2.7
了解了这些概念上的东西,针对图1.2.4为什么说bytes[]?而不说byte[]?的问题就好解释多了,对于java基本数据类型byte、short、char大家都知道,基本类型byte它的取值范围是-128 - 127,但是图1.2.4里说的byte表示的范围确不只是-128 - 127,图1.2.4里所说的byte压根没有负数的!直接从0开始,一直到2097151,所以这两个byte压根就不是同一个东西!!!在看那bytes[]和byte[]你就会明白,bytes[]里的元素byte表示的字符转换后的字节,而byte[]里的元素byte就单单表示-128-127这些整数值。尽管这里的byte和byte基本数据类型表示的值在一定范围上有的重合(0 - 127重合),但此byte非彼byte。至于为什么将它称之为bytes[]而不称为byte[],可能也就是为了区分这二者之间的差异。
1.2.3:bytes真的是个数组吗?
bytes[]如果是个数组,那这个数组的类型应该就是bytes,刚才说了bytes是表示字符串的码点字符(每个字符转换后的字节)序列,但是java中并没有bytes这个类型,那姑且先把bytes看成用于形象表示字符串码点序列的字节数组吧,我们假设:bytes是数组类型,如果这样看的话,那bytes显然不符合"引用类型",在java虚拟机规范SE7中pdf版2.4章节有这么一段话:

1.2.8
上面黄色高亮的,如把bytes看成数组类型,那数组元素类型必须是原始类型,原始类型里只包括数值类型、布尔类型、returnAddress三类,数值类型里包含的整形(又包括byte,short...),原始类型根本不满足把bytes看成数组的条件,所以我想它根本不是引用类型,不是引用类型就不会在堆中去实例化这个bytes数组,所以按照以上推理我个人认定这个bytes就是在class文件常量池中CONSTANT_Utf8_info结构里存储常量字符的一块内存区间。
如果你对比着CONSTANT_Integer_info和CONSTANT_Float_info结构也能有所体会,在这两个结构中,也都有bytes,但并不是个bytes[],来看一下:
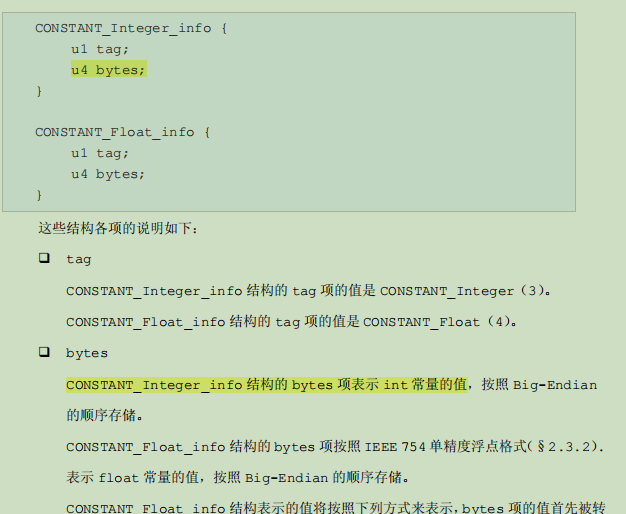
1.2.9
这两个结构里存的也都是常量的值。所以笔者认为bytes没有在堆中去构建数组实例,CONSTANT_Utf8_info结构里的bytes不是一个引用类型,它不算是我们常说的数组,它单单就是存储了改进过的字符串UTF8编码。
运行时常量池
了解
运行时常量池说的更确切一些是Class文件运行时常量池,和Class文件常量池区别之处在于Class文件常量池是静态的(编译时就初始化好了),在运行时常量池是动态的。Class文件中的常量池,用于存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后存放到方法区的运行时常量池,经过解析(resolve)之后,也就是把符号引用替换为直接引用,解析过程会去查询字符串常量池,以保证运行时常量池所引用的字符串与字符串常量池中所引用的是一致的。运行时常量池每个类只有一个,被所有类的实例共享。
剖析运行时常量池
SE7规范是这么描述运行时常量池的:

2.2.0

2.2.1
运行时Java虚拟机为每一个类都维护了一个运行时常量池。当类或接口创建时,class文件常量池(constan_pool)被用来构造运行时常量池。接下来我们还是以上面代码段1.2.0进行剖析str和str2在运行时常量池中的形态:
