一、简介
cgroups 的全称是control groups,是Linux内核提供的一种可以限制、记录、隔离进程组所使用的物理资源(包括:CPU、memory、IO等)的手段,目前越来越火的轻量级容器 Docker 就使用了 cgroups 提供的资源限制能力来完成cpu,内存等部分的资源控制。
1.1、Cgroups提供了以下功能:
限制进程组可以使用的资源(Resource limiting ):比如memory子系统可以为进程组设定一个memory使用上限,进程组使用的内存达到限额再申请内存,就会出发OOM(out of memory)
进程组的优先级控制(Prioritization ):比如可以使用cpu子系统为某个进程组分配cpu share
记录进程组使用的资源量(Accounting ):比如使用cpuacct子系统记录某个进程组使用的cpu时间
进程组隔离(Isolation):比如使用ns子系统可以使不同的进程组使用不同的namespace,以达到隔离的目的,不同的进程组有各自的进程、网络、文件系统挂载空间
进程组控制(Control):比如使用freezer子系统可以将进程组挂起和恢复
1.2、CGroup的术语
- task:任务就是系统的一个进程
- control group:控制族群就是按照某种标准划分的进程。Cgroups 中的资源控制都是以控制族群为单位实现。一个进程可以加入到某个控制族群,也从一个进程组迁移到另一个控制族群。一个进程组的进程可以使用 cgroups 以控制族群为单位分配的资源,同时受到 cgroups 以控制族群为单位设定的限制;
- hierarchy:控制族群可以组织成 hierarchical 的形式,既一颗控制族群树。控制族群树上的子节点控制族群是父节点控制族群的孩子,继承父控制族群的特定的属性;
- subsystem:一个子系统就是一个资源控制器,比如 cpu 子系统就是控制 cpu 时间分配的一个控制器。子系统必须附加(attach)到一个层级上才能起作用,一个子系统附加到某个层级以后,这个层级上的所有控制族群都受到这个子系统的控制。
1.3、cgroups子系统
cgroups为每种可以控制的资源定义了一个子系统。典型的子系统介绍如下:
cpu 子系统,主要限制进程的 cpu 使用率。
cpuacct 子系统,可以统计 cgroups 中的进程的 cpu 使用报告。 cpuset 子系统,可以为 cgroups 中的进程分配单独的 cpu 节点或者内存节点。 memory 子系统,可以限制进程的 memory 使用量。 blkio 子系统,可以限制进程的块设备 io。 devices 子系统,可以控制进程能够访问某些设备。 net_cls 子系统,可以标记 cgroups 中进程的网络数据包,然后可以使用 tc 模块(traffic control)对数据包进行控制。 freezer 子系统,可以挂起或者恢复 cgroups 中的进程。 ns 子系统,可以使不同 cgroups 下面的进程使用不同的 namespace。
1.4、相互关系
- 每次在系统中创建新层级时,该系统中的所有任务都是那个层级的默认 cgroup(我们称之为 root cgroup,此 cgroup 在创建层级时自动创建,后面在该层级中创建的 cgroup 都是此 cgroup 的后代)的初始成员;
- 一个子系统最多只能附加到一个层级;
- 一个层级可以附加多个子系统;
- 一个任务可以是多个 cgroup 的成员,但是这些 cgroup 必须在不同的层级;
- 系统中的进程(任务)创建子进程(任务)时,该子任务自动成为其父进程所在 cgroup 的成员。然后可根据需要将该子任务移动到不同的 cgroup 中,但开始时它总是继承其父任务的 cgroup。
如图所示,CPU 和 Memory 两个子系统有自己独立的层级系统,而又通过 Task Group 取得关联关系

二. cgroup 工作原理
2.1 cgroups如何判断资源超限及超出限额之后的措施
内存memory子系统,mm_struct结构体激励所属的cgroup,当进程需要申请更多的内存时,就会触发cgroup用量检测,用量超过cgroup规定的限额,则拒绝用户的内存申请
三. cgroup 结构体分析
3.1、task_struct 结构体
从进程的角度出发来剖析 cgroups 相关数据结构之间的关系。在 Linux 中管理进程的数据结构是 task_struct。cgroup表示进程的行为控制.因为subsys必须要知道进程是位于哪一个cgroup,所以在struct task_struct和cgroup中存在一种映射
struct task_struct { …… …… #ifdef CONFIG_CGROUPS /* Control Group info protected by css_set_lock */ struct css_set *cgroups; /* cg_list protected by css_set_lock and tsk->alloc_lock */ struct list_head cg_list; #endif …… …… }
