开发需求分析
经过初步讨论,我们决定了需要增加的功能以及开发策略。
功能
◇增加以人分类的功能,增加关注功能,使用户可以关注自己喜欢的行业大牛或者与自己同专业的人
◇把Tags划分的内容进行进一步分级处理,分为“初级”、“中级”、“高级”,例如“安装教程”属于“初级”,“node.js开发”属于“高级”
◇增加界面的中英文切换功能
◇在用户的个人页面里增加上传文件的功能
◇上传头像,设置更多的个人资料等小功能
◇对接后端数据库,使XuebaOnline可以显示内容
开发策略
往届学长的代码写的比较优秀,同时也比较复杂,我们不打算大幅度的更改他们的代码。所以接下来所要采取的主要开发策略是在原来的基础上继续迭代升级。
本次项目的最主要任务就是与数据处理团队的后端数据库进行对接,这需要做到与他们商定好使用何种数据格式,以及各种API的定义。这些都是需要在开发的初期就定下来的。
同时,我们需要把学长们使用的开源框架进行掌握,更改前端代码,使XuebaOnline网站更加人性化。
框架

基本架构

我们希望保持原有的概念架构,在保持大框架不变的基础上进行增量升级。
◇前端界面直接与用户进行交互。
◇后端系统负责处理用户的请求,并且衔接搜索系统,为用户提供想要的数据。
◇搜索系统负责搜集、整合数据,并响应网站后端的搜索请求,提供搜索结果。
前端架构设计
前端原有基本功能

前端计划新增功能

前端新增功能原型设计图
(仅为了展示功能效果,最终效果可能与原型图不同)
◇以人分类
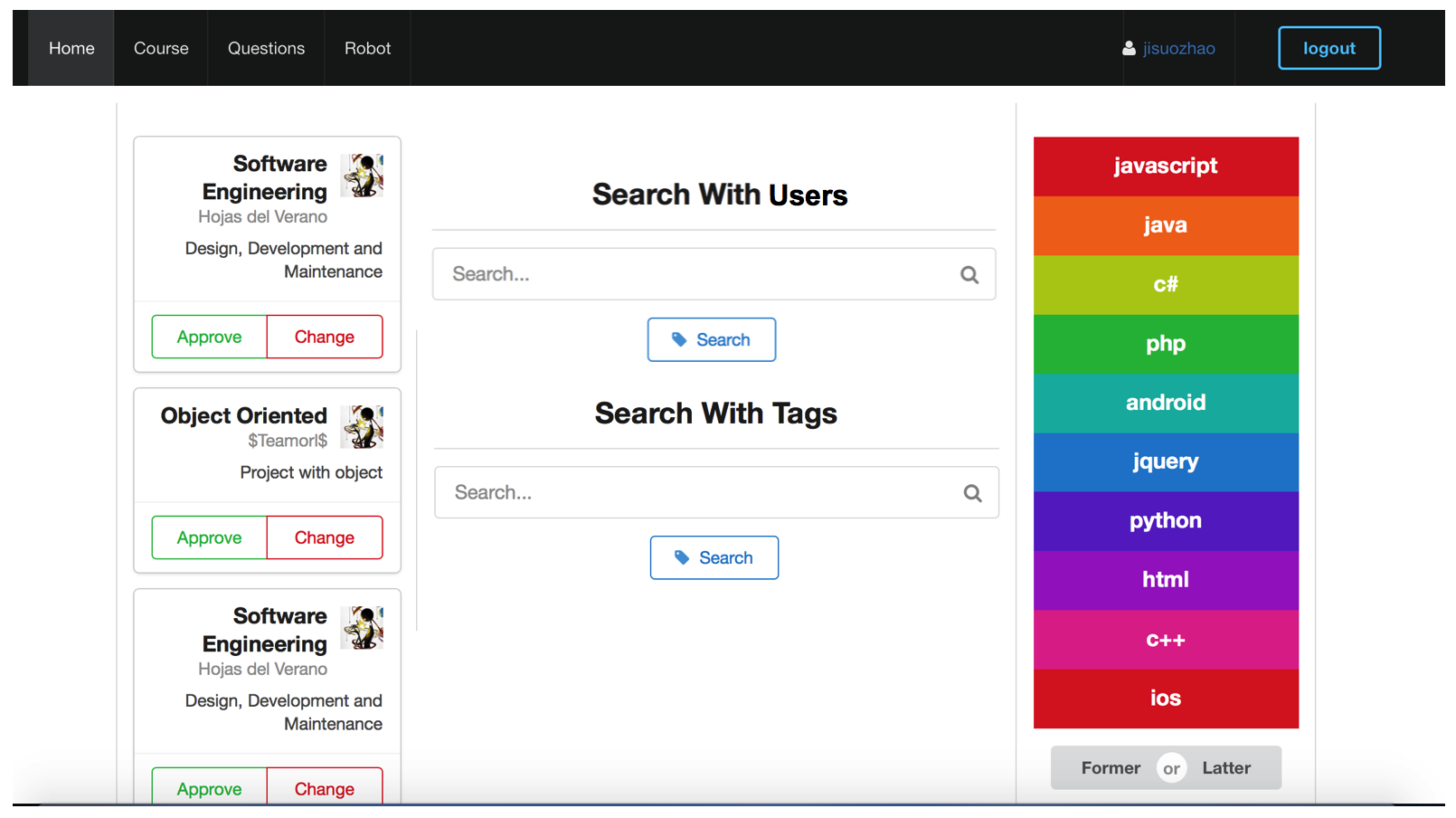
◇Tags分级

(以上并不代表真实的分级,只是为了展示各种标签的形式)
◇中英文切换
◇上传文件

◇更改头像

后端架构设计
后端基本模块

后端系统设计
◇继续使用Python语言和Django框架,在后端和前端的对接工作时需要保证原有的模块和功能不受影响。
◇搜索系统继续使用Solr+Nutch的配置,Solr负责搜索工作,Nutch负责内容抓取工作。
◇与数据处理团队商定好数据的格式,制定好API规范,同时与前端对接,使用户可以看到网站上的知识内容。
◇对后端API建立文档,方便开发时查阅。
◇使用Apache HTTP Server作为Web服务器,在开发的同时,需要保证原有的XuebaOnline网站的访问在全天大部分时间内的访问不受影响。
整理:姬索肇