1 // 引自 代码的1.2.0 2 3 public static void main(String[] args) { 4 String str = "Hello"; 5 String str2 = new String("Bey"); 6 } 7 8 // 字节码 9 public static void main(java.lang.String[]); 10 Code: 11 0: ldc #2 // String Hello 12 2: astore_1 13 3: new #3 // class java/lang/String 14 6: dup 15 7: ldc #4 // String Bey 16 9: invokespecial #5 // Method java/lang/String."<init>":(Ljava/lang/String;)V 17 12: astore_2 18 13: return
依旧只关心和String有关的运行时常量池描述):

2.2.2
图2.2.1中所说:"这些符号引用来自于类或接口的二进制表示的如下结构中" 这句话的意思是,接下来将罗列有哪几种符号引用,这些符号引用自于类/接口的某个结构,如方法、属性等(这个结构是用二进制表示的)。
图2.2.2中所说:"字符常量表示String类实例的一个引用,它来自于类或接口二进制表示的CONSTANT_String_info结构",这句话意思就是说,String类实例的一个符号引用,来自于类或接口二进制表示的CONSTANT_String_info结构中。也就是说CONSTANT_String_info除了tag,string_index之外还有一个东西就是符号引用,它指向了String类的实例。
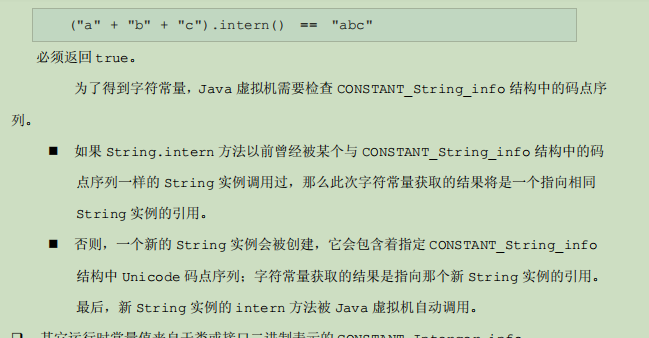
2.2.3
这一张图的意思就是说相同字面量的字符串应该指向同一个String对象地址。
现在回想一下:
1 String str = "Hello"; 2 String str2 = new String("Bey");
String字面量在编译时存入了Class文件常量池,也就是说"Hello"和"Bey"值编译时已经被加入了池中(即值存入CONSTANT_String_info->CONSTANT_Utf8_info#bytes),而new String("Bey")编译后是new class java/lang/String,走的是图1.2.2所示的结构,生成了一个符号引用,这个符号引用就是String类的全限定名(class java/lang/String)。整个过程下来也就是两个字面量(Hello和Bey)和一个符号引用(引用String类),这个符号引用对应的项里的string_index为Bey字面量对应项的索引。当类创建时整个Class文件常量池放入了运行时常量池。即图1.2.3被放入了运行时常量池。
好了,从说运行时常量池开始就强调了:"当接口或类创建时",才有的class运行时常量池。那抛出知乎上
2.2.0:String字面量是何时进入 字符串常量池 ?
好,接下来我们来剖析这个问题,读完R神和诸位知乎大佬们的文章后,心中一万个明镜,如R神所说,字面量"Bey"在类加载阶段(resolve阶段)会先去字符串常量池中查找有没有eauqls("Bey")的引用指向的对象,如果有就直接返回该引用,如果没有就在堆中创建一个对象,然后将该对象的引用驻留在字符串常量池。当程序在执行到new String("Bey")时会在堆中创建一个新的对象,然后将这个新对象的引用返回给str2。带着R神的指导,执行以下代码按理说应该都是false,但是jdk7下执行第一个却是true?
