1. pprint美观打印数据结构
pprint模块包含一个“美观打印机”,用于生成数据结构的一个美观的视图。格式化工具会生成数据结构的一些表示,不仅能够由解释器正确地解析,还便于人阅读。输出会尽可能放在一行上,分解为多行时会缩进。
1.1 打印
from pprint import pprint data = [ (1, {'a': 'A', 'b': 'B', 'c': 'C', 'd': 'D'}), (2, {'e': 'E', 'f': 'F', 'g': 'G', 'h': 'H', 'i': 'I', 'j': 'J', 'k': 'K', 'l': 'L'}), (3, ['m', 'n']), (4, ['o', 'p', 'q']), (5, ['r', 's', 't''u', 'v', 'x', 'y', 'z']), ] print('PRINT:') print(data) print() print('PPRINT:') pprint(data)
pprint()格式化一个对象,并把它作为参数传入一个数据流(或者是默认的sys.stdout)。

1.2 格式化
要格式化一个数据结构而不是把它直接写入一个流(即用于日志),可以使用pformat()来构建一个字符串表示。
import logging from pprint import pformat data = [ (1, {'a': 'A', 'b': 'B', 'c': 'C', 'd': 'D'}), (2, {'e': 'E', 'f': 'F', 'g': 'G', 'h': 'H', 'i': 'I', 'j': 'J', 'k': 'K', 'l': 'L'}), (3, ['m', 'n']), (4, ['o', 'p', 'q']), (5, ['r', 's', 't''u', 'v', 'x', 'y', 'z']), ] logging.basicConfig( level=logging.DEBUG, format='%(levelname)-8s %(message)s', ) logging.debug('Logging pformatted data') formatted = pformat(data) for line in formatted.splitlines(): logging.debug(line.rstrip())
然后可以单独打印这个格式化的字符串或者记入日志。

1.3 任意类
如果一个定制类定义了一个__repr__()方法,那么pprint()使用的PrettyPrinter类还可以处理这样的定制类。
from pprint import pprint class node: def __init__(self, name, contents=[]): self.name = name self.contents = contents[:] def __repr__(self): return ( 'node(' + repr(self.name) + ', ' + repr(self.contents) + ')' ) trees = [ node('node-1'), node('node-2', [node('node-2-1')]), node('node-3', [node('node-3-1')]), ] pprint(trees)
利用由PrettyPrinter组合的嵌套对象的表示来返回完整的字符串表示。

1.4 递归
递归数据结构由指向原数据源的引用表示,形式为<Recursion on typename with id=number>
from pprint import pprint local_data = ['a', 'b', 1, 2] local_data.append(local_data) print('id(local_data) =>', id(local_data)) pprint(local_data)
在这个例子中,列表local_data增加到其自身,这会创建一个递归引用。
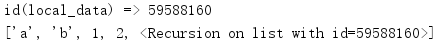
1.5 限制嵌套输出
对于非常深的数据结构,可能不要求输出中包含所有细节。数据有可能没有适当地格式化,也可能格式化文本过大而无法管理,或者有些数据可能是多余的。
from pprint import pprint data = [ (1, {'a': 'A', 'b': 'B', 'c': 'C', 'd': 'D'}), (2, {'e': 'E', 'f': 'F', 'g': 'G', 'h': 'H', 'i': 'I', 'j': 'J', 'k': 'K', 'l': 'L'}), (3, ['m', 'n']), (4, ['o', 'p', 'q']), (5, ['r', 's', 't''u', 'v', 'x', 'y', 'z']), ] pprint(data, depth=1) pprint(data, depth=2)
使用depth参数可以控制美观打印机递归处理嵌套数据结构的深度。输出中未包含的层次用省略号表示。
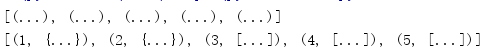
1.6 控制输出宽度
格式化文本的默认输出宽度为80列。要调整这个宽度,可以在pprint()中使用参数width。
from pprint import pprint data = [ (1, {'a': 'A', 'b': 'B', 'c': 'C', 'd': 'D'}), (2, {'e': 'E', 'f': 'F', 'g': 'G', 'h': 'H', 'i': 'I', 'j': 'J', 'k': 'K', 'l': 'L'}), (3, ['m', 'n']), (4, ['o', 'p', 'q']), (5, ['r', 's', 't''u', 'v', 'x', 'y', 'z']), ] for width in [80, 5]: print('WIDTH =', width) pprint(data, width=width) print()
当宽度太小而不能满足格式化数据结构时,倘若截断或转行会导致非法语法,那么便不会截断或转行。

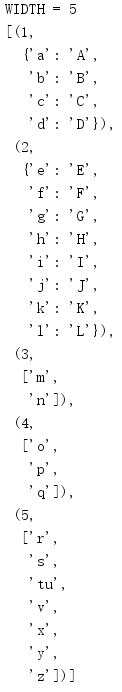
compact标志告诉pprint()尝试在每一行上放置更多数据,而不是把复杂数据结构分解为多行。
from pprint import pprint data = [ (1, {'a': 'A', 'b': 'B', 'c': 'C', 'd': 'D'}), (2, {'e': 'E', 'f': 'F', 'g': 'G', 'h': 'H', 'i': 'I', 'j': 'J', 'k': 'K', 'l': 'L'}), (3, ['m', 'n']), (4, ['o', 'p', 'q']), (5, ['r', 's', 't''u', 'v', 'x', 'y', 'z']), ] for width in [80, 5]: print('WIDTH =', width) pprint(data, width=width) print()
这个例子展示了一个数据结构再一行上放不下时,它会分解(数据列表中的第二项也是如此)。如果多个元素可以放置在一行上(如第三个和第四个成员),那么便会把它们放在同一行上。