cgroups 指针指向了一个 css_set (cgroups subsystem set)结构,而css_set 存储了与进程有关的 cgroups 信息。cg_list 是一个嵌入的 list_head 结构,用于将连到同一个 css_set 的进程组织成一个链表。
3.2、css_set结构体
- refcount 是该 css_set 的引用数,因为一个 css_set 可以被多个进程公用,只要这些进程的 cgroups 信息相同,比如:在所有已创建的层级里面都在同一个 cgroup 里的进程
- hlist 是嵌入的 hlist_node,用于把所有 css_set 组织成一个 hash 表,这样内核可以快速查找特定的 css_set
- tasks 指向所有连到此 css_set 的进程连成的链表
- cg_links 指向一个由 struct_cg_cgroup_link 连成的链表
- Subsys 是一个指针数组,存储一组指向 cgroup_subsys_state 的指针。一个cgroup_subsys_state 就是进程与一个特定子系统相关的信息。通过这个指针数组,进程就可以获得相应的 cgroups 控制信息了。
struct css_set { atomic_t refcount; struct hlist_node hlist; struct list_head tasks; struct list_head cg_links; struct cgroup_subsys_state *subsys[CGROUP_SUBSYS_COUNT]; struct rcu_head rcu_head; };
3.3、cgroup_subsys_state 结构体
struct cgroup_subsys_state { struct cgroup *cgroup; atomic_t refcnt; unsigned long flags; struct css_id *id; };
cgroup 指针指向了一个 cgroup 结构,也就是进程属于的 cgroup。进程受到子系统的控制,实际上是通过加入到特定的 cgroup 实现的,因为 cgroup 在特定的层级上,而子系统又是附和到上面的。通过以上三个结构,进程就可以和 cgroup 连接起来了:task_struct->css_set->cgroup_subsys_state->cgroup。
3.4、cgroup结构体
- sibling,children 和 parent 三个嵌入的 list_head 负责将统一层级的 cgroup 连接成一棵 cgroup 树。
- subsys 是一个指针数组,存储一组指向 cgroup_subsys_state 的指针。这组指针指向了此 cgroup 跟各个子系统相关的信息
- root 指向了一个 cgroupfs_root 的结构,就是cgroup 所在的层级对应的结构体。
struct cgroup { unsigned long flags; atomic_t count; struct list_head sibling; struct list_head children; struct cgroup *parent; struct dentry *dentry; struct cgroup_subsys_state *subsys[CGROUP_SUBSYS_COUNT]; struct cgroupfs_root *root; struct cgroup *top_cgroup; struct list_head css_sets; struct list_head release_list; struct list_head pidlists; struct mutex pidlist_mutex; struct rcu_head rcu_head; struct list_head event_list; spinlock_t event_list_lock; };
3.5、cg_cgroup_link 结构体
- cgrp_link_list 连入到 cgrouo->css_set 指向的链表,cgrp 指向此 cg_cgroup_link 相关的 cgroup。
- cg_link_list 连入到 css_set->cg_links 指向的链表,cg 指向此 cg_cgroup_link 相关的 css_set。
- cgroup 和 css_set 是多对多的关系,须添加一个中间结构来将两者联系起来,这就是 cg_cgroup_link 的作
- cg_cgroup_link 中的 cgrp 和 cg 就是此结构提的联合主键,而 cgrp_link_list 和 cg_link_list 分别连入到 cgroup 和 css_set 相应的链表,使得能从 cgroup 或 css_set 都可以进行遍历查询。
struct cg_cgroup_link { struct list_head cgrp_link_list; struct cgroup *cgrp; struct list_head cg_link_list; struct css_set *cg;
};
四、为什么 cgroup 和 css_set 是多对多的关系?