// 代码段2.2.0 public static void main(String[] args) { String s1 = new String("1") + new String("1"); s1.intern(); String s2 = "11"; System.out.println(s1 == s2); // true String s3 = new String("2") + new String("2"); String s4 = "22"; s3.intern(); System.out.println(s3 == s4); // false }
当类加载时1和11字面量在堆中创建,然后都在字符串常量池中驻留了引用地址,当代码执行到s3.intern()时发现字符串常量池已经存在了equals("11")的引用指向的对象,但这里并没有接收intern的返回值,按理说s3还是应该指向执行 行2 代码时堆中新建的11对象而不是类加载时创建的11对象,所以它俩肯定不相等!但是返回结果却为true。我一度在思考类加载时是不是创建并驻留了11,还是说这个intern另有玄机?
想知道String字面量是在什么时候创建的,这要从Java虚拟机规范SE7 pdf的第五章看起。类的创建包括三个阶段:加载、链接、初始化,链接又包括验证、准备、解析(resolve)三个阶段。和问题有着最直接的关联是这个链接 - 解析过程。

2.2.4
在虚拟机规范SE7中,并没有强制要求厂商一定要在链接时就解析下图中的指令,给定建议是Java虚拟机可以选择只有在用到某个符号引用时采取逐一解析它。

2.2.5

2.2.6

2.2.7
带着上面的建议,我们看解析过程,解析过程说了:执行上述任何一条指令在类创建过程中都需要对它的符号引用进行解析。根据规范确实应该这样,但大多数虚拟机厂商(HotSport)都是采用:当Java虚拟机解析遇到以上指令时,在用到某个符号引用时才去解析它,而不是预先解析。
也就是说类加载过程里的解析遇到上面这些指令可以采用延迟解析策略,只有用到某个符号引用才去解析它,那我们来看代码1.2.0里的字节码内容:
// 引自 代码1.2.0里字节码内容 public static void main(String[] args) { String str = "Hello"; String str2 = new String("Bey"); } public static void main(java.lang.String[]); Code: 0: ldc #2 // String Hello 2: astore_1 3: new #3 // class java/lang/String 6: dup 7: ldc #4 // String Bey 9: invokespecial #5 // Method java/lang/String."<init>":(Ljava/lang/String;)V 12: astore_2 13: return
以上ldc、invokespecial这两个都属于解析里的指令,按延迟加载理念,在类加载时,并不创建"Hello"和"Bey"字面量在堆中对应的实例,只有真正用到这个实例引用时才去解析创建它对应的实例。而new指令所对应的符号引用class java/lang/String会在不会被解析,解析期会解析String这个类,解析完后把符号引用替换为直接引用,之前是符号class java/lang/String表示引用这个类,解析完后就直接引用这个String类了(属于三种引用类型里的类类型),运行时常量池里存的已经不再是class java/lang/String这个符号了,而是String类的二进制表示,解析完后下次就不需要再次解析了。
在来看代码段2.2.0,我们把他拆分开来,一个一个的看:
// 代码段2.2.1 // intern放在s2声明之前 public static void main(String[] args) { String s1 = new String("1") + new String("1"); s1.intern(); String s2 = "11"; // System.out.println(s1 == s2); // true } // 生成的字节码如下: public static void main(java.lang.String[]); Code: 0: new #2 // class java/lang/StringBuilder 3: dup 4: invokespecial #3 // Method java/lang/StringBuilder."<init>":()V 7: new #4 // class java/lang/String 10: dup 11: ldc #5 // String 1 13: invokespecial #6 // Method java/lang/String."<init>":(Ljava/lang/String;)V 16: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder; 19: new #4 // class java/lang/String 22: dup 23: ldc #5 // String 1 25: invokespecial #6 // Method java/lang/String."<init>":(Ljava/lang/String;)V 28: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder; 31: invokevirtual #8 // Method java/lang/StringBuilder.toString:()Ljava/lang/String; 34: astore_1 35: aload_1 36: invokevirtual #9 // Method java/lang/String.intern:()Ljava/lang/String; 39: pop 40: ldc #10 // String 11 42: astore_2 43: return
字节码有点长,我们一点一点解析,按照延迟加载的JVM考虑,上图ldc、invokespecial、invokevirtual指令都延迟加载,那也就是类加载时堆内存没有去创建1和11字面量对象,在程序运行时:
- 创建StringBuilder对象,new字节码指令只负责把实例创建出来(包括分配空间、设定类型、所有字段设置默认值等工作),并且把执向新创建对象的引用压到操作数栈顶。此时该引用还不能直接使用,处于uninitialized状态(未初始化),能堆为初始化状态的引用做的唯一一件事就是通过它调用实例构造器,在Class文件层面表现为特殊初始化方法"<init>"。
- 在实际调用前要把需要的参数按顺序压到操作数栈上,压参数的指令有很多,常见的ldc是将一个常量压到操作数栈上,dup指令可以赋值操作数栈栈顶的一个字,再将这个字压入栈(也就是对栈顶的内容做了备份,此时操作数栈上有连续相同的两个对象地址)。对于新建的StringBuilder对象来说并没有传递任何参数,所以它只用一条dup指令把隐藏参数(新建实例对象的引用,对于构造器来说就是“this”)压到操作数栈上。
- 执行invokespecial指令,之前是延迟解析,当真正调用的时候,解析该符号引用,即解析StringBuilder的构造方法,解析完后在运行时常量池替换为直接引用,当构造函数完成之后,此刻,新创建的StringBuilder实例引用就可以使用了。
- 创建String对象A和创建StringBuilder对象类似,只不过在执行invokerspecial指令前除了把隐藏参数传入外还传入了一个常量值1,这个1从哪来的?回想前面说过的,在编译的时候,就已经将1这个值放入了CONSTANT_Utf8_info的bytes里,而new String("1")以CONSTANT_String_info结构放入Class文件常量池,它的string_index为刚才那个CONSTANT_utf8_info的索引,CONSTANT_String_info还有一项符号引用class /java/lang/String,之前说过new指令不会延迟解析,所以Class文件被解析期就被解析过了,在创建这个对象A时又有两条指令都是延迟解析的第一条ldc,第二条才是invokespecial。
