go语言
提倡:所见即所得
支持高并发的原因:
Go语言的聚合类型(结构体和数组)可以直接操 作它们的元素,只需要更少的存储空间、更少的内存写操作,而且指针操作比其他间接操作 的语言也更有效率。由于现代计算机是一个并行的机器,Go语言提供了基于CSP的并发特性支持。Go语言的动态栈使得轻量级线程goroutine的初始栈可以很小,因此,创建一个 goroutine的代价很小,创建百万级的goroutine完全是可行的。
package main经过编译后可以得到一个可执行的二进制文件,那么该文件必有一个main函数,是整个程序的入口
不是main包,则是工具类等文件
函数外只能放一些变量的声明,函数的声明,类型的声明
go语言是静态类型语言。
python2不支持utf-8类型,也就是不支持中文编码。
标识符
在编程语言中标识符就是程序员定义的具有特殊意义的词,比如变量名、常量名、函数名等等。 Go语言中标识符由字母数字和_(下划线)组成,并且只能以字母和_开头。 举几个例子:abc, _, _123, a123。
全局变量定义之后可以不使用,也能编译通过
go语言有类型推导
var ss = "string"
还有简单变量声明,只能在函数中使用
ss := "string" // 隐式使用类型推导
同一作用域不能重复声明同一个变量
常量
不变的量,由const关键字定义,定义之后不能被重新赋值,pi,状态码
const (
n1 = 200
n2
n3 //不定义默认等于上面的值
)
iota在const关键字出现时将被重置为0。const中每新增一行常量声明将使iota计数一次(iota可理解为const语句块中的行索引)。 使用iota能简化定义,在定义枚举时很有用。
定义数量级 (这里的<<表示左移操作,1<<10表示将1的二进制表示向左移10位,也就是由1变成了10000000000,也就是十进制的1024。同理2<<2表示将2的二进制表示向左移2位,也就是由10变成了1000,也就是十进制的8。)
const (
_ = iota
KB = 1 << (10 * iota)
MB = 1 << (10 * iota)
GB = 1 << (10 * iota)
TB = 1 << (10 * iota)
PB = 1 << (10 * iota)
)
字符串
go语言双引号包裹的是字符串,单引号包裹的是字符。
c1 := "string"
c2 := 's'
//字节,一个字节等于8Bit
反引号间换行将被作为字符串中的换行,但是所有的转义字符均无效,文本将会原样输出。
fmt.Sprintf // 有返回值,做字符串拼接
当需要处理中文、日文或者其他复合字符时,则需要用到rune类型。rune类型实际是一个int32。
Go 使用了特殊的 rune 类型来处理 Unicode,让基于 Unicode 的文本处理更为方便,也可以使用 byte 型进行默认字符串处理,性能和扩展性都有照顾。
s2 := "白色" //['白' '色']
s3 := []rune(s2) //把字符串强制转换成一个rune切片
// s3[0] = "红" // 报错,这是字符串
s3[0] = '红' // OK
c1 := "红" // string
c2 := '红' // rune(int32)
fmt.Printf("c1:%T c2:%T
", c1, c2)
for循环
Go语言中可以使用for range遍历数组、切片、字符串、map 及通道(channel)。 通过for range遍历的返回值有以下规律:
- 数组、切片、字符串返回索引和值。
- map返回键和值。
- 通道(channel)只返回通道内的值。
数组
go定义数组,需要定义数组的长度和元素的类型,一旦定义就不会再变,数组的长度是数组类型的一部分。
//不定义长度,根据初始值自动推断数组的长度
a1 := [...]int{1,2,3,4,5}
a2 := [5]int{0:1, 4:2}
数组是值类型(拷贝类型):把文档从目录a,拷贝到目录b,修改拷贝后各自的内容,均不改变对方的结果。
切片
cap(),容量