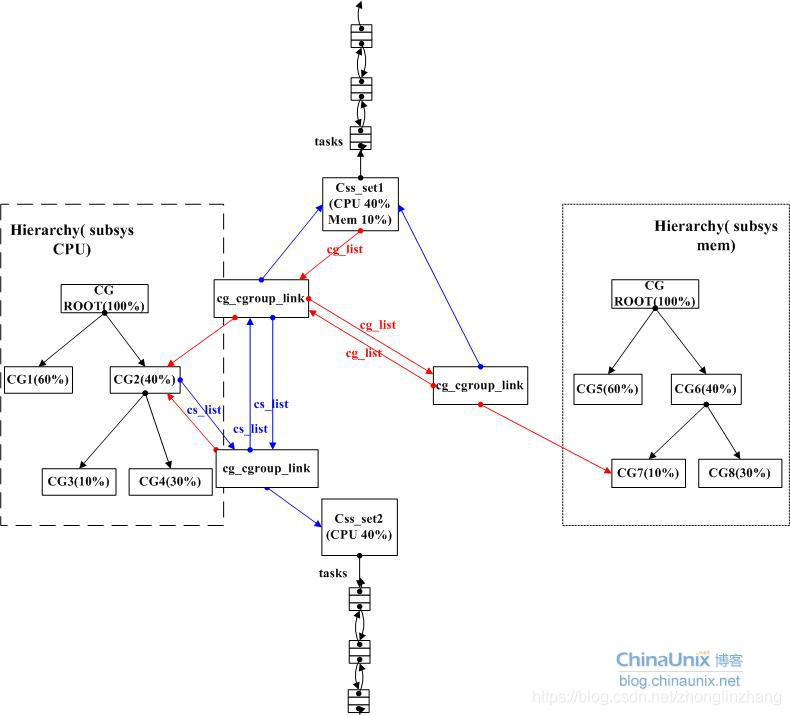
一个进程对应一个 css_set,一个 css_set 存储了一组进程 (有可能被多个进程共享,所以是一组) 跟各个子系统相关的信息,但是这些信息由可能不是从一个 cgroup 那里获得的,
因为一个进程可以同时属于几个 cgroup,只要这些 cgroup 不在同一个层级。
五、cgroup 文件系统实现
VFS虚拟文件系统转换,处理与Unix标准文件系统的所有系统调用。VFS对用户提供统一的读写接口,用户调用读写等函数时,内核则调用特定的文件系统实现。文件在内核内存中是一个file数据结构来表示的。这个数据结构包含一个f_op的字段,该字段中包含了一组指向特定文件系统实现的函数指针。当用户执行read()操作时,内核调用sys_read(),然后sys_read()查找到指向该文件属于的文件系统的读函数指针,并调用它,即file->f_op->read().
基于VFS实现的文件系统,都必须实现定义这些对象,并实现这些对象中定义的函数指针。
cgroup文件系统的定义:
static struct file_system_type cgroup_fs_type = { .name = "cgroup", .get_sb = cgroup_get_sb, .kill_sb = cgroup_kill_sb, };
这里有定义了两个函数指针,定义了一个文件系统必须实现了的两个操作get_sb,kill_sb,即获得超级块和释放超级块。这两个操作会在使用mount系统调用挂载cgroup文件系统时使用。
5.1、CPU资源控制
CPU资源的控制也有两种策略
一种是完全公平调度 (CFS:Completely Fair Scheduler)策略,提供了限额和按比例分配两种方式进行资源控制; 另一种是实时调度(Real-Time Scheduler)策略,针对实时进程按周期分配固定的运行时间。配置时间都以微秒(µs)为单位,文件名中用us表示。
- CFS调度策略下的配置
- 设定CPU使用周期使用时间上限
- cpu.cfs_period_us:设定周期时间,必须与cfs_quota_us配合使用。
- cpu.cfs_quota_us :设定周期内最多可使用的时间。这里的配置指task对单个cpu的使用上限,若cfs_quota_us是cfs_period_us的两倍,就表示在两个核上完全使用。数值范围为1000 - 1000,000(微秒)。
- cpu.stat:统计信息,包含nr_periods(表示经历了几个cfs_period_us周期)、nr_throttled(表示task被限制的次数)及throttled_time(表示task被限制的总时长)。
- 按权重比例设定CPU的分配
- cpu.shares:设定一个整数(必须大于等于2)表示相对权重,最后除以权重总和算出相对比例,按比例分配CPU时间。(如cgroup A设置100,cgroup B设置300,那么cgroup A中的task运行25%的CPU时间。对于一个4核CPU的系统来说,cgroup A 中的task可以100%占有某一个CPU,这个比例是相对整体的一个值。)
- RT调度策略下的配置 实时调度策略与公平调度策略中的按周期分配时间的方法类似,也是在周期内分配一个固定的运行时间。
cpu.rt_period_us :设定周期时间。
cpu.rt_runtime_us:设定周期中的运行时间。
5.1、cpuacct资源报告
这个子系统的配置是cpu子系统的补充,提供CPU资源用量的统计,时间单位都是纳秒。
cpuacct.usage:统计cgroup中所有task的cpu使用时长