- 按顺序来,先执行dup将隐藏参数压入操作数栈,然后执行ldc指令,执行这条指令时发现这是一个常量,对于常量JVM会把它放入字符串常量池中,什么时候放?就是现在,ldc指令将常量压入栈顶,查看常量池是否有equal("1")的引用,没有,在堆中创建一个String对象B,B的值来自运行时常量池1对应项CONSTANT_Utf8_info结构里的bytes,创建完后,将对象B的引用驻留到字符串常量池。至此ldc也被解析了。
- 接下来执行创建A对象的invokespecial方法,解析它,执行它,该方法执行完,A对象创建完成。
- 接下来我们直接跳到第31行,在StringBuilder apped两个字符串对象后,调用了toString方法,这个方法会创建一个新的对象。
1 // 代码段2.2.2 2 3 @Override 4 public String toString() { 5 // Create a copy, don't share the array 6 return new String(value, 0, count); 7 }
-
- 此时此刻append完后的"11"字符串并不是常量,它是字符串变量,在调用toString方法后,只是在堆中创建了一个值为“11”的新对象C,这个“11”没有被驻留到字符串常量池,因为它不是常量,也不会使用ldc指令。此刻s1指向对象C的引用。最后使用astore弹出对象C的引用,注意这个对象C不是StringBuilder,而是StringBuilder调用toString后生成的新对象。
- 在执行intern时,又将对象C的引用压入栈(aload),执行intern方法,在jdk7中,这个方法会先去字符串常量池中查找有没有equals("11")的引用,如果有直接返回该引用,没有的话,将对象C的引用驻留在字符串常量池,然后返回对象C的引用。刚才第7步说了,StringBuilder里的11是字符串变量,没有在字符串常量池驻留,所以,对象C的引用被驻留在字符串常量池,然后pop指令将对象C弹出。注意:这个方法是有返回值的。
- 又是一条ldc指令,之前延迟解析,运行到这一行后发现没有被解析,开始解析,先查看字符串常量池有没有equals("11")的引用,有直接返回该引用,没有就创建驻留并返回引用。在第8步中,对象C.equals("11"常量)为true,所以,直接弹出(astore)对象C的引用,s2指向对象C的引用。
- 结果就是s1和s2都指向了对象C的引用,所以它俩相等。
1 // 代码段2.2.3 2 3 // intern放在s2声明之后 4 public static void main(String[] args) { 5 String s3 = new String("2") + new String("2"); 6 String s4 = "22"; 7 s3.intern(); 8 System.out.println(s3 == s4); // false 9 }
这个的字节码我就不贴出来了,说一下它和上面差异的地方,由于StringBuilder创建的22字符串变量经过toString后得到对象M后并没有在常量池驻留M的引用,s3指向M。执行ldc "22",延迟解析的被解析执行,并没有在常量池中发现有equals("22")的引用,创建新的对象N,将N的引用驻留并返回,s4指向N的引用。指向s3.intern是先查找字符串常量池发现有equals("22")的引用了,返回N的引用,但是并没有变量去接收这个引用,所以s3还是指向M,s4还是指向N。假如说:String s5 = s3.intern(),那无疑s5和s4都指向N。
