1. functools管理函数的工具
functools模块提供了一些工具来调整或扩展函数和其他callable对象,从而不必完全重写。
1.1 修饰符
functools模块提供的主要工具就是partial类,可以用来“包装”一个有默认参数的callable对象。得到的对象本身就是callable,可以把它看作是原来的函数。它与原函数的参数完全相同,调用时还可以提供额外的位置或命名函数。可以使用partial而不是lambda为函数提供默认参数,有些参数可以不指定。
1.1.1 部分对象
第一个例子显示了函数myfunc()的两个简单partial对象。show_details()的输出中包含这个部分对象(partial object)的func、args和keywords属性。
import functools def myfunc(a, b=2): "Docstring for myfunc()." print(' called myfunc with:', (a, b)) def show_details(name, f, is_partial=False): "Show details of a callable object." print('{}:'.format(name)) print(' object:', f) if not is_partial: print(' __name__:', f.__name__) if is_partial: print(' func:', f.func) print(' args:', f.args) print(' keywords:', f.keywords) return show_details('myfunc', myfunc) myfunc('a', 3) print() # Set a different default value for 'b', but require # the caller to provide 'a'. p1 = functools.partial(myfunc, b=4) show_details('partial with named default', p1, True) p1('passing a') p1('override b', b=5) print() # Set default values for both 'a' and 'b'. p2 = functools.partial(myfunc, 'default a', b=99) show_details('partial with defaults', p2, True) p2() p2(b='override b') print() print('Insufficient arguments:') p1()
在这个例子的最后,调用了之前创建的第一个partial,但没有为a传入一个值,这便会导致一个异常。

1.1.2 获取函数属性
默认的,partial对象没有__name__或__doc__属性。如果没有这些属性,被修饰的函数将更难调试。使用update_wrapper()可以从原函数将属性复制或增加到partial对象。
import functools def myfunc(a, b=2): "Docstring for myfunc()." print(' called myfunc with:', (a, b)) def show_details(name, f): "Show details of a callable object." print('{}:'.format(name)) print(' object:', f) print(' __name__:', end=' ') try: print(f.__name__) except AttributeError: print('(no __name__)') print(' __doc__', repr(f.__doc__)) print() show_details('myfunc', myfunc) p1 = functools.partial(myfunc, b=4) show_details('raw wrapper', p1) print('Updating wrapper:') print(' assign:', functools.WRAPPER_ASSIGNMENTS) print(' update:', functools.WRAPPER_UPDATES) print() functools.update_wrapper(p1, myfunc) show_details('updated wrapper', p1)
增加到包装器的属性在WRAPPER_ASSIGNMENTS中定义,另外WARPPER_UPDATES列出了要修改的值。

1.1.3 其他callable
partial适用于任何callable对象,而不只是独立的函数。
import functools class MyClass: "Demonstration class for functools" def __call__(self, e, f=6): "Docstring for MyClass.__call__" print(' called object with:', (self, e, f)) def show_details(name, f): "Show details of a callable object." print('{}:'.format(name)) print(' object:', f) print(' __name__:', end=' ') try: print(f.__name__) except AttributeError: print('(no __name__)') print(' __doc__', repr(f.__doc__)) return o = MyClass() show_details('instance', o) o('e goes here') print() p = functools.partial(o, e='default for e', f=8) functools.update_wrapper(p, o) show_details('instance wrapper', p) p()
这个例子从一个包含__call__()方法的类实例中创建部分对象。

1.1.4 方法和函数
partial()返回一个可以直接使用的callable,partialmethod()返回的callable则可以用作对象的非绑定方法。在下面的例子中,这个独立函数两次被增加为MyClass的属性,一次使用partialmethod()作为method1(),另一次使用partial()作为method2()。
import functools def standalone(self, a=1, b=2): "Standalone function" print(' called standalone with:', (self, a, b)) if self is not None: print(' self.attr =', self.attr) class MyClass: "Demonstration class for functools" def __init__(self): self.attr = 'instance attribute' method1 = functools.partialmethod(standalone) method2 = functools.partial(standalone) o = MyClass() print('standalone') standalone(None) print() print('method1 as partialmethod') o.method1() print() print('method2 as partial') try: o.method2() except TypeError as err: print('ERROR: {}'.format(err))
method1()可以从MyClass的一个实例中调用,这个实例作为第一个参数传入,这与采用通常方法定义的方法是一样的。method2()未被定义为绑定方法,所以必须显式传递self参数;否则,这个调用会导致TypeError。

