本文是对论文的解读和复现。
论文地址:https://arxiv.org/abs/1408.5882
一、论文
在预先训练的词向量上训练卷积神经网络(CNN)用于句子级分类任务的实验。证明了一个简单的CNN,它只需要很少的超参数调整和静态向量,就可以在多个基准上获得很好的结果。通过微调学习特定于任务的向量可以进一步提高性能。本文讨论的CNN模型改进了7项任务中的4项,包括情感分析和问题分类。
1.introduce
近年来,深度学习模型在计算机视觉(Krizhevsky et al.,2012)和语音识别(Graves et al.,2013)方面取得了显著的效果。在自然语言处理中,许多使用深度学习方法的工作涉及通过神经语言模型学习词向量表示(Bengio等人,2003;Yih等人,2011;Mikolov等人,2013)和对学习到的词向量进行构图以进行分类(Collobert等人,2011)。
词向量,就是将单词经由隐藏层,从稀疏编码(大小为V,V是词汇表长度)投影到低维向量空间。词向量本质上是对单词的语义特征进行维度编码的特征提取器。在这种稠密的表示中,语义相近的词在低维向量空间中的欧几里德距离或余弦距离上同样相近。
卷积神经网络(CNN)利用带卷积滤波器的层,作用于局部特征(LeCun等人,1998)。CNN模型最初是为计算机视觉而发明的,后来被证明对NLP有效,并在语义分析(Yih等人,2014)、搜索查询检索(Shen等人,2014)、句子建模(Kalchbrenner等人,2014)和其他传统NLP任务(Collobert等人,2011)方面取得了优异的结果。
在现有的工作中,我们在一个无监督的神经语言模型中得到的词向量上加入一层卷积。(2013)词向量来自于1000亿字的公开的谷歌新闻上。最初保持词向量不变,只学习模型的其他参数。尽管很少调整超参数,这个简单的模型在多个基准上取得了很好的结果,这表明预先训练的词向量是通用的特征提取器,可以用于各种分类任务。通过进一步的微调可以学习特定于任务的词向量。最后,我们描述了对体系结构的一个简单修改,允许通过多个通道使用预先训练的向量和任务特定的向量。
我们的工作表明,对于图像分类,从预训练的深度学习模型获得的特征提取器在各种任务上表现良好,包括与训练特征提取器的原始任务非常不同的任务。
2.模型
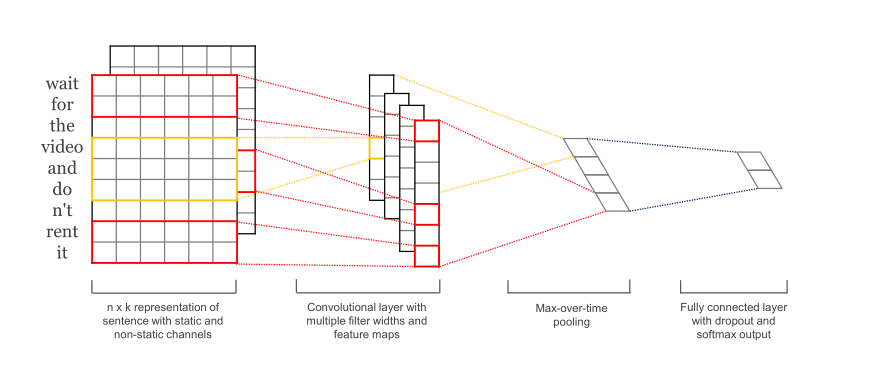
图上最左边这个n×k的矩阵格子,每一行表示的是一个k维的词,用xi来表示句子中第i个k维向量表示的词,上图就表示了一个长度为n的句子的卷积过程。
从左一到左二图表示着卷积运算,包含一个滤波器w∈Rhk,该滤波器作用在大小为h的窗口上以产生新的特征。
例如图上的红线部分,窗口大小为2,每次选择两个词进行特征提取;
黄线部分窗口大小为3,每次选择三个词进行特征提取,也就是说,“窗口”的含义是“每次作用几个单词”,反应在图上就是“滤波器一次性遍历几行”;
我们可以看见,对于左二图的离我们最近的这列格子,长得条状就叫做 channel吧,它的窗口为2,每作用两个单词都会得到一个格子,因为这句话有9个单词,从上往下滑动,就会得到7个格子;如果窗口为3,即离我们最远的这列黄格子,从上往下滑动,智能得到5个格子。