切片指向了一个底层数组,它是动态的,是引用类型(快捷方式),修改底层数组,切片的值也会发生改变,修改切片的值,底层数据也会发生改变。
切片的容量是指底层数组的容量,容量的大小是从切片的第一个元素开始,到数组中最后一个元素的大小。
var a1 [8]int
s1 := a1[0 : 3]
s2 := a1[3 : 6]
fmt.Println(len(s1), cap(s1)) //3, 8
fmt.Println(len(s2), cap(s2)) //3, 5
切片不能直接比较
切片之间是不能比较的,我们不能使用==操作符来判断两个切片是否含有全部相等元素。 切片唯一合法的比较操作是和nil比较。 一个nil值的切片并没有底层数组,一个nil值的切片的长度和容量都是0。但是我们不能说一个长度和容量都是0的切片一定是nil,例如下面的示例:
var s1 []int //len(s1)=0;cap(s1)=0;s1==nil
s2 := []int{} //len(s2)=0;cap(s2)=0;s2!=nil
s3 := make([]int, 0) //len(s3)=0;cap(s3)=0;s3!=nil
所以要判断一个切片是否是空的,要是用len(s) == 0来判断,不应该使用s == nil来判断。
切片相关函数
append:append的结果必须用变量来接收
a := []int{1, 2, 3, 4, 5}
//a = append(a[:2])
//fmt.Println(a) // [1 2]
a = append(a[:2], a[3:]...) // ...就是把切片拆开的意思
fmt.Println(a)
copy:拷贝后的结果,更改其中的值对原来的切片没有影响,使用copy的时候,destslice必须指定长度,否则拷贝后的值为0
a1 := []int{1,2,3}
a2 := a1
var a3 = make([]int, 3, 3) // 需要指定destslice切片的长度
copy(a3, a1)
指针
go语言不存在指针操作,两个关于指针的符号:&,*。
&: 取地址*:根据地址取值
new函数申请一个内存地址,一般是个基本数据类型申请内存,int,string,bool,返回的是对应类型的指针。
make也是用于内存分配的,只作用于slice,map,以及chan,make函数返回的是对应的这三个类型的本身。
map
Go语言中提供的映射关系容器为map,其内部使用散列表(hash)实现。
map是一种无序的基于key-value的数据结构,Go语言中的map是引用类型,必须初始化才能使用。
初始化:在内存中开辟内存空间
var m1 map[string]int //没有初始化,nil
m1 = make(map[string]int, 10) //要估算好map的容量,避免在程序运行期间再动态扩容
value, ok := m1["迪丽热巴"]
if !ok{
fmt.Println("查无此key")
} else {
fmt.Println(value)
}
切片和map的定义
// 切片
var a []int
// map
map[string]int
切片和map一定要初始化
// 元素为map的切片
var s1 = make(map[int]string, 10, 20)
s1[0] = make([int]string, 1)
// 值为切片类型的map
var s2 = make(map[string][]int, 10)
函数
函数的定义,可以没有参数,没有返回值,返回值可以命名可以不命名。不命名一定要显式的返回。
package main
func name(arg1 string, arg2 int)(res1 string, res2 int){
//code
return res1, res2
}
func name(){
//code
}
func name(arg1 string, arg2 int){
//code
}
func name()(res1 string){
// code
return res1
}
//可变长度参数,该参数必须写在最后,y的类型是切片,可以传可以不传
func name(x int, y ...int){
