一个Case引入:可以尝试写一写
原始数据表是长这么一个样子:
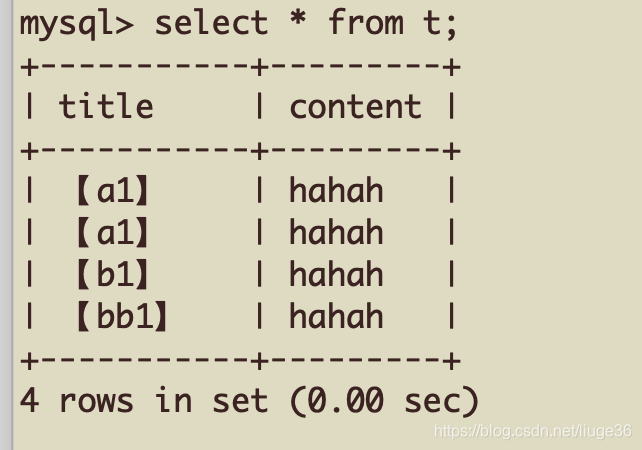
得到结果:

几种SQL:
select SUBSTR(title,2,LENGTH(title)-6) str,count(1) ct from t GROUP BY SUBSTR(title,2,LENGTH(title)-6)
select substring_index(left(title, instr(title,'】')-1),"【",-1) name,count(1) from t group by name;
select replace(replace(title,"【",""),"】","") name,count(1) from t group by name;
上面几种方式都是能够达到结果的。
涉及到的点有:
substring(str, pos),即:substring(被截取字符串, 从第几位开始截取)
substring(str, pos, length),即:substring(被截取字符串,从第几位开始截取(从1开始),截取长度)
SUBSTRING_INDEX
mysql> SELECT SUBSTRING_INDEX('www.liuge36.cn', '.', 3);
+-------------------------------------------+
| SUBSTRING_INDEX('www.liuge36.cn', '.', 3) |
+-------------------------------------------+
| www.liuge36.cn |
+-------------------------------------------+
1 row in set (0.00 sec)
mysql> SELECT SUBSTRING_INDEX('www.liuge36.cn', '.', 2);
+-------------------------------------------+
| SUBSTRING_INDEX('www.liuge36.cn', '.', 2) |
+-------------------------------------------+
| www.liuge36 |
+-------------------------------------------+
1 row in set (0.00 sec)
mysql> SELECT SUBSTRING_INDEX('www.liuge36.cn', '.', 1);
+-------------------------------------------+
| SUBSTRING_INDEX('www.liuge36.cn', '.', 1) |
+-------------------------------------------+
| www |
+-------------------------------------------+
1 row in set (0.00 sec)
# 为-1 则反选
mysql> SELECT SUBSTRING_INDEX('www.liuge36.cn', '.', -1);
+--------------------------------------------+
| SUBSTRING_INDEX('www.liuge36.cn', '.', -1) |
+--------------------------------------------+
| cn |
+--------------------------------------------+
1 row in set (0.00 sec)
# 指定的字符不存在的话,返回整个字符串
mysql> SELECT SUBSTRING_INDEX('www.liuge36.cn', '1111', 1);
+----------------------------------------------+
| SUBSTRING_INDEX('www.liuge36.cn', '1111', 1) |
+----------------------------------------------+
| www.liuge36.cn |
+----------------------------------------------+
1 row in set (0.00 sec)
left(str, length),即:left(被截取字符串, 截取长度)
mysql> SELECT left('www.liuge36.cn',2);
+--------------------------+
| left('www.liuge36.cn',2) |
+--------------------------+
| ww |
+--------------------------+
right(str, length),即:right(被截取字符串, 截取长度)
mysql> SELECT right('www.liuge36.cn',2);
+---------------------------+
| right('www.liuge36.cn',2) |
+---------------------------+
| cn |
+---------------------------+
使用group by分组统计之后,我们的select 后面只能跟着group by 的字段,或者是聚合函数。
CASE WHEN sex = ‘1’ THEN ‘男’
WHEN sex = ‘2’ THEN ‘女’
ELSE ‘其他’ END
行转列 列转行 Case
create table s1(name varchar(20),subject varchar(20),score varchar(20));
insert into s1 values("zhangsan","yuwen","88");
insert into s1 values("zhangsan","math","100");
insert into s1 values("zhangsan","english","99");
insert into s1 values("lisi","english","90");
insert into s1 values("lisi","math","88");
insert into s1 values("lisi","yuwen","100");
create table s2(name varchar(20),yuwen varchar(20),math varchar(20),english varchar(20));
insert into s2 values("zhangsan","88","100","99");
insert into s2 values("lisi","100","88","90");
行转列:
select name,sum(if(`subject`='yuwen',score,0)) yuwen,sum(if(`subject`='math',score,0)) math,sum(if(`subject`='english',score,0)) english from s1 group by name;
SELECT name,
SUM(CASE `subject` WHEN 'yuwen' THEN score ELSE 0 END) as 'yuwen',
SUM(CASE `subject` WHEN 'math THEN score ELSE 0 END) as 'math',
SUM(CASE `subject` WHEN 'english' THEN score ELSE 0 END) as 'english'
FROM s1
GROUP BY name;
可以使用SUM()、MAX()、MIN()、AVG()等聚合函数都可以达到行转列的效果;
列转行:
select name, "yuwen" as "subject" ,`yuwen` as score from s2
union all
select name, "math" as "subject" ,`math` as score from s2
union all
select name, "english" as "subject" ,`english` as score from s2
order by name;
每个人 对应的多个科目的成绩 单独查出来,通过UNION ALL将结果集加起来
UNION与UNION ALL的区别(摘):
1.对重复结果的处理:UNION会去掉重复记录,UNION ALL不会;
2.对排序的处理:UNION会排序,UNION ALL只是简单地将两个结果集合并;
3.效率方面的区别:因为UNION 会做去重和排序处理,因此效率比UNION ALL慢很多;
时间相关
昨天
SELECT * FROM 表名 WHERE TO_DAYS( NOW( ) ) - TO_DAYS( 时间字段名) <= 1
7天
SELECT * FROM 表名 where DATE_SUB(CURDATE(), INTERVAL 7 DAY) <= date(时间字段名)
近30天
SELECT * FROM 表名 where DATE_SUB(CURDATE(), INTERVAL 30 DAY) <= date(时间字段名)
本月
SELECT * FROM 表名 WHERE DATE_FORMAT( 时间字段名, '%Y%m' ) = DATE_FORMAT( CURDATE( ) , '%Y%m' )
上一月
SELECT * FROM 表名 WHERE PERIOD_DIFF( date_format( now( ) , '%Y%m' ) , date_format( 时间字段名, '%Y%m' ) ) =1
参考:https://juejin.im/post/5d3f9cc1f265da03a31d1192
https://www.cnblogs.com/xiaoxi/p/7151433.html