上式就是用一个窗口大小为h的滤波器,作用在$x_{i}$到$x_{i+h-1}$上,计算得到特征$c_{i}$的过程,b是个偏置常量,w是卷积层的矩阵。$f$是个非线性函数例如$tanh$。不同大小的滤波器各自在句子上上滑动,最后得到多个特征向量$c=left [ c_{1},c_{2},...,c_{n-h+1} ight ]$。
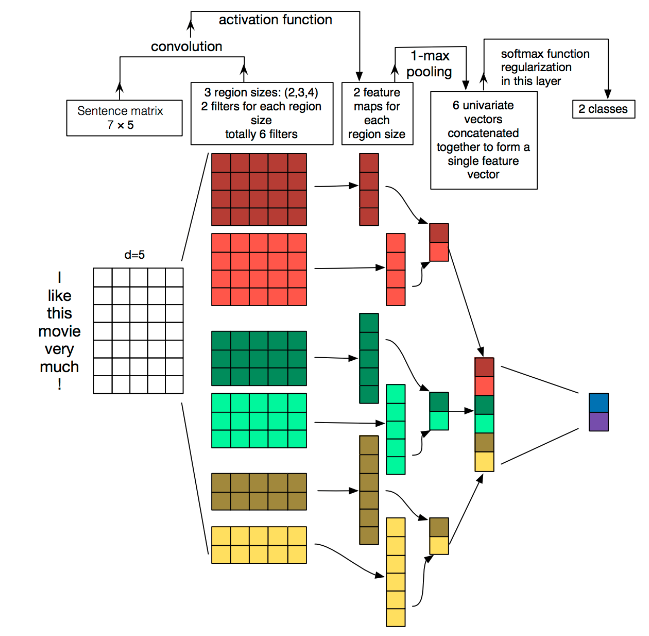
这个图更好的展示了过程,彩色矩阵部分是代表着卷积核,它们分次对句子进行计算,这里有2个窗口为2的卷积核(黄色系),2个窗口为3的卷积核(绿色系),2个窗口为4的卷积核(红色系),每个彩色矩阵输出了一个channel,也就是每个kernel_size 有两个输出 channel。然后进行池化,我们就可以得到6个能够很好的代表特征的格子,也就是数字。
之前一直很纠结的为什么论文它要选窗口为2,3,4的卷积核各两个来做,原来是因为:首先即便是大小一样的卷积核,它们所能检测到的特征也是不一样的,其次考虑到后边需要做池化,如果只有1个某窗口大小的卷积核的话,输出就只有1个格子了,会丢失很多信息;最后不同的卷积核的检测范围不一样,就像图片一样,小的卷积核发现了眼睛,大的卷积核一看原来是人脸。
然后,从左二到左三这个过程,对特征映射应用一个最大超时池操作(Collobert等人,2011),并将最大值$widehat{c}=maxleft { c ight }$作为该过滤器提取出来的特征。其思想是一个滤波器只要捕捉该句子最重要的特征就可以了。这种池机制自然处理可变的句子长度。
三、代码思路
反正先导库,tensorflow2以后导keras前都要加一个tensorflow.:
import logging %tensorflow_version 2.x import tensorflow as tf from tensorflow.keras.layers import Conv1D, MaxPool1D, Dense, Flatten, concatenate, Embedding,Input from tensorflow.keras.models import Model from tensorflow.keras.utils import plot_model
我们从tensorflow.keras.layers里导了Conv1D(用来卷积), MaxPool1D(用来池化), Dense(用来写输出层), Flatten(用来展平向量), concatenate(用来把池化结果拼接), Embedding(用来处理词嵌入),Input(用来构建输入层)
以及import了Model用来组合这些输入层嵌入层卷积层池化层输出层。还用plot_model来看网络结构。
1.构建输入,这里并不考虑一次性输入几个句子,就用None表示。
注意:输入只需要知道句子的长度就可以了,也就是一句话中的分词数量。当时我很迷惑,因为就算是onehot编码的词向量组成的句子,它也是一个矩阵形式呀,形式为(单词数量,词汇表长度),为什么词汇表的长度单独作为一个参数输入?
