摘要:
1.以动态图形式计算一个简单的加法
2.cpu和gpu计算力比较(包括如何指定cpu和gpu)
3.关于gpu版本的tensorflow安装问题,可以参考另一篇博文:https://www.cnblogs.com/liuhuacai/p/11684666.html
正文:
1.在tensorflow中计算3.+4.
##1.创建输入张量 a = tf.constant(2.) b = tf.constant(4.) ##2.计算结果 print('a+b=',a+b)
输出:a+b= tf.Tensor(7.0, shape=(), dtype=float32)
总结:20版本在加法实现过程中简单了不少,所见即所得。(1.x的实现过程相对复杂)据说动态的实现也是后端转化成静态图实现的。
2.cpu和gpu计算力比较
说明:通过计算不同大小的矩阵乘法,获得计算时间。
1.指定cpu或gpu通过 with tf.device('/cpu:0'):或 with tf.device('/gpu:0'):指定,在需要加速的操作前添加即可(此处生成随机 数和矩阵乘法都加速)
2.统计计算时间的函数timeit.timeit需要导入import timeit【timeit.timeit(需计时的函数或语句,计算次数)】
3.计算量的大小与cpu和gpu计算时间的关系,计算量通过改变矩阵大小实现
import tensorflow as tf import timeit 以矩阵A[10,n]和矩阵B[n,10]的乘法运算(分别在cpu和gpu上运行)来测试, ''' with tf.device('/cpu:0'): ##指定操作用cpu计算 cpu_a = tf.random.normal([10,n]) ##生成符合高斯分布的随机数矩阵,通过改变n大小,增减计算量 cpu_b = tf.random.normal([n,10]) print(cpu_a.device,cpu_b.device) with tf.device('/gpu:0'): gpu_a = tf.random.normal([100n]) gpu_b = tf.random.normal([n,10]) print(gpu_a.device,gpu_b.device) def cpu_run(): with tf.device('/cpu:0'): ##矩阵乘法,此操作采用cpu计算 c = tf.matmul(cpu_a,cpu_b) return c def gpu_run(): with tf.device('/gpu:0'): ##矩阵乘法,此操作采用gpu计算 c = tf.matmul(gpu_a,gpu_b) return c ##第一次计算需要热身,避免将初始化时间计算在内 cpu_time = timeit.timeit(cpu_run,number=10) gpu_time = timeit.timeit(gpu_run,number=10) print('warmup:',cpu_time,gpu_time) ##正式计算10次,取平均值 cpu_time = timeit.timeit(cpu_run,number=10) gpu_time = timeit.timeit(gpu_run,number=10) print('run_time:',cpu_time,gpu_time)
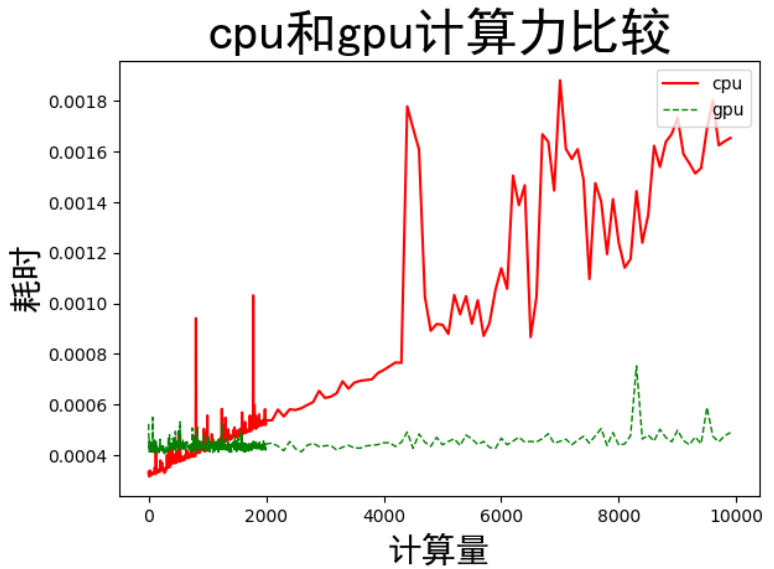
通过改变矩阵大小,增加矩阵乘法的计算量:计算结果如下
结论:1.在计算量较小的情况下,cpu的计算速度比gpu计算速度快,但是都是微量级别的差异
2.随着计算量的增加,cpu的计算时间逐步增加,而gpu的计算时间相对平缓,在计算量达到一定程度之后,gpu的优势就出来了。
实现过程的完整代码:
import tensorflow as tf import timeit import matplotlib.pyplot as plt ''' 以矩阵A[10,n]和矩阵B[n,10]的乘法运算(分别在cpu和gpu上运行)来测试, ''' def cpu_gpu_compare(n): with tf.device('/cpu:0'): ##指定操作用cpu计算 cpu_a = tf.random.normal([10,n]) ##生成符合高斯分布的随机数矩阵,通过改变n大小,增减计算量 cpu_b = tf.random.normal([n,10]) print(cpu_a.device,cpu_b.device) with tf.device('/gpu:0'): gpu_a = tf.random.normal([10,n]) gpu_b = tf.random.normal([n,10]) print(gpu_a.device,gpu_b.device) def cpu_run(): with tf.device('/cpu:0'): ##矩阵乘法,此操作采用cpu计算 c = tf.matmul(cpu_a,cpu_b) return c def gpu_run(): with tf.device('/gpu:0'): ##矩阵乘法,此操作采用gpu计算 c = tf.matmul(gpu_a,gpu_b) return c ##第一次计算需要热身,避免将初始化时间计算在内 cpu_time = timeit.timeit(cpu_run,number=10) gpu_time = timeit.timeit(gpu_run,number=10) print('warmup:',cpu_time,gpu_time) ##正式计算10次,取平均值 cpu_time = timeit.timeit(cpu_run,number=10) gpu_time = timeit.timeit(gpu_run,number=10) print('run_time:',cpu_time,gpu_time) return cpu_time,gpu_time n_list1 = range(1,2000,5) n_list2 = range(2001,10000,100) n_list = list(n_list1)+list(n_list2) time_cpu =[] time_gpu =[] for n in n_list: t=cpu_gpu_compare(n) time_cpu.append(t[0]) time_gpu.append(t[1]) plt.plot(n_list,time_cpu,color = 'red',label='cpu') plt.plot(n_list,time_gpu,color='green',linewidth=1.0,linestyle='--',label='gpu') plt.ylabel('耗时',fontproperties = 'SimHei',fontsize = 20) plt.xlabel('计算量',fontproperties = 'SimHei',fontsize = 20) plt.title('cpu和gpu计算力比较',fontproperties = 'SimHei',fontsize = 30) plt.legend(loc='upper right') plt.show()