1.1.5 获取修饰符的函数属性
更新所包装callable的属性对修饰符尤其有用,因为转换后的函数最后会得到原“裸”函数的属性。
import functools def show_details(name, f): "Show details of a callable object." print('{}:'.format(name)) print(' object:', f) print(' __name__:', end=' ') try: print(f.__name__) except AttributeError: print('(no __name__)') print(' __doc__', repr(f.__doc__)) print() def simple_decorator(f): @functools.wraps(f) def decorated(a='decorated defaults', b=1): print(' decorated:', (a, b)) print(' ', end=' ') return f(a, b=b) return decorated def myfunc(a, b=2): "myfunc() is not complicated" print(' myfunc:', (a, b)) return # The raw function show_details('myfunc', myfunc) myfunc('unwrapped, default b') myfunc('unwrapped, passing b', 3) print() # Wrap explicitly wrapped_myfunc = simple_decorator(myfunc) show_details('wrapped_myfunc', wrapped_myfunc) wrapped_myfunc() wrapped_myfunc('args to wrapped', 4) print() # Wrap with decorator syntax @simple_decorator def decorated_myfunc(a, b): myfunc(a, b) return show_details('decorated_myfunc', decorated_myfunc) decorated_myfunc() decorated_myfunc('args to decorated', 4)
functools提供了一个修饰符wraps(),它会对所修饰的函数应用update_wrapper()。