至此有关字面量何时进入字符串常量池中的问题就已经显现出来了,它确确实实如R神所说,在类加载期(resolve期间),字面量进入字符串常量池,但是并不像我们之前想的那样,以为类一加载完常量就在堆中被创建并驻留。因为解析(resolve)是可以使用延迟解析实现的,只有真正被使用时才会进入字符串常量池中。
字符串常量池
了解
字符串常量池也称全局字符串池,在JDK6.0之前,字符串常量池放在Perm Gen区(方法区)中,下图Non Heap中的驻留字符串(Interned Strings)的位置。在JDK7.0版本,字符串常量池被移到了堆中(元空间)。
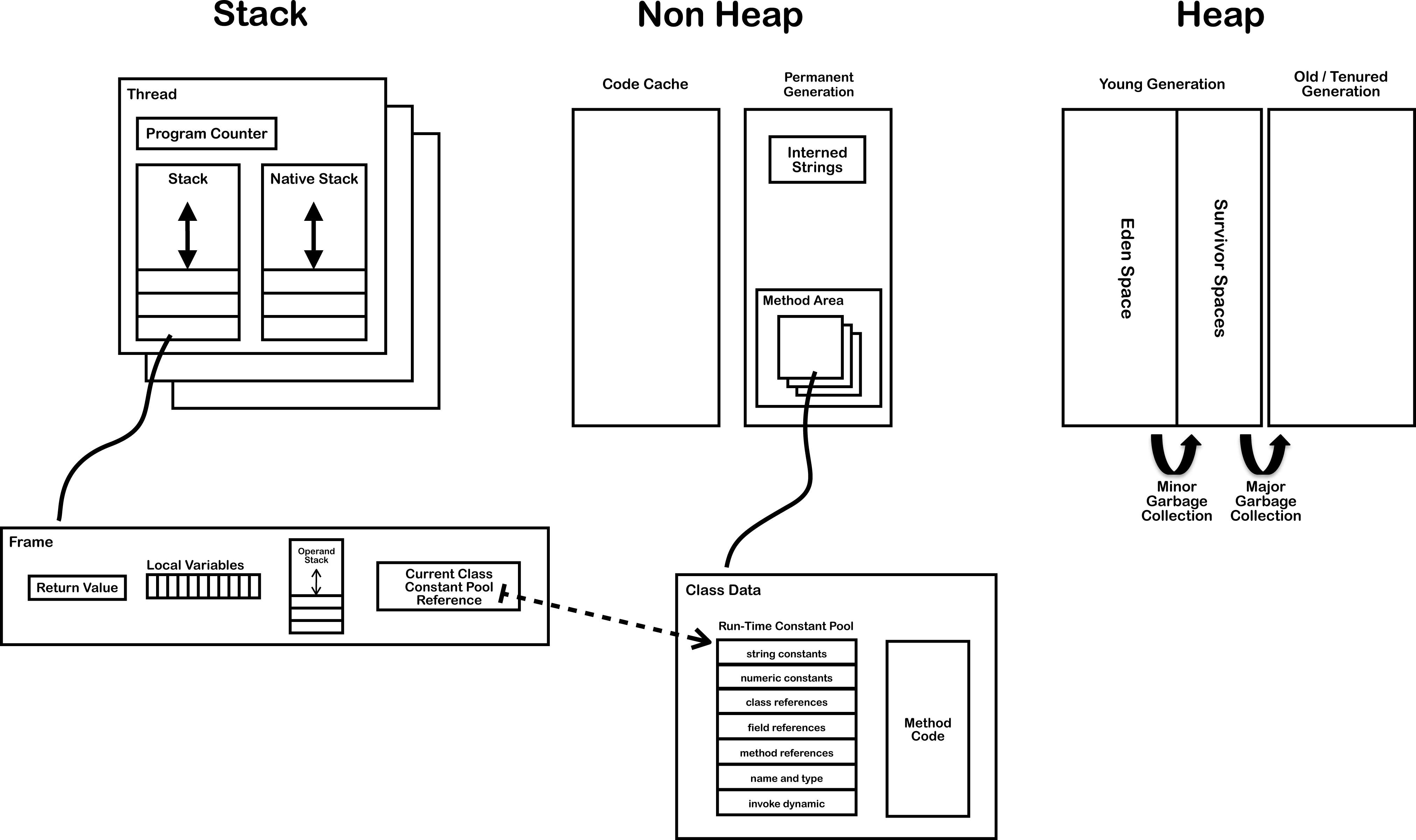
3.1.0
无论字符串常量池是放在非堆还是堆内,可以明确一点的是它是所有线程共享的。在HotSpot VM里实现的String pool功能的是StringTable类,它是一个Hash表,默认长度为1009;这个StringTable在整个HotSport VM里只有一份。在JDK6中,StringTable的长度是固定的,在JDK7中,SstringTable的长度可以通过参数指定。-XX:StringTableSize=66666
在JDK6前,StringPool里存放的都是字符串常量,但在JDK7后,由于String#intern的实现发生了改变,因此在String Pool中存放的是堆内实例的引用。
字面量创建的String对象
1 // 代码段3.1.0 2 public class Test { 3 4 public static void main(String[] args) { 5 String str = "Hello"; 6 } 7 }
如上代码
编译期:JVM启动的时候会对Test类进行编译,编译成Test.class文件之后,如下图:

3.1.1
class文件里的常量池主要存两个东西:字面量 和 符号引用量,其中字面量就是包括类中定义的一些常量,因为str引用的值"Hello"是不可变的,由final关键字修饰过了,所以“Hello”就作为字面量写在了Class文件常量池里。注意:"Hello"在编译期就已经存在于Class文件常量池里了。
预执行期:当JVM准备执行Test.class的时候,会先经过加载、链接、初始化三个阶段,加载过程中,Test.class文件的信息就会被解析到内存的方法区【方法区用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器后的代码等数据。】,class文件里常量池会被加载到“运行时常量池”。由于ldc指令的延迟解析,所以这个过程,并没有创建Hello对象。
执行期:JVM解析执行代码,先去字符串常量池里找,看看 有没有 equals("Hello")为true的引用,如果找到了,就在栈区当前栈帧的局部变量表里创建str变量,然后把字符串常量池里对“Hello”对象的引用复制一份给str变量。找不到的话,在heap里重新创建一个对象,然后把引用驻留(intern)到字符串常量池里,然后再把引用地址复制到栈帧的局部变量表。显然在字符串常量池并没有equals("Hello")的引用,所以例子中的“Hello”对象的一个引用会被存到同样在Non Heap区的字符串常量池里,而"Hello"对象本体还是和所有对象一样,创建在Heap区。R大的文章里,测试的结果是在新生代Eden区,是因为一直有一个引用驻留在字符串常量池,所以不会被GC清理掉。这个堆里的Hello对象会生存到整个线程结束。
// 代码段3.1.1 public static void main(String[] args) { String str1 = "Hello"; String str2 = "Hello"; String str3 = "Hello"; }
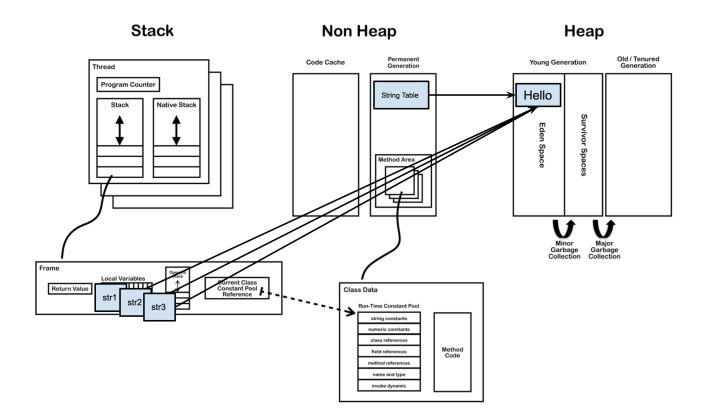
3.1.2
如果定义了很多重复值“Hello”的变量,并不会在堆中增加新的实例,解析st1时就驻留了一个对象,其他在执行的时候,发现有equals为true的,就直接返回了。
new 创建String对象
