一,loc函数及iloc函数的使用及区别
Pandas中的loc和iloc两个函数的用法基本相同。iloc与之不同的是它读取数据使用行索引跟列索引来对数据进行定位选取。而loc函数可以通过行名跟列名来对数据进行选取。也就是字符串或者字母。另外对于索引方面,虽然loc方法中也支持对行,列使用Int类型做筛选跟切片。但是这个是与iloc有所不同的是在loc中的0:2是真的代表把索引为0:2的数据选取出来。而iloc中的0:2则选取的内容中不包括2.最多取到1。在这一点上一定要注意其中的区别。
二,loc函数于iloc函数使用对比
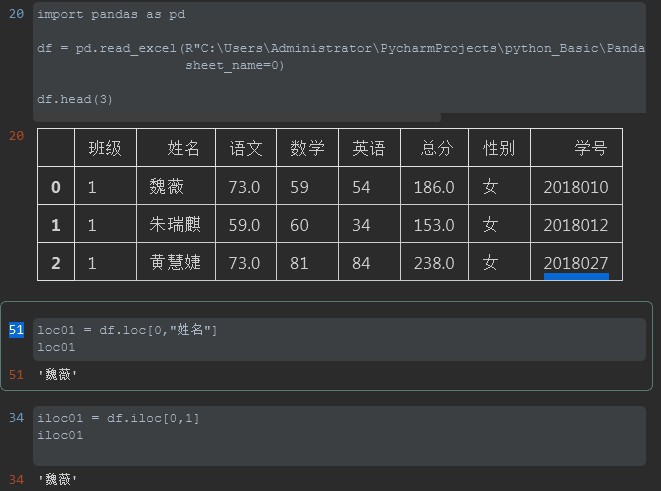
1. 对单元格进行取值
注释:loc在取值时0代表行号,因为在没有指定行号的情况下默认是数字0开始分配的。逗号之后代表列名
iloc在取值时逗号前的0跟loc相同也是行索引,而后面取值用的是列的索引值而不能是列名
1 #%% 2 3 import pandas as pd 4 5 df = pd.read_excel(R"C:UsersAdministratorPycharmProjectspython_BasicPandas_to_Excel20200727student_info.xlsx", 6 sheet_name=0) 7 8 df.head(3) 9 #%% 10 loc01 = df.loc[0,"姓名"] 11 loc01 12 #%% 13 iloc01 = df.iloc[0,1] 14 iloc01
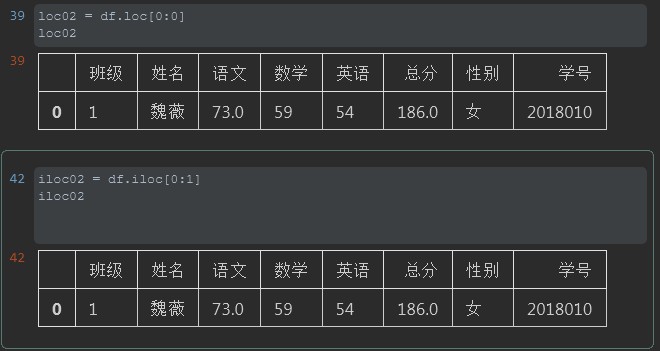
2. 读取行数据
注释:loc取值时候可以通过切片的方式取值0:0代表只去当前这第一列
iloc取值时对比loc唯一不同的是虽然也只是对行索引进行操作。但是切片后面的值位1而不是0因为如果是0的话,默认取值取到的是二维数组的表头也就是列名
#%% loc02 = df.loc[0:0] loc02 #%% iloc02 = df.iloc[0:1] iloc02
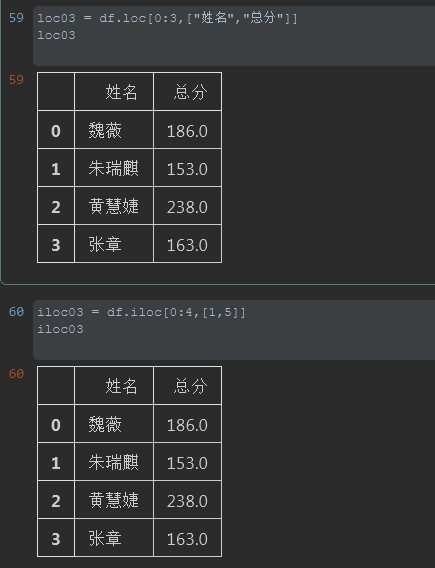
3. 读取所选指定范围的数据
需求:读取姓名和总分前4行的数据
注释:这里两者逗号前都是使用了切片的方式指定行数据,而逗号后面则是通过列表指定列名的方式来读取的。当然iloc是通过列索引来读取的。
#%% loc03 = df.loc[0:3,["姓名","总分"]] loc03 #%% iloc03 = df.iloc[0:4,[1,5]] iloc03
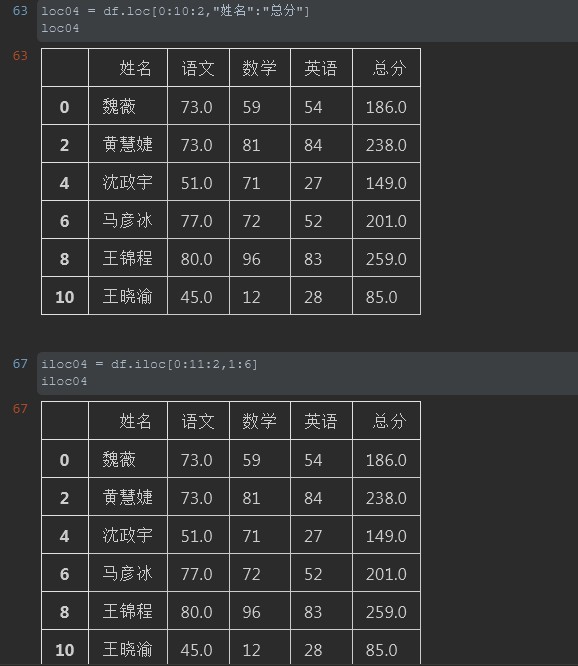
4. 通过切片来读取数据
注释:在前面的案例中其实已经使用了切片的方式,这里再来巩固一下。这里要注意的是,在逗号前的行索引切片中我使用了步长。也就是第二个分好的2,意思代表每隔1行进行读取。
对比iloc而言loc对于列的读取可以指定列名,这样在可读性方面大大优于Iloc。iloc1:6谁知道1:6是个什么鬼。还要一个个去数下标实在麻烦。所以不同场景不同使用看个人爱好。
iloc03 = df.iloc[0:4,[1,5]] iloc03 #%% loc04 = df.loc[0:10:2,"姓名":"总分"] loc04 #%% iloc04 = df.iloc[0:11:2,1:6] iloc04
5. 通过mask掩码对数据进行选取
需求:选出语文成绩大于80分的所有成员信息
注释:对于mask掩码,返回的是以True,False为值的布尔类型。有多少数据就返回多少个值。这里要强调的是建议使用loc来操作mask掩码也是最方便的。而iloc因为在下面的案例中我个人没能很好的演示成功也觉得麻烦,所以不展示iloc的结果了。感兴趣的可以自己测试。测试过程中少些几个数据。。。