1.2 比较
在Python 2中,类可以定义一个__cmp__()方法,它会根据这个对象小于、对于或者大于所比较的元素而分别返回-1、0或1.Python 2.1引入了富比较(rich comparison)方法API(__lt__()、__le__()、__eq__()、__ne__()、__gt__()和__ge__()) ,可以完成一个比较操作并返回一个布尔值。Python 3废弃了__cmp__()而代之以这些新的方法,另外functools提供了一些工具,从而能更容易地编写符合新要求的类,即符合Python 3中新的比较需求。
1.2.1 富比较
设计富比较API是为了支持涉及复杂比较的类,以最高效的方式实现各个测试。不过,如果比较相对简单的类,就没有必要手动地创建各个富比价方法了。total_ordering()类修饰符可以为一个提供了部分方法的类增加其余的方法。
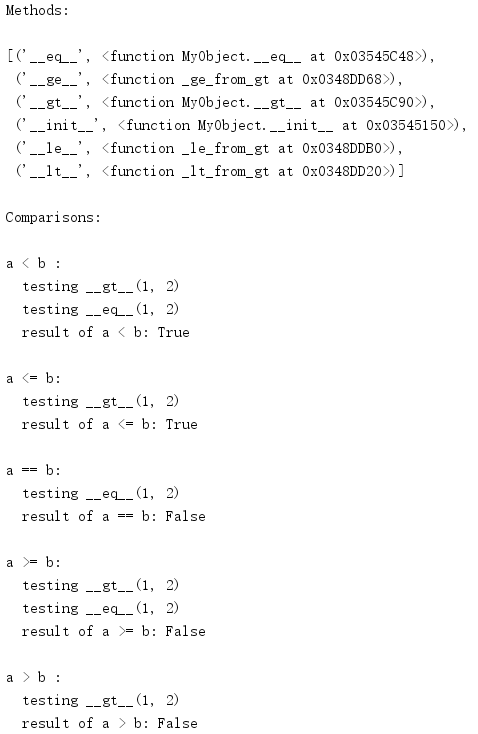
import functools import inspect from pprint import pprint @functools.total_ordering class MyObject: def __init__(self, val): self.val = val def __eq__(self, other): print(' testing __eq__({}, {})'.format( self.val, other.val)) return self.val == other.val def __gt__(self, other): print(' testing __gt__({}, {})'.format( self.val, other.val)) return self.val > other.val print('Methods: ') pprint(inspect.getmembers(MyObject, inspect.isfunction)) a = MyObject(1) b = MyObject(2) print(' Comparisons:') for expr in ['a < b', 'a <= b', 'a == b', 'a >= b', 'a > b']: print(' {:<6}:'.format(expr)) result = eval(expr) print(' result of {}: {}'.format(expr, result))
这个类必须提供__eq__()和另外一个富比较方法的实现。这个修饰符会增加其余方法的实现,它们会使用所提供的比较。如果无法完成一个比较,这个方法应当返回NotImplemented,从而在另一个对象上使用逆比较操作符尝试比较,如果仍无法比较,便会完全失败。
1.2.2 比对序
由于Python 3废弃了老式的比较函数,sort()之类的函数中也不再支持cmp参数。对于使用了比较函数的较老的程序,可以用cmp_to_key()将比较函数转换为一个返回比较键(collation key)的函数,这个键用于确定元素在最终序列中的位置。
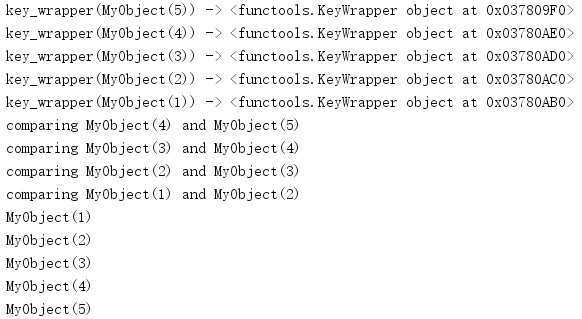
import functools class MyObject: def __init__(self, val): self.val = val def __str__(self): return 'MyObject({})'.format(self.val) def compare_obj(a, b): """Old-style comparison function. """ print('comparing {} and {}'.format(a, b)) if a.val < b.val: return -1 elif a.val > b.val: return 1 return 0 # Make a key function using cmp_to_key() get_key = functools.cmp_to_key(compare_obj) def get_key_wrapper(o): "Wrapper function for get_key to allow for print statements." new_key = get_key(o) print('key_wrapper({}) -> {!r}'.format(o, new_key)) return new_key objs = [MyObject(x) for x in range(5, 0, -1)] for o in sorted(objs, key=get_key_wrapper): print(o)
正常情况下,可以直接使用cmp_to_key(),不过这个例子中引入了一个额外的包装器函数,这样调用键函数时可以打印更多的信息。
如输出所示,sorted()首先对序列中的每一个元素调用get_key_wrapper()以生成一个键。cmp_to_key()返回的键是functools中定义的一个类的实例,这个类使用传入的老式比较函数实现富比较API。所有键都创建之后,通过比较这些键来对序列排序。
1.3 缓存
lru_cache()修饰符将一个函数包装在一个“最近最少使用的”缓存中。函数的参数用来建立一个散列键,然后映射到结果。后续的调用如果有相同的参数,就会从这个缓存获取值而不会再次调用函数。这个修饰符还会为函数增加方法来检查缓存的状态(cache_info())和清空缓存(cache_clear())。
import functools @functools.lru_cache() def expensive(a, b): print('expensive({}, {})'.format(a, b)) return a * b MAX = 2 print('First set of calls:') for i in range(MAX): for j in range(MAX): expensive(i, j) print(expensive.cache_info()) print(' Second set of calls:') for i in range(MAX + 1): for j in range(MAX + 1): expensive(i, j) print(expensive.cache_info()) print(' Clearing cache:') expensive.cache_clear() print(expensive.cache_info()) print(' Third set of calls:') for i in range(MAX): for j in range(MAX): expensive(i, j) print(expensive.cache_info())
这个例子在一组嵌套循环中执行了多个expensive()调用。第二次调用时有相同的参数值,结果在缓存中。清空缓存并再次运行循环时,这些值必须重新计算。

为了避免一个长时间运行的进程导致缓存无限制的扩张,要指定一个最大大小。默认为128个元素,不过对于每个缓存可以用maxsize参数改变这个大小。
import functools @functools.lru_cache(maxsize=2) def expensive(a, b): print('called expensive({}, {})'.format(a, b)) return a * b def make_call(a, b): print('({}, {})'.format(a, b), end=' ') pre_hits = expensive.cache_info().hits expensive(a, b) post_hits = expensive.cache_info().hits if post_hits > pre_hits: print('cache hit') print('Establish the cache') make_call(1, 2) make_call(2, 3) print(' Use cached items') make_call(1, 2) make_call(2, 3) print(' Compute a new value, triggering cache expiration') make_call(3, 4) print(' Cache still contains one old item') make_call(2, 3) print(' Oldest item needs to be recomputed') make_call(1, 2)
在这个例子中,缓存大小设置为2个元素。使用第3组不同的参数(3,4)时,缓存中最老的元素会被清除,代之以这个新结果。