// code
}
在一函数中不能再命名另一个函数。
defer
defer语句把它后面的语句延迟到函数即将返回的时候再执行,defer执行的时候会把函数和变量的状态都带进去。
比如在文件操作的过程中,就需要将文件关闭,否则占用内存资源,甚至造成内存泄漏。
网络socket,数据库连接的释放,也需要进行关闭的操作,类似于python的close。
多个defer的语句的执行顺序类似于栈,先进后出。
go语言中,函数的return操作不是原子性的,在底层分为两步执行
- 给返回值赋值
- 执行defer后面的语句
- 执行真正的
return操作
package main
func f1() int {
x := 5
defer func(){
x++
}()
return x
}
func main(){
f1() // 5
}
上面的示例,修改的是x的值,在执行defer之前,返回值已经确认好了。
匿名函数
-
函数内部没有办法声明带名字的函数
-
匿名函数一般在函数内部定义和调用
立即执行的匿名函数:定义之后在花括号外加括号执行,常用于只调用了一次的函数
闭包
函数内部提供对函数外部变量的引用。
内置函数
new返回的是指针
make
panic/recover
go语言没有错误处理机制,go把错误也当成值来处理,把每一个错误的值都做显式的处理if else new if else new。
- recover()必须搭配defer使用。
- defer一定要在可能引发panic的语句之前定义
fmt
fmt.scan
func Scan(a ...interface{})(n int, err error)
递归
递归一定要有明确的出口,否则就变成无限循环。
递归适合处理问题相同,规模越来越小的场景,比如:阶乘
自定义类型和类型别名
类型别名只在于代码编写的过程中有效,编译完之后就不存在,内置的byte和rune都属于类型别名。
结构体
结构体是值类型,
指针接收者
- 修改结构体中变量的值,需要使用指针接收者。
- 结构体本身比较大时,拷贝的内存开销比较大时候,也需要用指针。
- 保持一致性:如果有一种方法使用了指针接收者,其他方法为了统一,也需要用指针。
结构体字段的类型后加tag,可以在反序列化时指定输出格式
type person struct {
name string `json:"name" db:"name"`
}
JSON序列化与反序列化
经常出现的问题:
- 结构体内部的字段首字母要大写!!!否则外部无法访问结构体中的字段。
- 反序列化时要传递指针。
接口
接口是一种数据类型。
接口的定义
type 接口名 interface {
方法名1(参数1, 参数2, ...)(返回值1, 返回值2, ...)
方法名2(参数1, 参数2, ...)(返回值1, 返回值2, ...)
}
用来给变量,参数,返回值等设置类型。
接口是一种数据类型。
接口是一种特殊的类型,它规定了变量有哪些方法。
不关心一个变量是什么类型,只关心能调用它的什么方法。
只要实现了接口中的方法的变量,都属于该接口的类型。
type speaker interface {
speak() //方法签名,约束其他调用者需要实现的方法
}
type cat struct {}
type dog struct {}
type person struct {}
func (d dog) speak() {
fmt.Println("dog")
}
func (c cat) speak() {
fmt.Println("cat")
}
func main(){
var c1 cat
var d1 dog
eat(c1)
eat(d1)
//下面会报错,因为person这个结构体没有实现speak这个方法
//不能称之为speaker类型的变量,因此,就不能被当做参数传进去
//var p1 person
//eat(p1)
}
接口的实现
属于接口的类型,必须实现了接口中定义的所有方法。
接口保存分为两部分:
- 值的类型
- 值本身

这样就实现了接口变量能够存储不同的值。
使用值接收者实现接口与使用指针接收者实现接口的区别?
