一、集合框架
集合,通常也叫容器,java中有多种方式保存对象,集合是java保存对象(对象的引用)的方式之一,之前学习的数组是保存对象的最有效的方式,但是数组却存在一个缺陷,数组的大小是固定的,但是往往我们在写程序的时候,并不知道需要保存多少个对象,或者是否需要用更复杂的方式来存储对象。而java提供集合类来解决这个问题。java中集合大家族的成员实在是太丰富了,有常用的ArrayList、HashMap、HashSet,也有不常用的Stack、Queue,有线程安全的Vector、HashTable,也有线程不安全的LinkedList、TreeMap等等!下图非常明了的展示了整个集合家族的关系。(图片来自网络)
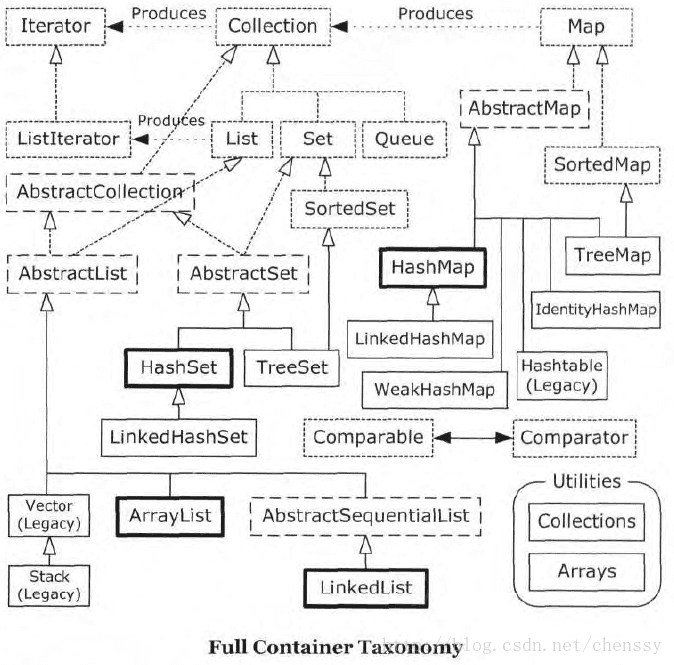
从上图中可以看出,集合类主要分为两大类:Collection和Map。
List接口通常表示一个列表(数组、队列、链表、栈等),其中的元素可以重复,常用实现类为ArrayList和LinkedList,另外还有不常用的Vector。另外,LinkedList还是实现了Queue接口,因此也可以作为队列使用。
Set接口通常表示一个集合,其中的元素不允许重复(通过hashcode和equals函数保证),常用实现类有HashSet和TreeSet,HashSet是通过Map中的HashMap实现的,而TreeSet是通过Map中的TreeMap实现的。另外,TreeSet还实现了SortedSet接口,因此是有序的集合(集合中的元素要实现Comparable接口,并覆写Compartor函数才行)。
Map是一个映射接口,其中的每个元素都是一个key-value键值对,同样抽象类AbstractMap通过适配器模式实现了Map接口中的大部分函数,TreeMap、HashMap、WeakHashMap等实现类都通过继承AbstractMap来实现,另外,不常用的HashTable直接实现了Map接口,它和Vector都是JDK1.0就引入的集合类。
Iterator是遍历集合的迭代器(不能遍历Map,只用来遍历Collection),Collection的实现类都实现了iterator()函数,它返回一个Iterator对象,用来遍历集合,ListIterator则专门用来遍历List。而Enumeration则是JDK1.0时引入的,作用与Iterator相同,但它的功能比Iterator要少,它只能再Hashtable、Vector和Stack中使用。
Arrays和Collections是用来操作数组、集合的两个工具类,例如在ArrayList和Vector中大量调用了Arrays.Copyof()方法,而Collections中有很多静态方法可以返回各集合类的synchronized版本,即线程安全的版本,当然了,如果要用线程安全的结合类,首选Concurrent并发包下的对应的集合类。
二、基本使用
1.List
List是一个有序,可以重复的集合,主要实现有下面三种:
①、List list1 = new ArrayList();
底层数据结构是数组,查询快,增删慢;线程不安全,效率高
②、List list2 = new Vector();
底层数据结构是数组,查询快,增删慢;线程安全,效率低,几乎已经淘汰了这个集合
③、List list3 = new LinkedList();
底层数据结构是链表,查询慢,增删快;线程不安全,效率高。
具体的使用如下:
1 public class ListDemo { 2 3 public static void main(String[] args) { 4 ArrayList<Integer> list = new ArrayList<Integer>(); 5 //1.添加元素 6 list.add(new Integer(10)); 7 list.add(1,20);//20自动转型为包装类 8 list.addAll(list); 9 System.out.println(list.toString());//通过迭代器遍历集合,拼接字符串打印 10 //2.相关属性 11 System.out.println("list大小:"+list.size()); 12 System.out.println("是否为空:"+list.isEmpty()); 13 //3.删除元素 14 list.remove(0);//通过索引删除元素 15 System.out.println(list); 16 //4.查找元素 17 System.out.println(list.get(0)); 18 //迭代集合 19 Iterator<Integer> iterator = list.iterator(); 20 while(iterator.hasNext()){ 21 System.out.print(iterator.next()+" "); 22 } 23 System.out.println(" ------------------------"); 24 LinkedList<String> list2 = new LinkedList<String>(); 25 list2.add("a"); 26 list2.add(1,"b"); 27 list2.addAll(list2); 28 System.out.println(list2); 29 System.out.println("list大小:"+list2.size()); 30 System.out.println("是否为空:"+list2.isEmpty()); 31 list2.remove("a"); 32 System.out.println(list2); 33 System.out.println("最后一个元素是:"+list2.getLast()); 34 Iterator<String> iterator2 = list2.iterator(); 35 while(iterator2.hasNext()){ 36 System.out.print(iterator2.next()+" "); 37 } 38 } 39 }
