Hadoop核心组件
1、Hadoop生态系统

Hadoop具有以下特性:
方便:Hadoop运行在由一般商用机器构成的大型集群上,或者云计算服务上
健壮:Hadoop致力于在一般商用硬件上运行,其架构假设硬件会频繁失效,Hadoop可以从容地处理大多数此类故障。
可扩展:Hadoop通过增加集群节点,可以线性地扩展以处理更大的数据集。
目前应用Hadoop最多的领域有:
1) 搜索引擎,Doug Cutting设计Hadoop的初衷,就是为了针对大规模的网页快速建立索引。
2) 大数据存储,利用Hadoop的分布式存储能力,例如数据备份、数据仓库等。
3) 大数据处理,利用Hadoop的分布式处理能力,例如数据挖掘、数据分析等
2、Hadoop主要的三大组件(HDFS,MapReduce,YARN)
Hadoop的三大框架也被誉为三驾马车。源头主要是来源于Goole公司的的三篇论文中的GFS、MapReduce和BigTable,而这三个组件是用C来编写的。而Hadoop中的HDFS,MapReduce,Yarn是用Java来编写的。
1. HDFS分布式文件存储
用途:存储海量数据(分布式)
是Hadoop体系中数据存储管理的基础。它是一个高度容错的系统,能检测和应对硬件故障,用于在低成本的通用硬件上运行。HDFS简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。

Client:切分文件;访问HDFS分布式文件系统;与NameNode交互,获取文件位置信息;与DataNode交互,读取和写入数据。(与DataNode交互时采用就近原则)
NameNode:Master主节点,主要用途是管理HDFS的名称空间和数据块映射信息,配置副本策略,处理客户端请求。(存的是整个系统的元数据如:文件名,文件目录结构,文件属性<生成时间,副本数(默认为3),文件权限>以及每个文件的块列表和块所在的DataNode等) ## NameNode把数据分2部分进行存储。1.存放在内存中。2. NameNode服务重启后会在本地生成fsimage和fsedits文件,当内存中的数据丢失时就会自动到这2个文件中读取数据。
DataNode:Slave从节点,存储实际的数据,汇报存储信息给NameNode。(在本地文件系统存储文件数据块及块数据的校验和)
Secondary NameNode:辅助NameNode,分担其工作量,每隔一段时间获取HDFS元数据快照;定期合并fsimage和fsedits文件,推送给NameNode;紧急情况下,可辅助恢复NameNode。但Secondary NameNode并非NameNode的热备。
2. MapReduce编程模型
用途:处理海量数据 TB级别(主要用于对数据进行分布式计算)
(1)Map () : 把大的数据集拆分成若干个小的数据集。并对于每个数据集来进行逻辑业务处理。
(2)Reduce () :把每个小数据集中的处理结果合并起来。(Reduce可以不只1个)
Mapreduce处理流程,以wordCount为例:
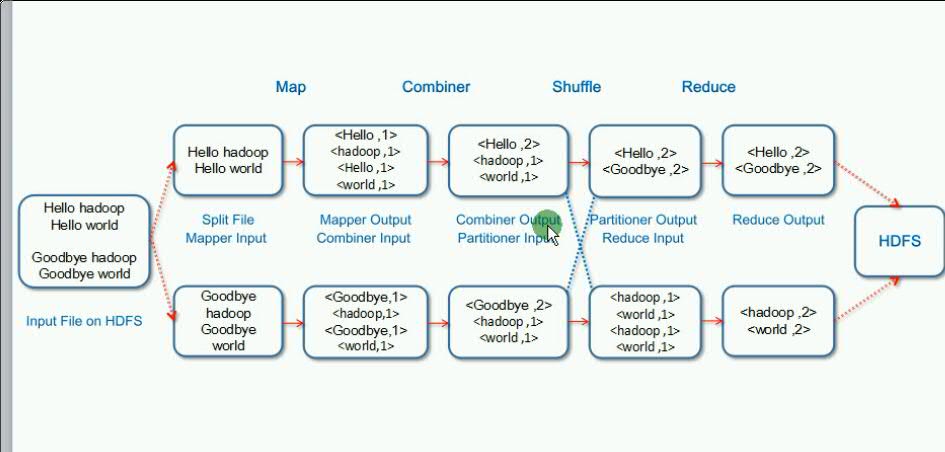
MapReduce也叫离线计算框架。流程可参考上图。下面是我个人理解的计算流程
input --> Map() --> shuffle -->Reduce () --> Output
(1) input阶段把数据进行拆分传给map任务,进行处理
(2) Map 接受数据并行处理数据
(3)Shuffle连接Map跟Reduce两个阶段
Maptask将数据写入磁盘
Reduce通过网络从每个map上读取一份数据
(4) Reduce最终对Map的处理结果作一个汇总
详细博客请参考:
http://www.cnblogs.com/hadoop-dev/p/5894911.html
3. YARN
用途:分布式资源管理框架
(1)管理整个集群中的资源
(2)分配调度集群中的资源
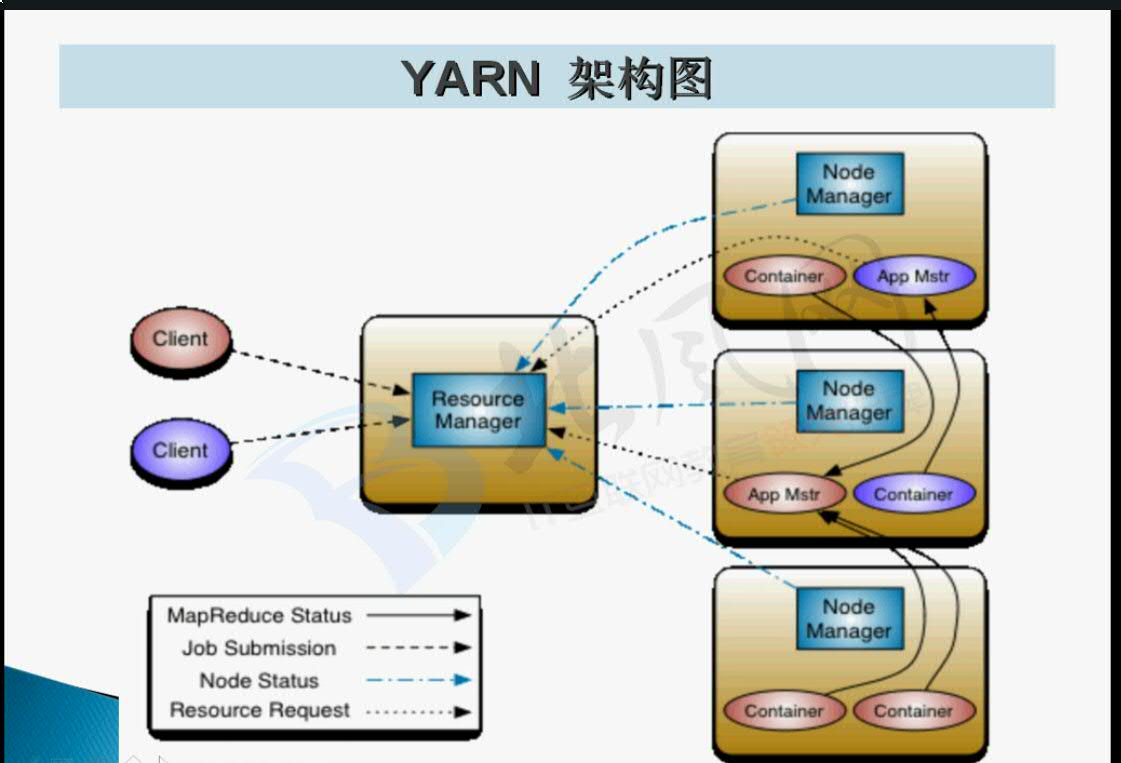
ResourceManager:整个集群中的资源管理及调度由ResourceManager来负责
NodeManager:每一台机器上资源的管理由NodeManager来负责
YARN的流程描述:
Client (提交任务)--》 ResourceManager (给每个任务分配一个应用管理者) --》 ApplicationMaster(分析每个Map任务分配需要的资源,划分任务并向ResourceManager进行申请) --》 ResourceManager (分配申请的资源后给每个节点的NodeManager,已容器的形式) --》NodeManager中的Container (每个Map,reduce任务都是在各个机器中的Container中运行的)--》汇总给ApplicationMaster --》最终汇报给ResourceManager
ApplicationMaster主要负责向ResourceManager上申请资源,分配资源(向Nodemanager),调度以及监控各个NodeManager上的Container处理Map,Reduce的状态及容错
Container主要是负责各自map,reduce的资源分配调度管理,并把结果汇报给applicationManager最终反馈给ResourceManager.
详细信息请参考下面博客:
http://blog.csdn.net/liuwenbo0920/article/details/43304243
3、Hadoop生态系统回顾