使用值接收者实现接口,结构体类型和结构体指针类型的变量都能存。
使用指针接收者实现接口,只能存结构体指针类型的变量。
同一个结构体可以实现多个接口。
type mover interface{
move()
}
type eater interface{
eat()
}
type (c *cat) move(){
pass
}
type (c *cat) move(){
pass
}
接口还可以嵌套。
空接口
没有必要取名字,通常以如下形式定义
interface{}
所有类型都实现了空接口,因此任意类型的变量都能保存到空接口中。
func main(){
m1 := map[string]interface{}
}
使用空接口可以实现保存任意值的字典。
func main(){
var m1 map[string]interface{}
m1["name"] = "xx"
m1["age"] = 18
m1["hobbies"] = ["唱", "跳", "rap"]
}
类型断言
方式一:
func assign(a interface{}){
switch t := a.(type){
case string:
fmt.Println("是string")
case int:
fmt.Println("是int")
case bool:
fmt.Println("是bool")
}
}
方式二:
func assign(a interface{}){
str, ok := a.(string)
if !ok {
fmt.Println("猜错了")
} else {
fmt.Println("是string")
}
}
关于接口
只有当有两个或两个以上的具体类型,必须以相同方式来进行处理时才需要定义接口。不要为了接口而写接口,这样只会增加不必要的抽象,导致不必要的运行时损耗。
包
标识符
包中的标识符(变量名函数名结构体接口等),如果首字母是小写,表示私有(只能在当前这个包中使用)。
首字母大写的标识符可以被外部的包调用。
go中的路径是以$GOPATH下的src开始的。
package main
import (
"fmt"
xx "code.golang.com/day05/10calc" //xx是别名
)
按照go语言的规范,包名不能以数字开头,目录名和包名最好保持一致。
go语言中,禁止循环导入包。
导入包不想使用包内的标识符,需要使用匿名导入。
每个包导入的时候会自动执行一个名为init()的函数。
每个包中只有一个init()
init()初始化函数
init()函数介绍
在Go语言程序执行时导入包语句会自动触发包内部init()函数的调用。需要注意的是: init()函数没有参数也没有返回值。 init()函数在程序运行时自动被调用执行,不能在代码中主动调用它。
包初始化执行的顺序如下图所示: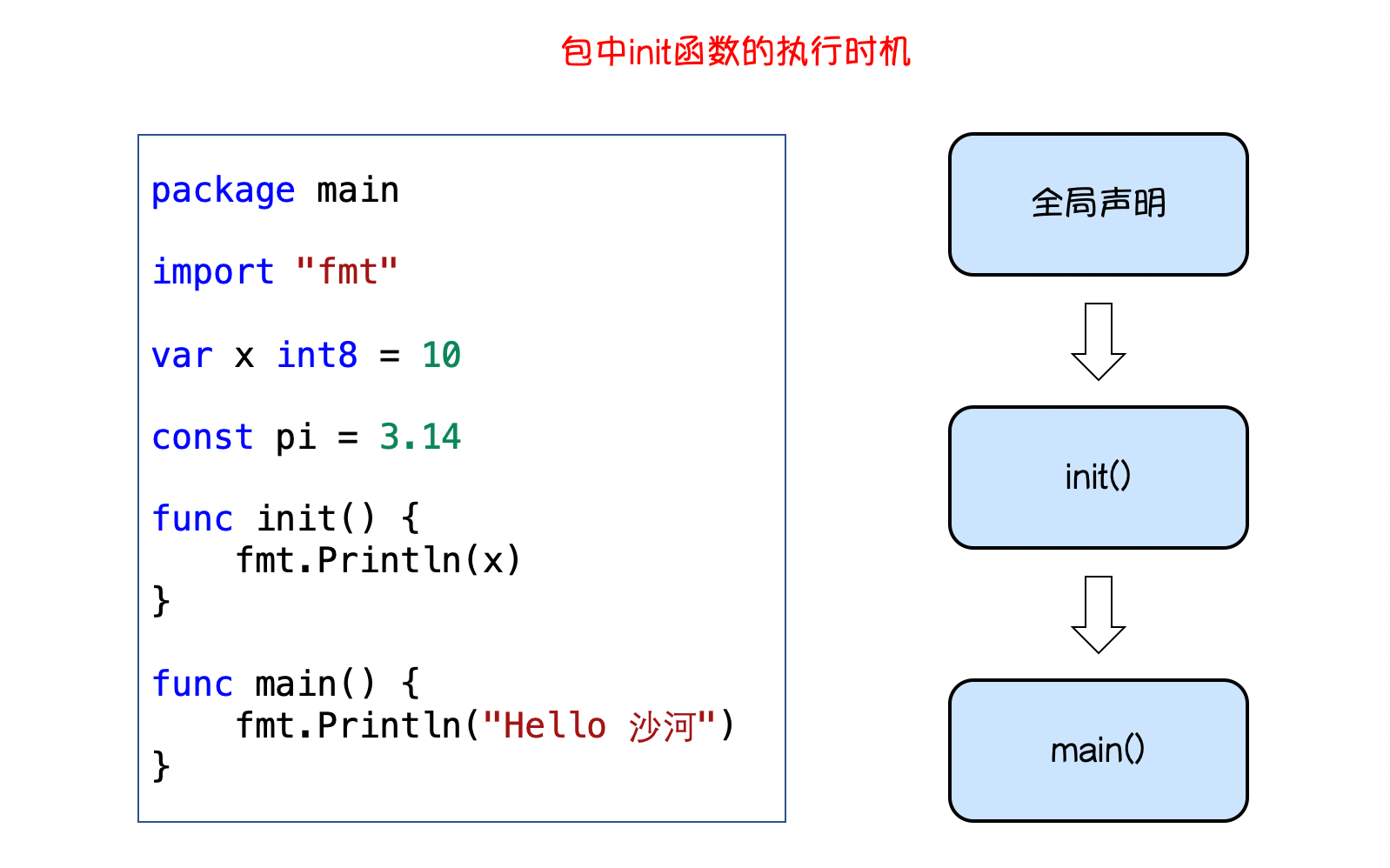
init()函数执行顺序
Go语言包会从main包开始检查其导入的所有包,每个包中又可能导入了其他的包。Go编译器由此构建出一个树状的包引用关系,再根据引用顺序决定编译顺序,依次编译这些包的代码。
在运行时,被最后导入的包会最先初始化并调用其init()函数, 如下图示:
反射
反射给变量赋值一定要加上Elem()函数。
并行与并发
go语言的并发通过goroutine实现,goroutine类似于线程,属于用户态的线程,比操作系统的线程更轻量级。 goroutine是go语言运行时(runtime)调度完成的,而线程是由操作系统调度完成的。
