[ 概要 ]
经常写sql的同学可能会用到union和union all这两个关键词, 可能你知道使用它们可以将两个查询的结果集进行合并,
那么二者有什么区别呢? 下面我们就简单的分析下.
[ 比较 ]
union: 对两个结果集进行并集操作, 不包括重复行,相当于distinct, 同时进行默认规则的排序;
union all: 对两个结果集进行并集操作, 包括重复行, 即所有的结果全部显示, 不管是不是重复;
下面我们举一个简单的例子来证明上面的结论:
1. 准备数据:
- drop table student;
- create table student
- (
- id int primary key,
- name nvarchar2(50) not null,
- score number not null
- );
- insert into student values(1,'Aaron',78);
- insert into student values(2,'Bill',76);
- insert into student values(3,'Cindy',89);
- insert into student values(4,'Damon',90);
- insert into student values(5,'Ella',73);
- insert into student values(6,'Frado',61);
- insert into student values(7,'Gill',99);
- insert into student values(8,'Hellen',56);
- insert into student values(9,'Ivan',93);
- insert into student values(10,'Jay',90);
- commit;
2. 比较不同点
查询比较①
- -- union all
- select * from student where id < 4
- union all
- select * from student where id > 2 and id < 6
- -- union
- select * from student where id < 4
- union
- select * from student where id > 2 and id < 6
union all 查询结果:
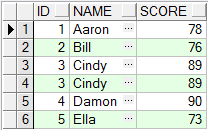
union 查询结果:
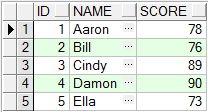
通过比较不难看出, union all不会去掉重复记录, 而union去掉了重复的记录.
查询比较②
- -- union all
- select * from student where id > 2 and id < 6
- union all
- select * from student where id < 4
- -- union
- select * from student where id > 2 and id < 6
- union
- select * from student where id < 4
union all 查询结果:
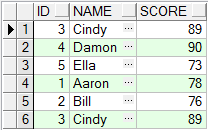
union 查询结果:
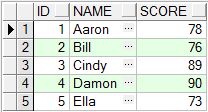
通过比较不难看出, union all会按照关联的次序组织数据, 而union会依据一定的规则进行排序.
那么这个规则是什么呢? 我们通过下面的查询得出规律:
- -- union
- select score,id,name from student where id > 2 and id < 6
- union
- select score,id,name from student where id < 4
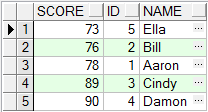
结论: 按照字段出现的顺序进行排序, 之前的查询相当于order by id, name, score, 刚刚的查询相当于order by score, id, name.
[ 总结 ]
1. 因为union all仅仅是简单的合并查询结果, 并不会做去重操作, 也不会排序, 所以union all效率要比union高.
所以在能够确定没有重复记录的情况下, 尽量使用union all.
2. 通常如果表有多个索引列时, 用union替换where子句中的or会起到较好的效果, 索引列使用or会造成全表扫描.
注意: 以上规则只针对多个索引列有效, 假如有column没有被索引, 那还是用or吧.
例如: 还是使用上面的例子, 假定name和score上建有索引.
1 -- 高效 2 select id, name, score from student where name like '%y%' 3 union 4 select id, name, score from student where score between 80 and 90 5 6 -- 低效 7 select id, name, score from student where name like '%y%' or score between 80 and 90