#%% loc05 = df.loc[df["语文"]>80] loc05 #%% df["语文"]>80

需求2:筛选出班级2中,数学,语文,英语都大于80分的女生。
注释:通过mask掩码的运用。我们可以直接给条件判断,条件成立则把数据筛选出来。这样做的好处在于不用再使用循环取值,可以大大节省IO的消耗。
df = pd.read_excel(R"C:UsersAdministratorPycharmProjectspython_BasicPandas_to_Excel20200727student_info.xlsx", sheet_name=1) df[(df["语文"]>80) & (df["数学"]>80) & (df["英语"]>80) & (df["性别"]=="女")]
三,综合案例演示
需求:student_info.xlsx这个表格中有5个班级的信息,分别通过5个sheet来保存的。当我们通过pandas来读取Excel的所有内容时必须指定sheet_name=None.但是如果设定为None,那么读取后的数据不在是一个DataFrame而是一个dict字典。那么如何把读取到的dict中的值,作为一个sheet重新保存到另外一个Excel中呢?这就是这个案例的价值。当然如果您的每个sheets中的内容过大,不建议合并成一个sheet。因为这样
在数据打开时直接导致内存消耗而打不开文件。另外转成一个sheet的好处就是当我们读取的时候不在是dict而是DataFrame格式,这样我们在筛选数据的时候可以直接调用DataFrame的方法而不是dict的方法。
#%% df = pd.read_excel(R"C:UsersAdministratorPycharmProjectspython_BasicPandas_to_Excel20200727student_info.xlsx", sheet_name=None) keys = list(df.keys()) #获取所有的sheet名的列表 #把所有sheet中的内容合并成一个sheet(数据量大的时候不推荐使用) data_concat = pd.DataFrame() for i in keys: item = df[i] data_concat = pd.concat([data_concat,item]) print(data_concat) data_concat.to_excel(R"C:UsersAdministratorPycharmProjectspython_BasicPandas_to_Excel20200727student_info_concat.xlsx", index=False) print("Done!")
#%% df = pd.read_excel(R"C:UsersAdministratorPycharmProjectspython_BasicPandas_to_Excel20200727student_info_concat.xlsx") loc06=df.loc[(df["班级"]==1) | (df["班级"]==2) & (df["语文"]>60) & (df["数学"]>60) & (df["英语"]>60) ] loc06 #%%
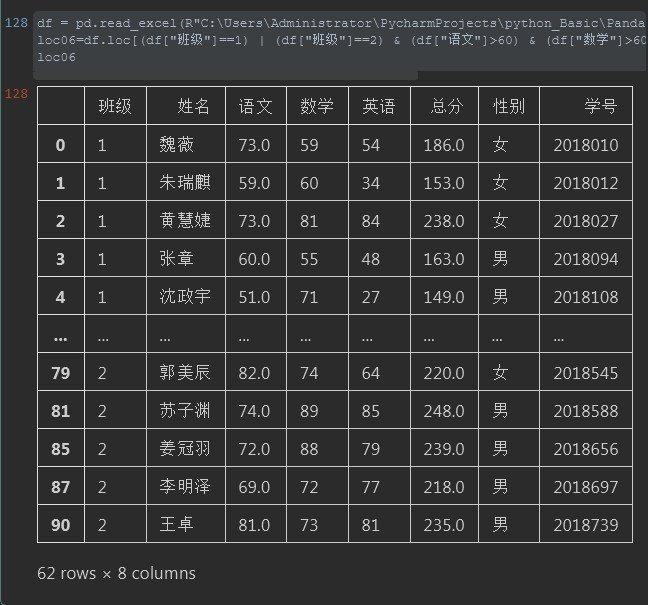
从演示效果来看是不是觉得作为DataFrame来读取表格数据比直接通过循环获取list,dict,set中的数据来的方便呀。所以应用好每个类,函数的技巧会给我们的日常工作带来更大的便利!