理解:tensorflow神经网络框架,主要运算部分在ts在外进行。可以简单的理解为:写出公式----执行会话----送出运算
一.简单矩阵乘法运算
1.张量:多维数组
0阶张量:123
1阶张量:[1,2,3] 数组列表
2阶张量:[[1,2,3],[4,5,6],[7,8,9]] 矩阵3X3
[[1,2,3]] 矩阵1X3
[[1],[2],[3]] 矩阵3X1
n阶张量:[[[[[[[[````````]]]]]]]]右边括号数
2.实现矩阵的乘法:写出公式,执行会话
import tensorflow as tf
x = tf.constant([[1,2,3]]) ###定义x矩阵 1x3
w = tf.constant([[4],[5],[6]]) ###定义w矩阵 3x1
y = tf.matmul(x,w) ###定义矩阵乘法 y = xw
with tf.compat.v1.Session() as sess: ###用with调用会话开始计算
print(sess.run(y)) ###运行结果[[32]] 只有一个值二阶张量(矩阵)
二.神经网络
非线性回归:
- 1.数据准备--特征提取
- 2.前向传播:先写公式,再会话执行
- 3.反向传播:特征数据喂给NN,优化权重w参数
- 4.使用训练好的模型预测和分类
模块导入
import tensorflow as tf import numpy as np import matplotlib.pyplot as plt import tushare as ts
1.数据准备
通过 y=x^2+随机数生成模拟的输入数据
x_data = np.linspace(-0.5, 0.5, 200)[:, np.newaxis] noise = np.random.normal(0, 0.02, x_data.shape) y_data = np.square(x_data) + noise
说明:np.linspace(-0.5,0.5,200)在-0.5到0.5间生成200个等差数列 得到一维数组
np.linspace(-0.5, 0.5, 200)[:, np.newaxis] 将一维数组转化成矩阵
比如:数组 a1= [1 2 3 4 5 ] shape:(5,)
矩阵 a2 = a1[:, np.newaxis] shape:(5,1) 5行1列矩阵
矩阵 a3 = a1[np.newaxis, :] shape:(1,5) [[1 2 3 4 5]] 1行5列矩阵
2.(前向传播)写出公式,搭建NN y = xw+b
输入层:单个神经元的形状shape: 1x1向量(矩阵、这里是单个数字)
中间层:这里设置10个神经元:L1= xw1+b1 所以权重形状 1x10 偏置形状1x10
输出层:输出单个神经元形状shape:1x1向量 L2= L1w2+b2 1x10 10x1 = 1 x 1
定义占位符,用于批量接受输入
# 定义两个placeholder x = tf.compat.v1.placeholder(tf.float32, [None, 1]) y = tf.compat.v1.placeholder(tf.float32, [None, 1])
定义隐藏层:L1= softmax(xw1+b1)
# 定义神经网络中间层 单个一维输入(一个神经元) 扩展到10维(10个神经元)
W1 = tf.Variable(tf.random.normal([1, 10])) b1 = tf.Variable(tf.zeros([1, 10])) SL1 = tf.matmul(x, W1) + b1 L1 = tf.nn.tanh(SL1)
定义输出层:L2 = softmax(L1w2+b2)
# 定义神经网络输出层 10维(10个神经元) 降低至 1维(一个神经元)预测 W2 = tf.Variable(tf.random.normal([10, 1])) b2 = tf.Variable(tf.zeros([1, 1])) SL2 = tf.matmul(L1, W2) + b2 prediction = tf.nn.tanh(SL2)
关于激活函数:nn.tanh()
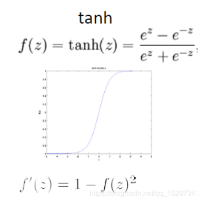
3.(反向传播)通过最小化损失函数(代价函数loss)不断优化权重w值
理解:输入x通过神经元计算后输出y,这个y值与实际值y_data的误差最小化
loss = tf.reduce_mean(tf.square(y - prediction))
说明:均方误差:(1/n)*(y-y_data)^2
最小化:通过梯度下降的方法最小化loss值
train_step = tf.compat.v1.train.GradientDescentOptimizer(0.2).minimize(loss)
说明:此代码中的0.2代表学习率,代表梯度下降迭代步移动的大小,学习率也可以设置成变量,随着迭代的进度调整(后面的文章再进行详细分解)
4.执行会话,将NN框架中的公式,打包由底层代码进行运算
4.1初始化变量
权重值w1,w2,偏置值b1、b2在NN框架中只是写出了初始化的公式,并没有真实 赋值,初始化就是运行公式,为权重和偏置进行赋值。
将准备好的输入数据,喂入NN网络,以feed_dict=字典的形式喂入:同一组数据输入,通过10000次训练(自定义,此处为100000)
with tf.compat.v1.Session() as sess:
# 变量初始化
sess.run(tf.compat.v1.global_variables_initializer())
for _ in range(10000):
sess.run(train_step, feed_dict={x: x_data, y: y_data})
在会话中可以print()计算过程中的值:比如 预测值
prediction_value = sess.run(prediction, feed_dict={x: x_data})
可视化:
# 获得预测值
prediction_value = sess.run(prediction, feed_dict={x: x_data})
# 画图
plt.figure()
plt.scatter(x_data, y_data) ###散点图
plt.plot(x_data, prediction_value, 'r-', lw=5) ##曲线图
plt.show()