前言
几个月之前,有同事找我要PHP CI框架写的OA系统。他跟我说,他需要学习PHP CI框架,我建议他学习大牛写的国产优秀框架QeePHP。
我上QeePHP官网,发现官方网站打不开了,GOOGLE了一番,发现QeePHP框架已经没人维护了。API文档资料都没有了,那可怎么办?
毕竟QeePHP学习成本挺高的。GOOGLE时,我发现已经有人把文档整理好,放在自己的个人网站上了。我在想:万一放文档的个人站点也挂了,
怎么办?还是保存到自己的电脑上比较保险。于是就想着用NodeJS写个爬虫抓取需要的文档到本地。后来抓取完成之后,干脆写了一个通用版本的,
可以抓取任意网站的内容。
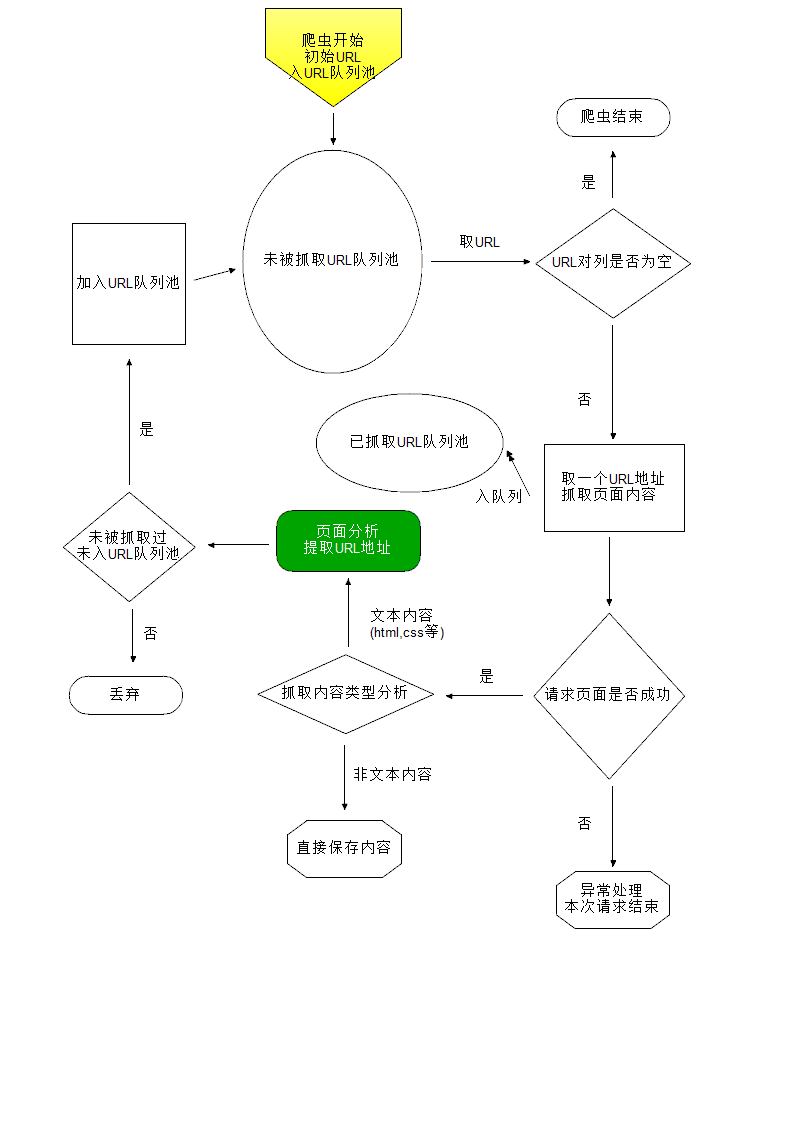
爬虫原理
抓取初始URL的页面内容,提取URL列表,放入URL队列中,
从URL队列中取一个URL地址,抓取这个URL地址的内容,提取URL列表,放入URL队列中
。。。。。。
。。。。。。
NodeJS实现源码
 View Code
View Code调用
|
1
2
3
4
5
6
7
8
9
|
var Robot = require("./robot.js");var oOptions = { domain:'baidu.com', //抓取网站的域名 saveDir:"E:\wwwroot/baidu/", //抓取内容保存目录 debug:true, //是否开启调试模式};var o = new Robot(oOptions);o.crawl(); //开始抓取 |
后记
还有些地方需要完善
1.处理302跳转
2.处理COOKIE登陆
3.大文件偶尔会非正常退出
4.使用多进程
5.完善URL队列管理
6.异常退出之后处理
实现过程中碰到了一些问题,最后还是解决了,
爬虫原理很简单,只有真正实现过,才会对它更加理解,
原来实现不是那么简单,也是需要花时间的。
7.下载地址: https://codeload.github.com/wadeyu/nodejsrobot/zip/master
转自:http://www.cnblogs.com/wadeyu/archive/2015/07/10/4636170.html