go语言还提供channel在多个grouting间通信,goroutine和channel是go语言秉承的CSP并发模式的重要实现基础。
goroutine什么时候结束?
goroutine对应的函数结束了,goroutine就结束了。
main函数执行完了,由main函数创建的那些goroutine都结束了。
启动多个goroutine
在Go语言中实现并发就是这样简单,我们还可以启动多个goroutine。让我们再来一个例子: (这里使用了sync.WaitGroup来实现goroutine的同步)
var wg sync.WaitGroup
func hello(i int) {
defer wg.Done() // goroutine结束就登记-1
fmt.Println("Hello Goroutine!", i)
}
func main() {
for i := 0; i < 10; i++ {
wg.Add(1) // 启动一个goroutine就登记+1
go hello(i)
}
wg.Wait() // 等待所有登记的goroutine都结束
}
多次执行上面的代码,会发现每次打印的数字的顺序都不一致。这是因为10个goroutine是并发执行的,而goroutine的调度是随机的。
可增长的栈
OS线程(操作系统线程)一般都有固定的栈内存(通常为2MB),一个goroutine的栈在其生命周期开始时只有很小的栈(典型情况下2KB),goroutine的栈不是固定的,他可以按需增大和缩小,goroutine的栈大小限制可以达到1GB,虽然极少会用到这个大。所以在Go语言中一次创建十万左右的goroutine也是可以的。
goroutine调度
GPM是Go语言运行时(runtime)层面的实现,是go语言自己实现的一套调度系统。区别于操作系统调度OS线程。
G很好理解,就是个goroutine的,里面除了存放本goroutine信息外 还有与所在P的绑定等信息。P管理着一组goroutine队列,P里面会存储当前goroutine运行的上下文环境(函数指针,堆栈地址及地址边界),P会对自己管理的goroutine队列做一些调度(比如把占用CPU时间较长的goroutine暂停、运行后续的goroutine等等)当自己的队列消费完了就去全局队列里取,如果全局队列里也消费完了会去其他P的队列里抢任务。M(machine)是Go运行时(runtime)对操作系统内核线程的虚拟, M与内核线程一般是一一映射的关系, 一个groutine最终是要放到M上执行的;
P与M一般也是一一对应的。他们关系是: P管理着一组G挂载在M上运行。当一个G长久阻塞在一个M上时,runtime会新建一个M,阻塞G所在的P会把其他的G 挂载在新建的M上。当旧的G阻塞完成或者认为其已经死掉时 回收旧的M。
P的个数是通过runtime.GOMAXPROCS设定(最大256),Go1.5版本之后默认为物理线程数。 在并发量大的时候会增加一些P和M,但不会太多,切换太频繁的话得不偿失。
单从线程调度讲,Go语言相比起其他语言的优势在于OS线程是由OS内核来调度的,goroutine则是由Go运行时(runtime)自己的调度器调度的,这个调度器使用一个称为m:n调度的技术(复用/调度m个goroutine到n个OS线程)。 其一大特点是goroutine的调度是在用户态下完成的, 不涉及内核态与用户态之间的频繁切换,包括内存的分配与释放,都是在用户态维护着一块大的内存池, 不直接调用系统的malloc函数(除非内存池需要改变),成本比调度OS线程低很多。 另一方面充分利用了多核的硬件资源,近似的把若干goroutine均分在物理线程上, 再加上本身goroutine的超轻量,以上种种保证了go调度方面的性能。