cpuacct.stat:统计cgroup中所有task的用户态和内核态分别使用cpu的时长
cpuacct.usage_percpu:统计cgroup中所有task使用每个cpu的时长
5.2、cpuset
为task分配独立CPU资源的子系统,参数较多,这里只选讲两个必须配置的参数,同时Docker中目前也只用到这两个。
cpuset.cpus:可使用的CPU编号,如0-2,16代表 0、1、2和16这4个CPU cpuset.mems:与CPU类似,表示cgroup可使用的memory node,格式同上,NUMA系统使用
5.3、device ( 限制task对device的使用)
设备黑/白名单过滤
devices.allow:允许名单,语法type device_types:node_numbers access type ;type有三种类型:b(块设备)、c(字符设备)、a(全部设备);access也有三种方式:r(读)、w(写)、m(创建)
devices.deny:禁止名单,语法格式同上
统计报告
devices.list:报告为这个 cgroup 中的task设定访问控制的设备
5.4、freezer - 暂停/恢复cgroup中的task
只有一个属性,表示进程的状态,把task放到freezer所在的cgroup,再把state改为FROZEN,就可以暂停进程。不允许在cgroup处于FROZEN状态时加入进程。freezer.state 包括如下三种状态:
- - FROZEN 停止
- - FREEZING 正在停止,这个是只读状态,不能写入这个值。
- - THAWED 恢复
5.5、memory (内存资源管理)
memory.limit_bytes:强制限制最大内存使用量,单位有k、m、g三种,填-1则代表无限制
memory.soft_limit_bytes:软限制,只有比强制限制设置的值小时才有意义
memory.memsw.limit_bytes:设定最大内存与swap区内存之和的用量限制
memory.oom_control: 0表示开启,当cgroup中的进程使用资源超过界限时立即杀死进程。默认包含memory子系统的cgroup都启用。当oom_control不启用时,实际使用内存超过界限时进程会被暂停直到有空闲的内存资源
统计
memory.usage_bytes:报告该 cgroup中进程使用的当前总内存用量(以字节为单位) memory.max_usage_bytes:报告该 cgroup 中进程使用的最大内存用量 memory.failcnt:报告内存达到在 memory.limit_in_bytes设定的限制值的次数 memory.stat:包含大量的内存统计数据。 cache:页缓存,包括 tmpfs(shmem),单位为字节。 rss:匿名和 swap 缓存,不包括 tmpfs(shmem),单位为字节。 mapped_file:memory-mapped 映射的文件大小,包括 tmpfs(shmem),单位为字节 pgpgin:存入内存中的页数 pgpgout:从内存中读出的页数 swap:swap 用量,单位为字节 active_anon:在活跃的最近最少使用(least-recently-used,LRU)列表中的匿名和 swap 缓存,包括 tmpfs(shmem),单位为字节 inactive_anon:不活跃的 LRU 列表中的匿名和 swap 缓存,包括 tmpfs(shmem),单位为字节 active_file:活跃 LRU 列表中的 file-backed 内存,以字节为单位 inactive_file:不活跃 LRU 列表中的 file-backed 内存,以字节为单位 unevictable:无法再生的内存,以字节为单位 hierarchical_memory_limit:包含 memory cgroup 的层级的内存限制,单位为字节 hierarchical_memsw_limit:包含 memory cgroup 的层级的内存加 swap 限制,单位为字节