当我看见嵌入矩阵的时候更疯了,什么情况,嵌入矩阵依旧是(词汇表长度,词向量长度),这个跟我们定义的句子(句子长度,)这个矩阵,怎么乘?最后还得到了(句子长度,词向量长度)?还成功了?
原来我们具体输入的,不是通常意义上像onehot编码那样的东西,比如['i','love','you']这样的一个已经分好词的句子结果,然后我们基于语料库训练出来了一个字典D,于是乎我们输入这个框架的x_input就应该是这样的形式[4,5,6],4代表‘i’在字典里的位置,5代表‘love’在字典里的位置。现在就好理解多了,然后我们的嵌入矩阵,只要根据4,5,6,抽出第4行,第5行,第6行即可构成我们的目标词向量。这就是官方embedding文档中说的将正整数(索引值)转换为固定尺寸的稠密向量
#max_sequence_length:句子的长度 #max_token_num:词汇表的长度 #embedding_dim:嵌入矩阵的维度 #output_dim:嵌入矩阵处理后的词向量维度 #1.构建embedding层 x_input = Input(shape=(max_sequence_length,))#输入一个长度为max_sequence_length的句子 logging.info("x_input.shape: %s" % str(x_input.shape)) # (?, 60) if embedding_matrix is None: x_emb = Embedding(input_dim=max_token_num, output_dim=embedding_dim, input_length=max_sequence_length)(x_input) else: x_emb = Embedding(input_dim=max_token_num, output_dim=embedding_dim, input_length=max_sequence_length,weights=[embedding_matrix], trainable=True)(x_input) logging.info("x_emb.shape: %s" % str(x_emb.shape)) # (?, 60, 300)
2.卷积和池化
很多教程里在卷积部分会提一嘴,说embedding出来的张量是三维的,所以按照这个论文来说还要添加一维才能输进卷积层里,这个当初也困扰了我很久。如果是只有一种类型的卷积核,那就愉快的卷积输出就好了,坏就坏在有三种不同窗口的卷积核(2,3,4),你待会算出来的结果还要进行一个池化,不同窗口的卷积核你总不能放在一层进行一个最大池化吧,得多一层维度,这就是那些博客的思想。不过这里用了一个for循环,把不同kernel_size的卷积核分开了,也就不存在要多一个维度的事情了
#2.构建卷积层和池化层 pool_output = [] kernel_sizes = [2, 3, 4] for kernel_size in kernel_sizes: c = Conv1D(filters=2, kernel_size=kernel_size, strides=1)(x_emb)#卷积 p = MaxPool1D(pool_size=int(c.shape[1]))(c)#池化 pool_output.append(p) logging.info("kernel_size: %s c.shape: %s p.shape: %s" % (kernel_size, str(c.shape), str(p.shape))) pool_output = concatenate([p for p in pool_output]) logging.info("pool_output.shape: %s" % str(pool_output.shape)) # (?, 1, 6)
最后展平输出即可。
#3.展平+输出 x_flatten = Flatten()(pool_output) # (?, 6) y = Dense(output_dim, activation='softmax')(x_flatten) # (?, 2) logging.info("y.shape: %s " % str(y.shape)) model = Model([x_input], outputs=[y]) if model_img_path: plot_model(model, to_file=model_img_path, show_shapes=True, show_layer_names=False) model.summary() return model