结果输出:
[10, 20, 10, 20] list大小:4 是否为空:false [20, 10, 20] 20 20 10 20 ------------------------ [a, b, a, b] list大小:4 是否为空:false [b, a, b] 最后一个元素是:b b a b
2.Set
set是一个无序,不可重复的集合。主要实现有三种:
①、Set set1 = new HashSet();
底层结构是通过HashMap实现,在jdk1.8后HashMap的底层实现主要是借助数组、链表以及红黑树。HashSet的特点是不保证元素的插入顺序,不可重复,非线程安全,允许集合元素为null.
②、Set set2 = new LinkedHashSet()
底层结构是通过LinkedHashMap实现,LinkedHashMap继承HashMap,本质上也是是借助,数组,链表以及红黑树实现。特点是底层采用链表和哈希表的算法。链表保证元素的添加顺序,哈希表保证元素的唯一性,非线程安全
③、Set set3 = new TreeSet()
底层结构是借助红黑树实现,特点是元素不可重复,不保证元素的添加顺序,对集合中元素进行排序,非线程安全。
具体的使用如下:
1 public class SetDemo { 2 3 public static void main(String[] args) { 4 //HashSet的使用 5 HashSet<String> set1 = new HashSet<String>(); 6 //1.添加元素 7 set1.add("1"); 8 set1.add("a"); 9 set1.add("c"); 10 set1.add("b"); 11 set1.addAll(set1); 12 System.out.println(set1);//通过遍历输出结合的元素,从结果可以看出,HashSet集合不允许元素重复,不保证插入的顺序 13 //2.相关属性或方法 14 System.out.println("是否包含c:"+set1.contains("c"));//是否包含某个元素 15 System.out.println("是否为空:"+set1.isEmpty());//是否为空 16 System.out.println("元素个数:"+set1.size()); 17 //3.删除某个元素 18 System.out.println(set1.remove("d"));//删除某个元素是否成功 19 20 //4.遍历集合 21 Iterator<String> iterator = set1.iterator(); 22 while(iterator.hasNext()){ 23 if(iterator.next().equals("a")){ 24 iterator.remove();//借助迭代器删除某个元素,推荐这种方法 25 } 26 } 27 System.out.println("删除元素a后的set集合的元素个数:"+set1.size()+" "+set1); 28 for (String str : set1) { //本质上是借助迭代器进行遍历 29 System.out.print(str+" "); 30 } 31 32 System.out.println(" ----------------------"); 33 //LinkedHashSet 34 LinkedHashSet<String> set2 = new LinkedHashSet<String>(); 35 //1.添加元素 36 set2.add("1"); 37 set2.add("a"); 38 set2.add("c"); 39 set2.add("b"); 40 set2.addAll(set2); 41 System.out.println(set2);//保证元素的插入顺序,不允许重复。 42 //其他的使用与HashSet类似,不过多重复 43 System.out.println(" ----------------------"); 44 // 45 TreeSet<Integer> set3 = new TreeSet<Integer>(new Comparator<Integer>() { 46 47 @Override 48 public int compare(Integer o1, Integer o2) { 49 if(o1<o2){ 50 return 1; 51 }else if(o1>o2){ 52 return -1; 53 }else { 54 return 0; 55 } 56 } 57 }); 58 set3.add(2); 59 set3.add(3); 60 set3.add(1); 61 System.out.println(set3);//集合中的元素默认按字典顺序升序排序,通过红黑树实现,显示的是[1,2,3],由于对比较方法进行重写,是其倒序排序 62 //其他使用类似HashSet 63 64 } 65 66 }
结果输出:
[1, a, b, c] 是否包含c:true 是否为空:false 元素个数:4 false 删除元素a后的set集合的元素个数:3 [1, b, c] 1 b c ---------------------- [1, a, c, b] ---------------------- [3, 2, 1]
3.Map
①、Map map = new HashMap();
底层结构是数组,哈希表以及红黑树,特点是不保证映射关系添加的先后顺序,key不允许重复,key判断重复的标准是:key1和key2的equal为true,以及hashcode相等。
