一、将语料库转化为向量(gensim)
在对语料库进行基本的处理后(分词,去停用词),有时需要将它进行向量化,便于后续的工作。
from gensim import corpora,similarities,models import jieba #第一步:确定语料库的语料和要进行判断的句子: #wordlist作为语料库,语料库中有三句话,相当于三篇文章. wordlist=['我喜欢编程','我想变漂亮','今天吃午饭了吗'] sentenses='我喜欢什么' #第二步:使用语料库建立词典,也就是给预料库中的每个单词标上序号,类似:{'我':1,'喜欢':2,'编程':3,....}首先进行中文分词 text=[[word for word in jieba.cut(words) ]for words in wordlist] dictionary = corpora.Dictionary(text)#这一步给每个词赋予了编号 print(dictionary) #第三步,对语料中的每个词进行词频统计,doc2bow是对每一句话进行词频统计,传入的是一个list #corpus得到的是一个二维数组[[(0, 1), (1, 1), (2, 1)], [(3, 1), (4, 1)], [(5, 1), (6, 1), (7, 1), (8, 1), (9, 1)]],意思是编号为0的词出现的频率是1次,编号为2的词出现的频率是1次 corpus=[dictionary.doc2bow(word) for word in text]#这一步将用字符串表示的文档转换为用词id和词频来表示 print(corpus)#(词的ID号,词频)
代码结果为:
我们利用gensim.corpora.dictionary.Dictionary类为每个出现在语料库中的单词分配了一个独一无二的整数编号。doc2bow函数主要用于让编了号的语料库变为bow词袋模型,对每个不同单词的出现次数进行了计数,然后以稀疏向量的形式返回结果。上述代码的corpus就是语料库的词袋模型,其中,每一个子列表都表示一篇文章。
基于这个处理好了的含有三篇文章的训练文档,我们可以训练一个TFIDF模型,就是下面代码的第四步;
然后经过第五步,我们将上述用词频表示文档向量表示为一个用tf-idf值表示的文档向量
前面有说TFIDF可以用来做关键词提取,因为它认为tfidf值越大的词就越能够体现它对这篇文章的重要性。但TF-IDF也可用于查找相似文章、对文章进行摘要提取、特征选择(重要特征的提取)工作。如果说接下来是要对sentenses和语料库的三篇文章进行相似度比较的话,接下来的代码为:
#第四步:使用corpus训练tfidf模型 model=models.TfidfModel(corpus) #要是想要看tfidf的值的话可以: tfidf=model[corpus] ''' tfidf的结果是语料库中每个词的tfidf值 [(0, 0.5773502691896258), (1, 0.5773502691896258), (2, 0.5773502691896258)] [(3, 0.7071067811865475), (4, 0.7071067811865475)] [(5, 0.4472135954999579), (6, 0.4472135954999579), (7, 0.4472135954999579), (8, 0.4472135954999579), (9, 0.4472135954999579)] ''' #第五步:为tfidf模型中的每个句子建立索引,便于进行相似度查询,传入的时候语料库的tfidf值 similarity=similarities.MatrixSimilarity(tfidf) #第六步,处理要比较的句子,首先分词,其次获得词频,jieba只能传入字符串 sen=[word for word in jieba.cut(sentenses)] sen2=dictionary.doc2bow(sen) #然后计算它的tfidf值 sen_tfidf=model[sen2] #获得与所有句子的相似度,sim输出的是一个数组 sim=similarity[sen_tfidf]
https://blog.csdn.net/Lau_Sen/article/details/80436819
代码中的tfidf,和sen_tfidf结果分别是语料库和新句子的tfidf向量化表示。很多模型就是基于tf-idf来做的,比如lsi,lda等。现在每个句子就变成了[(词id号,idf值),(词id号,idf值)....]这样的稀疏表示形式。
然后,基于这个用tfidf值表示的向量,我们又可以训练一个lsi模型,有了这个lsi模型,我们就可以将文档映射到一个二维的topic空间中,代码如下:
from gensim import corpora,similarities,models import jieba documents = ["Shipment of gold damaged in a fire","Delivery of silver arrived in a silver truck","Shipment of gold arrived in a truck"] texts = [[word for word in document.lower().split()] for document in documents] #基于分词结果,给词编号,建词袋模型 dictionary = corpora.Dictionary(texts) corpus = [dictionary.doc2bow(text) for text in texts] #基于词id号和词频建tfidf向量 tfidf = models.TfidfModel(corpus) corpus_tfidf = tfidf[corpus] for doc in corpus_tfidf: print(doc) #基于tfidf向量建lsi模型 lsi = models.LsiModel(corpus_tfidf, id2word=dictionary, num_topics=2) corpus_lsi = lsi[corpus_tfidf] for doc in corpus_lsi: print(doc)
结果为: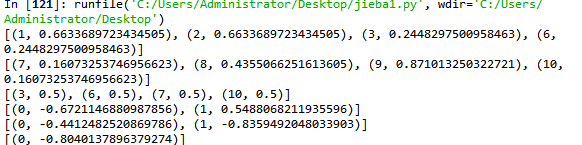
很奇怪,用英文的话可以显示出主题1,2的值,但是中文只显示一个,是因为lsi本身就不适用中文吗?