全代码如下:
import logging %tensorflow_version 2.x import tensorflow as tf from tensorflow.keras.layers import Conv1D, MaxPool1D, Dense, Flatten, concatenate, Embedding,Input from tensorflow.keras.models import Model from tensorflow.keras.utils import plot_model def textcnn(max_sequence_length, max_token_num, embedding_dim, output_dim, model_img_path=None, embedding_matrix=None): #max_sequence_length:句子的长度 #max_token_num:词汇表的长度 #embedding_dim:嵌入矩阵的维度 #output_dim:嵌入矩阵处理后的词向量维度 #1.构建embedding层 x_input = Input(shape=(max_sequence_length,))#输入一个长度为max_sequence_length的句子 logging.info("x_input.shape: %s" % str(x_input.shape)) # (?, 60) if embedding_matrix is None: x_emb = Embedding(input_dim=max_token_num, output_dim=embedding_dim, input_length=max_sequence_length)(x_input) else: x_emb = Embedding(input_dim=max_token_num, output_dim=embedding_dim, input_length=max_sequence_length,weights=[embedding_matrix], trainable=True)(x_input) logging.info("x_emb.shape: %s" % str(x_emb.shape)) # (?, 60, 300) #2.构建卷积层和池化层 pool_output = [] kernel_sizes = [2, 3, 4] for kernel_size in kernel_sizes: c = Conv1D(filters=2, kernel_size=kernel_size, strides=1)(x_emb)#卷积 p = MaxPool1D(pool_size=int(c.shape[1]))(c)#池化 pool_output.append(p) logging.info("kernel_size: %s c.shape: %s p.shape: %s" % (kernel_size, str(c.shape), str(p.shape))) pool_output = concatenate([p for p in pool_output]) logging.info("pool_output.shape: %s" % str(pool_output.shape)) # (?, 1, 6) #3.展平+输出 x_flatten = Flatten()(pool_output) # (?, 6) y = Dense(output_dim, activation='softmax')(x_flatten) # (?, 2) logging.info("y.shape: %s " % str(y.shape)) model = Model([x_input], outputs=[y]) if model_img_path: plot_model(model, to_file=model_img_path, show_shapes=True, show_layer_names=False) model.summary() return model textcnn(max_sequence_length=60, max_token_num=5000, embedding_dim=100,output_dim=100)
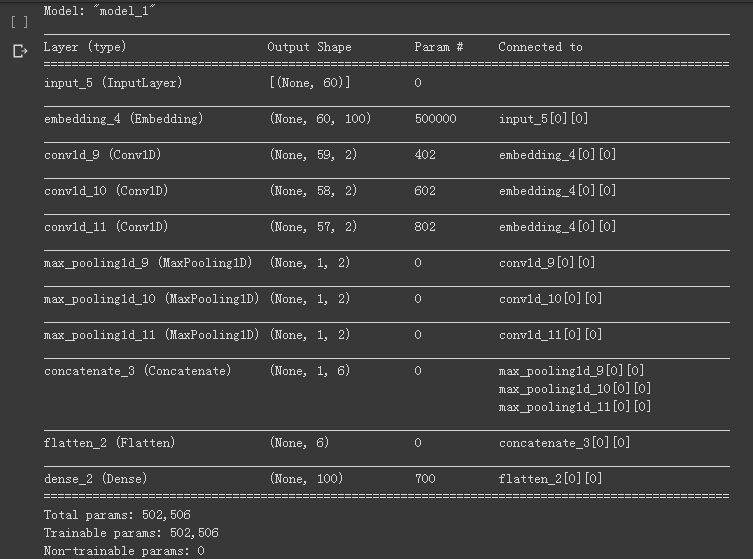
输出结果为: