上一篇pandas DataFrame apply()函数(1)说了如何通过apply函数对DataFrame进行转换,得到一个新的DataFrame.
这篇介绍DataFrame apply()函数的另一个用法,得到一个新的pandas Series:
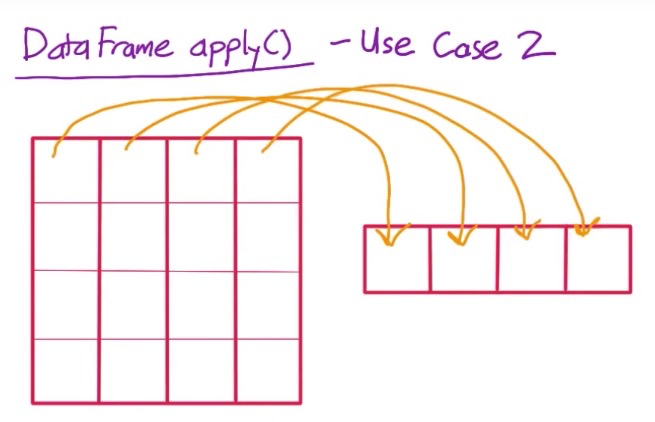
apply()中的函数接收的参数为一行(列),把一行(列)通过计算,返回一个值,最后返回一个Series:
下图展示了把DataFrame的各列转换成一个数,最后返回成一个Series:
举个栗子:
import numpy as np import pandas as pd df = pd.DataFrame({ 'a': [4, 5, 3, 1, 2], 'b': [20, 10, 40, 50, 30], 'c': [25, 20, 5, 15, 10] })
# 对整个DataFrame应用np.mean()函数,取各列的平均值,返回一个包含了各列平均值的Series print df.apply(np.mean) # 结果: a 3.0 b 30.0 c 15.0 dtype: float64
# 对整个DataFrame应用np.max()函数,取各列的最大值,返回一个包含了各列最大值的Series
print df.apply(np.max)
# 结果: a 5 b 50 c 25 dtype: int64
如果想要返回各列中第二大的数字组成的Series:
def get_second_largest(se): sorted_se = se.sort_values(ascending=False) return sorted_se.iloc[1] def second_largest(df): return df.apply(get_second_largest) print(second_largest(df))
a 4 b 40 c 20 dtype: int64