②、Map map = new LinkedHashMap();
底层结构是链表、哈希表以及红黑树,特点是Map中的key保证添加的先后顺序,key不允许重复,key重复的判断标准和HashMap一致。
③、Map map = new TreeMap();
底层结构是红黑树。特点是Map中的key保证先后添加的顺序,不允许重复。key判断的key的compare的结果
具体使用如下:
1 public class MapDemo { 2 3 public static void main(String[] args) { 4 //HashMap 5 HashMap<String, Integer> map1 = new HashMap<String, Integer>(); 6 //1.添加键值对 7 map1.put("a", 1); 8 map1.put("f", 2); 9 map1.put("c", 3); 10 System.out.println(map1); 11 map1.put("a", 10); 12 System.out.println(map1);//key不允许重复,当重复的时候,后者覆盖前者的值 13 //2.相关属性和方法 14 System.out.println("键值对个数:"+map1.size()); 15 System.out.println(map1.isEmpty()); 16 System.out.println(map1.containsKey("g")); 17 System.out.println(map1.remove("a", 50));//删除指定键值对 18 //3.通过key查找值,获取key或value 19 System.out.println("f对应的值:"+map1.get("f")); 20 System.out.println(map1.keySet());//获取所有的key,并且返回一个key的Set集合 21 System.out.println(map1.values());//返回所有的value 22 //4.hashmap的遍历 23 //4.1二次取值遍历 24 for(String key:map1.keySet()){ 25 System.out.print(key+"="+map1.get(key)+" "); 26 } 27 System.out.println(); 28 //4.2通过迭代器 29 Iterator<Entry<String, Integer>> iterator= map1.entrySet().iterator(); 30 while(iterator.hasNext()){ 31 Entry<String, Integer> entry= iterator.next(); 32 System.out.print(entry.getKey()+"="+entry.getValue()+" "); 33 } 34 System.out.println(); 35 //4.3推荐,尤其是容量大时 通过Map.entrySet遍历key和value,与4.2本质上一样 36 for(Entry<String, Integer> entry: map1.entrySet()){ 37 System.out.print(entry.getKey()+"="+entry.getValue()+" "); 38 } 39 System.out.println(" ---------------------"); 40 41 42 LinkedHashMap<String, Integer> map2 = new LinkedHashMap<String, Integer>(); 43 map2.put("a", 1); 44 map2.put("f", 2); 45 map2.put("c", 3); 46 System.out.println(map2);//保证键值对的插入顺序 47 //LinkedHashMap继承HashMap其他使用类似HashMap 48 System.out.println(" ---------------------"); 49 TreeMap<String, Integer> map3 = new TreeMap<String, Integer>(); 50 map3.put("a", 1); 51 map3.put("f", 2); 52 map3.put("c", 3); 53 System.out.println(map3);//保证键值对的插入顺序,key进行字典顺序的升序排序 54 System.out.println(map3.firstKey()); 55 System.out.println(map3.lastKey());//获取最后一个key 56 //其他使用类似HashMap 57 58 59 } 60 61 }
结果输出:
{a=1, c=3, f=2}
{a=10, c=3, f=2}
键值对个数:3
false
false
false
f对应的值:2
[a, c, f]
[10, 3, 2]
a=10 c=3 f=2
a=10 c=3 f=2
a=10 c=3 f=2
---------------------
{a=1, f=2, c=3}
---------------------
{a=1, c=3, f=2}
a
f
4.Map和Set集合的关系总结
- HashSet借助HashMap实现,都采哈希表和红黑树算法; TreeSet借助TreeMap实现, 都采用 红黑树算法;LinkedHashMap 和 LinkedHashSet 都采用 哈希表算法和红-黑树算法。
- Set集合实际上是由Map集合的key组成。
- HashSet的性能基本上总是比TreeSet好,特别是在添加和查询元素的时候,TreeSet存在的唯一原因是它可以维持元素的排序状态。