1. 元数据
数据库 --》通过Sqoop框架把数据存储到HDFS上
日志文件 --》通过Flume框架把数据存储到HDFS上
2. HDFS
YARN
MapReduce -->Hive :可以把数据跑在YARN上。但是因为MapReduce不是很好编写,因此通过基于SQL语句的Hive框架来对数据进行并行处理。Pig也是一种并行处理数据的框架。
Spark --》同样也是对map,reduce任务进行并行处理。因为Spark是把数据存放到内存中因此效率会更高。但是内存中的数据容易丢失同样风险性也高。
HBase (对上亿级别的数据查询,可以达到秒级别处理)
HBase是一个针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。和传统关系数据库不同,HBase采用了BigTable的数据模型:增强的稀疏排序映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。
HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。
数据模型:Schema-->Table-->Column Family-->Column-->RowKey-->TimeStamp-->Value
3. Oozie
Oozie是管理Hadoop作业的工作流调度系统。Oozie定义了控制流节点和动作节点。Oozie实现的功能:
(1)Workflow:顺序执行流程节点;
(2)Coordinator:定时触发workflow;
(3)Bundle Job:绑定多个Coordinator。
更加详细内容请参照:http://www.cnblogs.com/ilinuxer/p/6804339.html
4. ClouderManager
集群大了对数据可以很好的进行一个集中的部署,管理,分析,同步的作用。
5. zookeeper
对于分布式的组件,有些配置需要配。以及HA高可用性也需要部署,就通过Zookeeper框架来完成
6. Hue
对于以上的框架每个都由自己的管理页面。为了更方便我们的管理,可以通过Hue框架集中管理各个框架中的页面。