六、Docker: 限制容器可用的 CPU
6.1、通过 --cpus 选项指定容器可以使用的 CPU 个数,这个还是默认设置了cpu.cfs_period_us(100000)和cpu.cfs_quota_us(200000)
docker run -it --rm --cpus 2 harbor.master.online.local/library/centos:7.2-base /bin/bash
# 安装压测工具 yum install -y stress
# stress工具使用说明
https://www.cnblogs.com/liugp/p/14854737.html
容器中执行: stress -c 5,查看容器使用资源情况,容器 CPU 的负载为 200%,理解为单个 CPU 负载的两倍。也可以把它理解为有两颗 CPU 在 100% 工作

宿主机top查看,5个 CPU 的负载都是 40%,加起来容器消耗的 CPU 总量就是两个 CPU 100% 的负载,不过CPU多了,靠系统来调度分配CPU
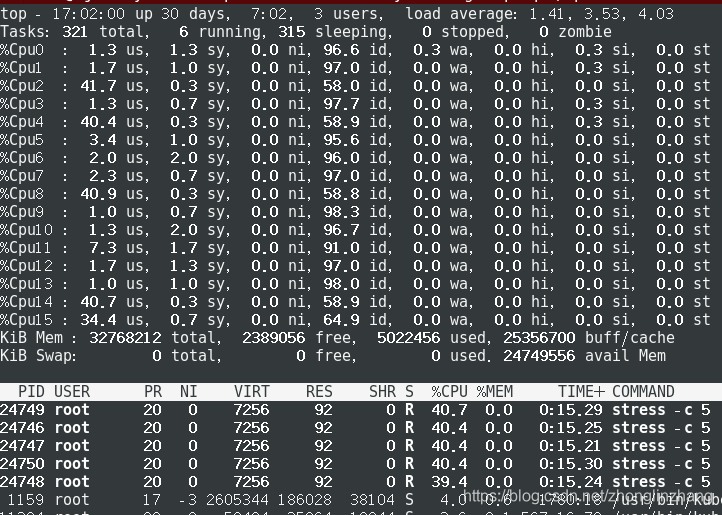
总结: 对于进程没有 CPU 个数概念,内核只能通过进程消耗的 CPU 时间片来统计出进程占用 CPU 的百分比。
6.2、指定固定的 CPU
通过 --cpuset-cpus 选项可以固定到指定CPU,现在的多核系统中每个核心都有自己的缓存,如果频繁的调度进程在不同的核心上执行势必会带来缓存失效等开销
运行容器: docker run -it --rm --cpuset-cpus=1 harbor.master.online.local/library/centos:7.2-base /bin/bash 执行压测:stress -c 5
查看容器状态:

宿主机查看cpu占用情况,五个进程占用一个指定的CPU

七、Docker、LXC、Cgroup的结构关系
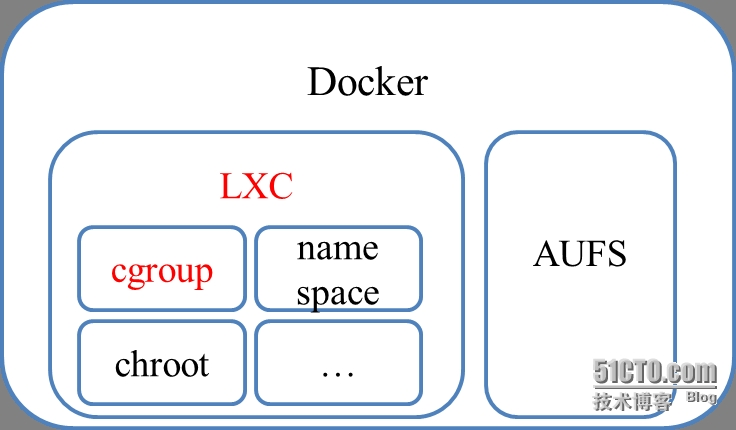
根据Docker布道师Jerome Petazzoni的说法,Docker约等于LXC+AUFS(AUFS 是一种 Union File System(联合文件系统))(之前只支持ubuntu时)(作者2015-10-22更新:Docker0.9.0版本开始引入libcontainer,可以视作LXC的替代品)。其中LXC负责资源管理,AUFS负责镜像管理;而LXC包括cgroup、namespace、chroot等组件,并通过cgroup进行资源管理。所以只从资源管理这条线来看的话,Docker、LXC、Cgroup三者的关系是:Cgroup在最底层落实资源管理,LXC在cgroup上封装了一层,Docker又在LXC封装了一层,关系图如图1(b)所示。因此,要想玩转Docker,有必要了解负责资源管理的CGroup和LXC。
7.1、LXC基本概念
LXC(LinuxContainer)容器可以提供轻量级的虚拟化,以便隔离进程和资源,而且不需要提供指令解释机制以及全虚拟化的其他复杂性。容器有效地将由单个操作系统管理的资源划分到孤立的组中,以更好地在孤立的组之间平衡有冲突的资源使用需求。
LXC建立在CGroup基础上,我们可以粗略的认为LXC = Cgroup+ namespace + Chroot + veth +用户态控制脚本。LXC利用内核的新特性(CGroup)来提供用户空间的对象,用来保证资源的隔离和对于应用或者系统的资源控制。