public static void main(String[] args) { String str = new String("Hello"); // 在运行时创建了几个对象? } // 字节码 public static void main(java.lang.String[]); Code: 0: new #2 // class java/lang/String 3: dup 4: ldc #3 // String Hello 6: invokespecial #4 // Method java/lang/String."<init>":(Ljava/lang/String;)V 9: astore_1 10: return
new创建的对象A,也是先执行new一个为初始化的对象,然后执行延迟解析指令ldc,使用常量"Hello"创建好对象B后驻留B的引用到字符串常量池,接着继续创建A对象,dup压入隐藏引用和常量值“Hello”,构造函数执行完成,对象A创建完成。
注意每个线程来执行都会创建一个真正的Hello实例,但是第一个线程创建驻留了Hello常量后,之后的线程就不会创建了,但还是会创建自己的真正Hello对象。
在Java语言里,“new”表达式是负责创建实例的,其中会调用构造器去对实例做初始化;构造器自身的返回值类型是void,并不是“构造器返回了新对象的对象的引用”,而是new表达式的值是新创建的对象的引用。对应的,在JVM里,“new”字节码指令只负责把实例创建出来(包括分配空间,设定类型、所有字段设置默认值等工作),并且把指向新创建对象的引用压到操作数栈顶。此时该引用还不能直接使用,处于未初始化状态;如果某方法a含有代码试图通过未初始化状态的引用来调用任何实例方法,那么方法a会通不过JVM的字节码校验,从而被JVM拒绝执行。
能对未初始化状态的引用做的唯一一种事情就是通过它调用实例构造器,在Class文件层面表现为特殊初始化方法“<init>”。实际调用的指令是invokespecial,而在实际调用前要把需要的参数按顺序压到操作数栈上。在上面的字节码例子中,压参数的指令包括dup和ldc两条,分别把隐藏参数(新创建的实例的引用,对于实例构造器来说就是“this”)与显示声明的第一个实际参数("Hello"常量的引用)压到操作数栈上,接下来调用了String构造方法。在构造器返回后,新创建的实例的引用就可以正常使用了。
最后的最后,给读者留下的案例分析:
JDK1.7下执行:
public class Test { public static void main(String[] args) { String s = new String("1"); s.intern(); String s2 = "1"; System.out.println(s == s2); // false String s3 = new String("1") + new String("1"); s3.intern(); String s4 = "11"; System.out.println(s3 == s4); // true } }
JDK1.6下执行:
public class Test { public static void main(String[] args) { String s = new String("1"); s.intern(); String s2 = "1"; System.out.println(s == s2); // false String s3 = new String("1") + new String("1"); s3.intern(); String s4 = "11"; System.out.println(s3 == s4); // false } }
这里说一下intern方法在JDK1.6和JDK1.7之间的差异:
JDK1.6:intern会将实际对象A拷贝一份放入字符串常量池(拷贝到字符串常量池的对象B已经是新对象了)。
JDK1.7:intern会将实际对象A的引用驻留在字符串常量池。
经过整篇的分析,上面为什么在JDK6和JDK7之间出现差异,我也不想多说了。
