HDFS作为Hadoop的核心技术之一,HDFS(Hadoop Distributed File System, Hadoop分布式文件系统)是分布式计算中数据存储管理的基础。具有高容错高可靠性、高可扩展性、高可获得性、高吞吐率等特性。为超大数据集的应用提供了便利。
一、设计的前提和目的
HDFS是Google的GFS(Google File System)的开源实现。具有以下五个基本目标:
- 硬件错误是常态而不是错误。HDFS一般运行在普通的硬件上,所以硬件错误是一种很正常的情况。所以在HDFS中,错误的检测并快速自动恢复是HDFS的最核心的设计目标。
- 流式数据访问。运行在HDFS上的应用主要是以批量处理为主,而不是用户交互式事务,以流式数据读取为多。
- 大规模数据集。HDFS中典型的文件大小要达到GB或者是TB级。
- 简单一致性原则。HDFS的应用程序一般对文件的操作时一次写入、多次读出的模式。文件一经创建、写入、关闭后,一般文件内容再发生改变。这种简单的一致性原则,使高吞吐量的数据访问成为可能。
- 数据就近原则。HDFS提供接口,以便应用程序将自身的执行代码移动到数据节点上来执行。采用这种方式的原因主要是:移动计算比移动数据更加划算。相比与HDFS中的大数据/大文件,移动计算的代码相比与移动数据更加划算,采用这种方式可以提供宽带的利用率,增加系统吞吐量,减少网络的堵塞程度。
二、HDFS体系结构
HDFS是一个主从结构(master/slave)。如图所示:
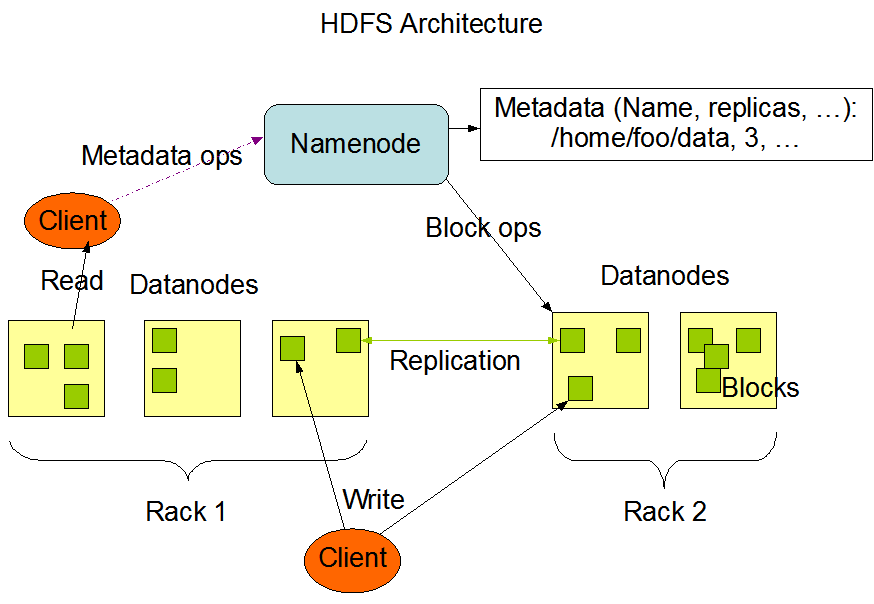
从这个图,我们可以看到HDFS中,主要由两类节点组成,一种是NameNode(NN),一种是DataNode(DN)。
NameNode是主控制服务器,负责管理HDFS文件系统的命名空间,记录文件数据库在每个DataNode节点上的位置和副本信息,协调客户端(Client)对文件的访问/操作,以及记录命名空间内的改动或命名空间本身属性的改变。
DataNode是数据存储节点,负责自身所在物理节点上的存储管理。HDFS中文件存储是按块(Block)存储的,默认大小是64MB。
客户端操作数据,只通过NameNode获取DataNode节点的物理位置,对于写/读数据的具体操作,NameNode是不会参与的,全部由DataNode负责。
由于HDFS中只有一个NameNode节点,所有存在单点问题,即如果改NameNode节点宕机,那么HDFS就会出现问题,数据可能丢失。解决办法是启动一个SecondaryNameNode或者将NameNode数据写出到其它远程文件系统中。
三、HDFS可靠性保障措施
HDFS的主要设计目标之一是在故障情况下,要保障数据存储的可靠性。HDFS具备了完善的冗余备份和故障恢复机制。一般通过dfs.replication设置备份份数,默认3。
- 冗余备份。将数据写入到多个DataNode节点上,当其中某些节点宕机后,还可以从其他节点获取数据并复制到其他节点,使备份数达到设置值。dfs.replication设置备份数。
