1.我们安装Hive的时候的版本为1.2.2,我们要下载1.2.2版本的web端的配置包apache-hive-1.2.2-src.tar.gz,下载地址:http://mirrors.shu.edu.cn/apache/hive/hive-1.2.2/
wget http://mirrors.shu.edu.cn/apache/hive/hive-1.2.2/apache-hive-1.2.2-src.tar.gz
2.解压,打包
tar -zxvf apache-hive-1.2.2-src.tar.gz cd apache-hive-1.2.2-src/hwi jar cvfM hive-hwi-1.2.2.war -C web .
3.把war包放到lib目录下
mv hive-hwi-1.2.2.war /usr/local/src/apache-hive-1.2.2-bin/lib
4.在hive-site.xml中添加hwi配置
<property> <name>hive.hwi.war.file</name> <value>lib/hive-hwi-1.2.2.war</value> <description>This is the WAR file with the jsp content for Hive Web Interface</description> </property>
hive官方的介绍:
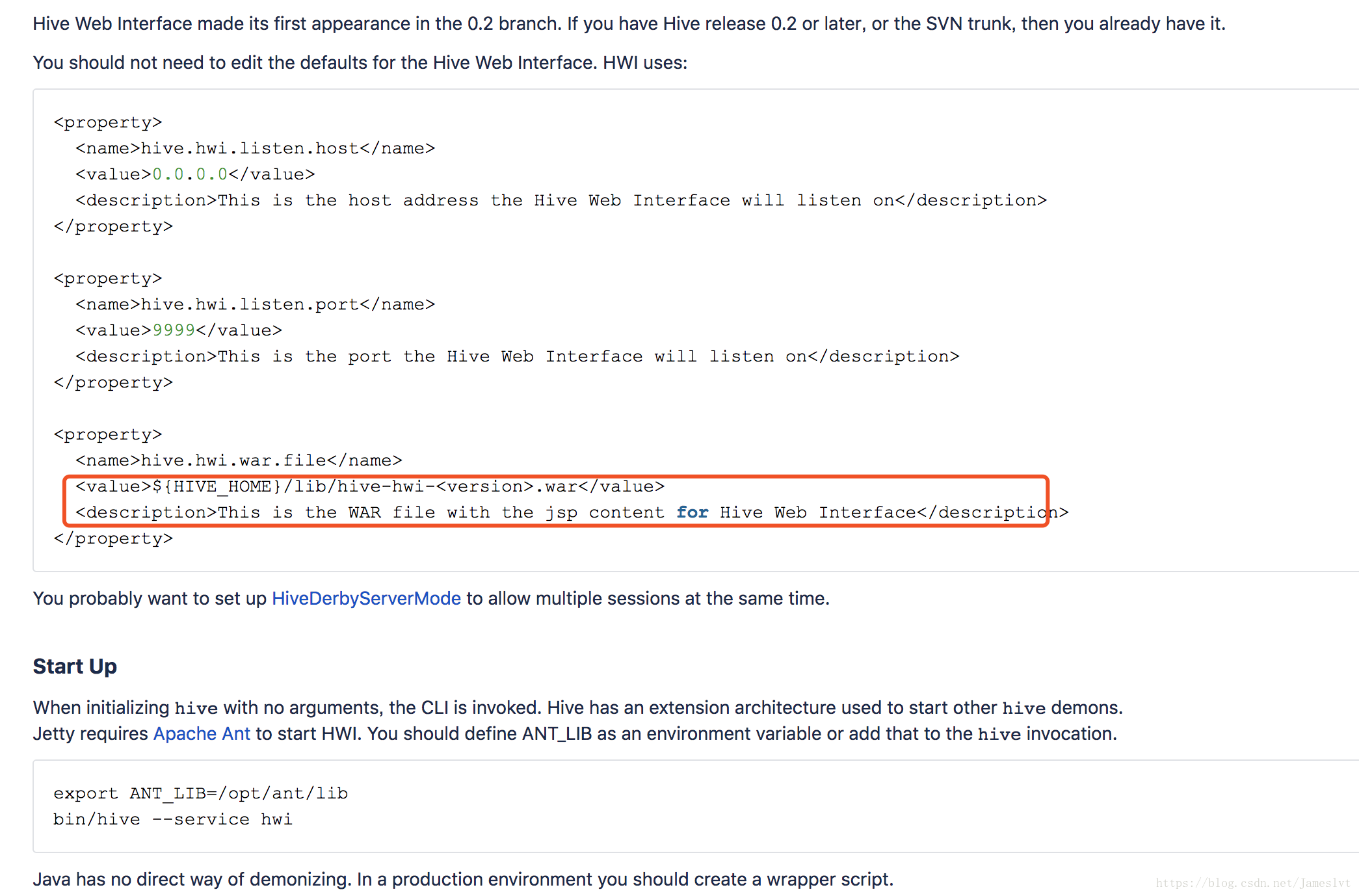
5.把JDK的lib目录下的tools.jar复制一份到Hive的lib目录下
cp $JAVA_HOME/lib/tools.jar $HIVE_HOME/lib
6.启动hwi
hive --service hwi 1>/dev/null >&1 &
可以通过nohup把hive控制台日志信息抛出,nohup hive --service hwi 1>/dev/null >&1 &
7.hwi使用
访问:http://master:9999/hwi/
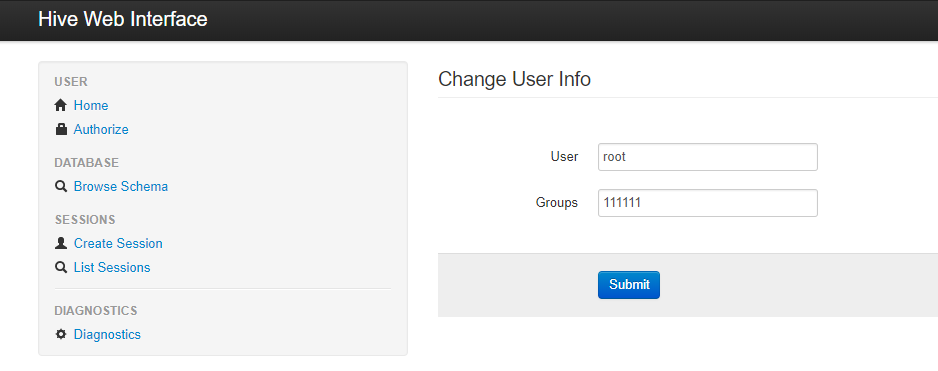
创建Session
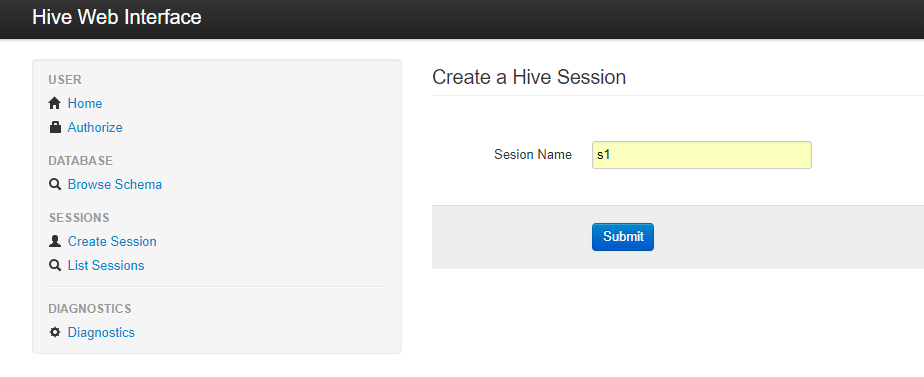
通过hive求得当前时间,select from_unixtime(unix_timestamp(),'yyyy-MM-dd HH:mm:ss')
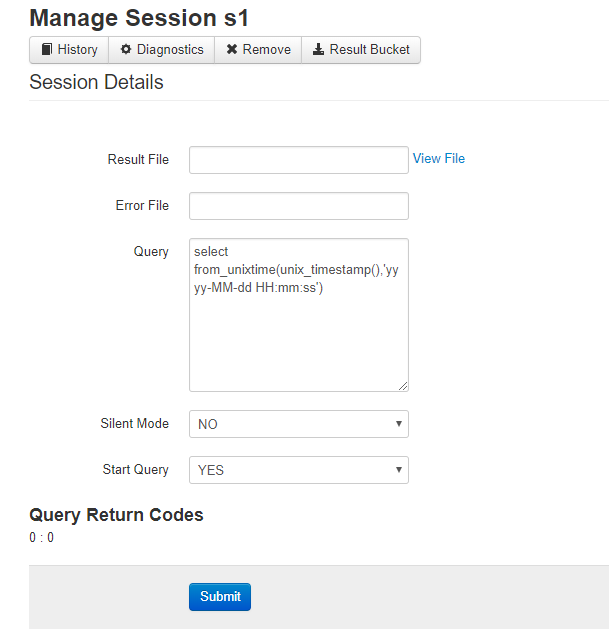
点击Result Bucket查看结果