go通过runtime.GOMAXPROCS()可以指定运行时CPU的数量,可以提高运行效率。
var wg sync.WaitGroup
func f1() {
defer wg.Done()
for i := 0; i < 100; i++ {
fmt.Printf("A:%d
", i)
}
}
func f2() {
defer wg.Done()
for i := 0; i < 100; i++ {
fmt.Printf("B:%d
", i)
}
}
func main() {
runtime.GOMAXPROCS(6)
wg.Add(2)
go f1()
go f2()
wg.Wait()
}
Go语言中的操作系统线程和goroutine的关系:
- 一个操作系统线程对应用户态多个goroutine。
- go程序可以同时使用多个操作系统线程。
- goroutine和OS线程是多对多的关系,即m:n。
互斥锁
读写互斥锁
适合读多写少的场景
goroutine调度模型
-
GMP
-
M:N:
Java是通过操作系统来实现线程的切换,
go语言是通过goroutine来实现线程的切换,比操作系统去切换效率更高一些。
-
goroutine初始栈的大小是2k,比操作系统创建线程更节省内存
channel
单纯地将函数并发执行是没有意义的。函数与函数间需要交换数据才能体现并发执行函数的意义。
虽然可以使用共享内存进行数据交换,但是共享内存在不同的goroutine中容易发生竞态问题。为了保证数据交换的正确性,必须使用互斥量对内存进行加锁,这种做法势必造成性能问题。
Go语言的并发模型是CSP(Communicating Sequential Processes),提倡通过通信共享内存而不是通过共享内存而实现通信。
如果说goroutine是Go程序并发的执行体,channel就是它们之间的连接。channel是可以让一个goroutine发送特定值到另一个goroutine的通信机制。
Go 语言中的通道(channel)是一种特殊的类型。通道像一个传送带或者队列,总是遵循先入先出(First In First Out)的规则,保证收发数据的顺序。每一个通道都是一个具体类型的导管,也就是声明channel的时候需要为其指定元素类型。
var 通道名 chan 元素类型 //需要指定通道中元素的类型
通道必须初始化才能使用
b = make(chan 元素类型, 缓冲大小)
缓冲大小是可选的
数据比较大的话就传指针,通过内存地址就能找到变量
通道的操作
接收
x := <- ch // 从ch中接收值并赋值给变量x
<- ch // 从ch中接收值,忽略结果
关闭
var once Sync.Once
// 只接受没有参数没有返回值的函数
once.Do() // 遇到有函数有参数和返回值的时候,可以用闭包函数
Sync.Map
注意:内置的map不是并发安全的(超过20个goroutine操作内置的map就会报错)
使用
是一个开箱即用的,不需要初始化。
var syncMap sync.Map
// 原来的写法
// syncMap[key] = value
syncMap.Store(key, value)
syncMap.Load(key)
syncMpa.LoadOrStore()
syncMap.Delete()