- 副本存放。HDFS采用机架感知(Rack-aware)的策略来改进数据的可靠性、可用性和网络宽带的利用率。当复制因子为3时,HDFS的副本存放策略是:第一个副本放到同一机架的另一个节点(执行在集群中)/随机一个节点(执行在集群外)。第二个副本放到本地机架的其他任意节点。第三个副本放在其他机架的任意节点。这种策略可以防止整个机架失效时的数据丢失,也可以充分利用到机架内的高宽带特效。
- 心跳检测。NameNode会周期性的从集群中的每一个DataNode上接收心跳包和块报告,NameNode根据这些报告验证映射和其他文件系统元数据。当NameNode没法接收到DataNode节点的心跳报告后,NameNode会将该DataNode标记为宕机,NameNode不会再给该DataNode节点发送任何IO操作。同时DataNode的宕机也可能导致数据的复制。一般引发重新复制副本有多重原因:DataNode不可用、数据副本损坏、DataNode上的磁盘错误或者复制因子增大。
- 安全模式。在HDFS系统的时候,会先经过一个完全模式,在这个模式中,是不允许数据块的写操作。NameNode会检测DataNode上的数据块副本数没有达到最小副本数,那么就会进入完全模式,并开始副本的复制,只有当副本数大于最小副本数的时候,那么会自动的离开安全模式。DataNode节点有效比例:dfs.safemode.threshold.pct(默认0.999f),所以说当DataNode节点丢失达到1-0.999f后,会进入安全模式。
- 数据完整性检测。HDFS实现了对HDFS文件内容的校验和检测(CRC循环校验码),在写入数据文件的时候,也会将数据块的校验和写入到一个隐藏文件中()。当客户端获取文件后,它会检查从DataNode节点获取的数据库对应的校验和是否和隐藏文件中的校验和一致,如果不一致,那么客户端就会认为该数据库有损坏,将从其他DataNode节点上获取数据块,并报告NameNode节点该DataNode节点的数据块信息。
- 回收站。HDFS中删除的文件先会保存到一个文件夹中(/trash),方便数据的恢复。当删除的时间超过设置的时间阀后(默认6小时),HDFS会将数据块彻底删除。
- 映像文件和事务日志。这两种数据是HDFS中的核心数据结构。
- 快照。不太清楚。。。呵呵
四、HDFS命令
- bin/hadoop dfs -ls:命令和linux中的ls命令差不多,都是列出文件。
- bin/hadoop dfs -put src dest:上传文件到HDFS中。
- bin/hadoop dfs -get src dest:复制HDFS文件到本地系统中。
- bin/hadoop dfs -rmr path:删除文件。
- bin/hadoop dfs -cat in/*:查看文件内容。
- bin/hadoop dfsadmin -report:查看HDFS的基本统计信息,和访问http://fs4:50070一样。
- bin/hadoop dfsadmin -safemode enter/leave/get/wait:操作安全模式。
- bin/start-dfs.sh:在新节点执行,可以添加hdfs新节点。
- bin/start-balancer.sh:负载均衡。