lru_cache()管理的缓存中键必须是可散列的,所以对于用缓存查找包装的函数,它的所有参数都必须是可散列的。
import functools @functools.lru_cache(maxsize=2) def expensive(a, b): print('called expensive({}, {})'.format(a, b)) return a * b def make_call(a, b): print('({}, {})'.format(a, b), end=' ') pre_hits = expensive.cache_info().hits expensive(a, b) post_hits = expensive.cache_info().hits if post_hits > pre_hits: print('cache hit') make_call(1, 2) try: make_call([1], 2) except TypeError as err: print('ERROR: {}'.format(err)) try: make_call(1, {'2': 'two'}) except TypeError as err: print('ERROR: {}'.format(err))
如果将一个不能散列的对象传入这个函数,则会产生一个TypeError。

1.4 缩减数据集
reduce()函数取一个callable和一个数据序列作为输入。它会用这个序列中的值调用这个callable,并累加得到的输出来生成单个值作为输出。
import functools def do_reduce(a, b): print('do_reduce({}, {})'.format(a, b)) return a + b data = range(1, 5) print(data) result = functools.reduce(do_reduce, data) print('result: {}'.format(result))
这个例子会累加序列中的数。

可选的initializer参数放在序列最前面,像其他元素一样处理。可以利用这个参数以新输入更新前面计算的值。
import functools def do_reduce(a, b): print('do_reduce({}, {})'.format(a, b)) return a + b data = range(1, 5) print(data) result = functools.reduce(do_reduce, data, 99) print('result: {}'.format(result))
在这个例子中,使用前面的总和99来初始化reduce()计算的值。

如果没有initializer参数,那么只有一个元素的序列会自动缩减为这个值。空列表会生成一个错误,除非提供一个initializer参数。
import functools def do_reduce(a, b): print('do_reduce({}, {})'.format(a, b)) return a + b print('Single item in sequence:', functools.reduce(do_reduce, [1])) print('Single item in sequence with initializer:', functools.reduce(do_reduce, [1], 99)) print('Empty sequence with initializer:', functools.reduce(do_reduce, [], 99)) try: print('Empty sequence:', functools.reduce(do_reduce, [])) except TypeError as err: print('ERROR: {}'.format(err))
由于initializer参数相当于一个默认值,但也要与新值结合(如果输入序列不为空),所以必须仔细考虑这个参数的使用是否适当,这很重要。如果默认值与新值结合没有意义,那么最好是捕获TypeError而不是传入一个initializer参数。

1.5 泛型函数
在类似Python的动态类型语言中,通常需要基于参数的类型完成稍有不同的操作,特别是在处理元素列表与单个元素的差别时。直接检查参数的类型固然很简单,但是有些情况下,行为差异可能被隔离到单个的函数中,对于这些情况,functools提供了singledispatch()修饰符来注册一组泛型函数(generic function),可以根据函数第一个参数类型自动切换。
import functools @functools.singledispatch def myfunc(arg): print('default myfunc({!r})'.format(arg)) @myfunc.register(int) def myfunc_int(arg): print('myfunc_int({})'.format(arg)) @myfunc.register(list) def myfunc_list(arg): print('myfunc_list()') for item in arg: print(' {}'.format(item)) myfunc('string argument') myfunc(1) myfunc(2.3) myfunc(['a', 'b', 'c'])
新函数的register()属性相当于另一个修饰符,用于注册替代实现。用singledispatch()包装的第一个函数是默认实现,在未指定其他类型特定函数时就使用这个默认实现,在这个例子中特定类型就是float。

没有找到这个类型的完全匹配时,会计算继承顺序,并使用最接近的匹配类型。
import functools class A: pass class B(A): pass class C(A): pass class D(B): pass class E(C, D): pass @functools.singledispatch def myfunc(arg): print('default myfunc({})'.format(arg.__class__.__name__)) @myfunc.register(A) def myfunc_A(arg): print('myfunc_A({})'.format(arg.__class__.__name__)) @myfunc.register(B) def myfunc_B(arg): print('myfunc_B({})'.format(arg.__class__.__name__)) @myfunc.register(C) def myfunc_C(arg): print('myfunc_C({})'.format(arg.__class__.__name__)) myfunc(A()) myfunc(B()) myfunc(C()) myfunc(D()) myfunc(E())
在这个例子中,类D和E与已注册的任何泛型函数都不完全匹配,所选择的函数取决于类层次结构。