syncMap.Range()
原子操作
针对基本数据类型我们还可以使用原子操作来保证并发安全,因为原子操作是Go语言提供的方法它在用户态就可以完成,因此性能比加锁操作更好。Go语言中原子操作由内置的标准库sync/atomic提供。
注意:如果一个方法用了指针接收者,剩下的方法都应该用指针接收者
锁
sync.Mutex
是一个结构体,结构体是值类型,给函数传参要传指针。



context
统一goroutine任务调度的通知格式。

优势
在 Go http包的Server中,每一个请求在都有一个对应的 goroutine 去处理。请求处理函数通常会启动额外的 goroutine 用来访问后端服务,比如数据库和RPC服务。用来处理一个请求的 goroutine 通常需要访问一些与请求特定的数据,比如终端用户的身份认证信息、验证相关的token、请求的截止时间。 当一个请求被取消或超时时,所有用来处理该请求的 goroutine 都应该迅速退出,然后系统才能释放这些 goroutine 占用的资源。
单元测试
proof调试工具
go语言内置的调试工具,分析性能,资源占用等
链表闭环

数据库
var db *sql.DB
type User struct {
id int
name string
age int
}
func initDB(){
}
func main(){
err := initDB()
if err != niu {
fmt.Printf("init db failed, err:%v
", err)
}
fmt.Pirntln("连接成功")
var u1 user
sqlStr := `select id, name, age from user where id=?`
// 1就是id后面的那个问号的值,QueryRow就是从连接池里取出数据库查询单条记录
rowObj := db.QueryRow(sqlStr, 1)
// 拿到rowObj对象,必须调用该对象的Scan方法,因为该方法会释放数据库链接
rowObj.Scan(&u1.id, &u1.name, &u1.age)
fmt.Printf("u1:%#v
", u1)
}
MySQL预处理
普通SQL语句执行过程:
- 客户端对SQL语句进行占位符替换得到完整的SQL语句。
- 客户端发送完整SQL语句到MySQL服务端
- MySQL服务端执行完整的SQL语句并将结果返回给客户端。
预处理执行过程:
- 把SQL语句分成两部分,命令部分与数据部分。
- 先把命令部分发送给MySQL服务端,MySQL服务端进行SQL预处理。
- 然后把数据部分发送给MySQL服务端,MySQL服务端对SQL语句进行占位符替换。
- MySQL服务端执行完整的SQL语句并将结果返回给客户端。
为什么要预处理?
- 优化MySQL服务器重复执行SQL的方法,可以提升服务器性能,提前让服务器编译,一次编译多次执行,节省后续编译的成本。
- 避免SQL注入问题。
kafka
服务注册发现
etcd
使用etcd下的watch函数,可以监控数据发生改变时的操作,可以使用该方法,实现在不用重启服务的情况下,当配置文件发生修改时,自动重新加载配置文件的功能。
Raft协议
etcd的watch
watch底层是如何实现发送课程的
go csp并发机制


go通过os.Exit实现返回状态
测试方法名以Test开头

go不支持隐式类型转换,同时不支持指针的运算
用==比较数组
相同维数且含有相同个数元素的数组才可以比较
每个元素都相同的才相等