参考:https://blog.csdn.net/sunhua93/article/details/102764783
一、引入
attention机制就有点像人们找重点,看图片的时候抓住图片上的主体,看文章的时候看中心句。我们对图片上的不同位置,文章中不同部分所投放的attention是不一致的。机器也是会“遗忘”的,比如传统的机器翻译基本都是基于Seq2Seq模型,模型分为encoder层与decoder层,并均为RNN或RNN的变体构成,如下图所示:
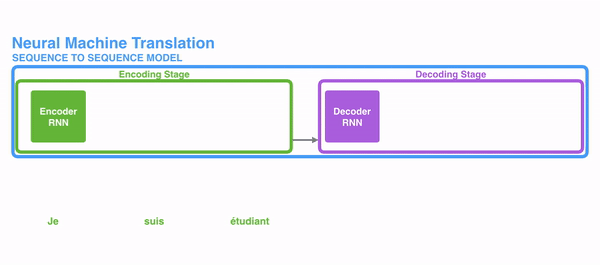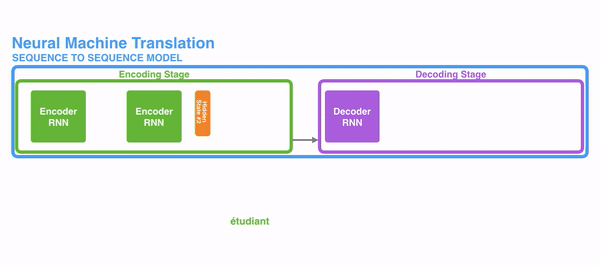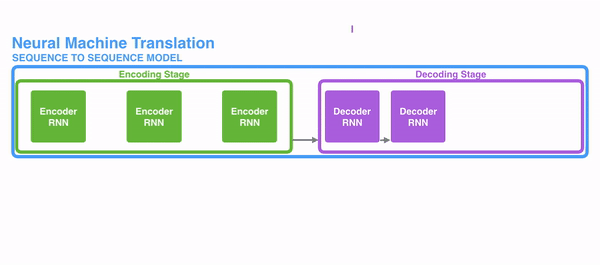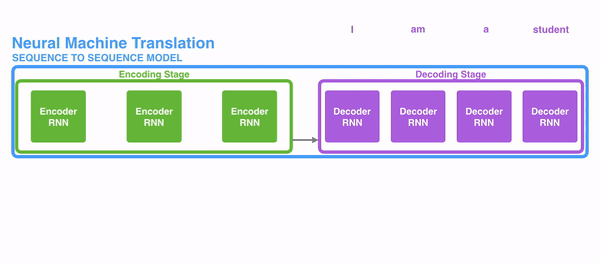
可以看到,在encoding阶段,下一个节点的输入是上一个节点的hidden和当前节点的词,这就是RNN的机制,这里用RNN来进行说明,但实际上attentio是一种思想,不局限于RNN。
然后encoding阶段的最后一个输出,就包含了前面所有词的内容,这里称为C,是一个经过编码器的中间语义表示。毕竟encoding字如其名就是用来编码的。这个编码C,就要用来输入给decoding进行解码工作。
然后decoding中也是相似的处理,把C作为第一个节点的输入,然后得到第一个词;再把第一个节点的hidden输出+C给下一个节点,下一个节点得到一个词,并且把此时的hidden+C输入给再下一个节点再进行处理。
这个模型的一个缺点就是在神经网络中记忆长句子是困难的的。处理长文本时,尽管在encoding阶段,最后一个节点把包含所有节点的内容都提供给decoding阶段了,但是decoder每经过一个节点的处理,就有可能丢失一部分信息,对于除了第一个节点外的节点不公平,后面的节点得到的都不是原汁原味的编码,而是已经被第一个小伙伴处理过的hidden还有输出。
还有一个缺点就是没有体现出注意力,而现实中人们观察某个事物的时候都会带有“注意力”,比如我看一张图片,我会先抓住主体部分。
然后attention的想法就是:
想要使用编码阶段的所有hidden,而不仅仅是最后一个节点输出的中间语义表示C;
然后解码阶段的每个节点,它们对在这些encoders的hidden,注意力分布是不同的,比如想要把“我爱你”翻译成“i love u”,当我们希望生成‘i’时,我们要去决定我们要放多少注意力在第一个词“我”上,又要放多少注意力在“爱”,“你”上,这些注意力就是我们要计算的权重,在希望生成“i”时所给“我”“爱”“你”分配的权重之和为1;然后当我们已经生成了“i”,接下来要生成“love”时,我们又要有一个新的注意力权重集,也就是说,我们重新决定我们要花多少注意力在“我”“爱”“你”三个词上;
然后问题就出现了,怎么确定这个注意力,也就是说给不同节点的hidden分配权重,这个权重怎么确定,这个是attention的核心问题;
二、权重的确定

假如是一个拥有三个词的句子。把三个encoder节点的encoder hidden states的值与decoder当前节点的上一个节点的hidden state相乘,如上图的h1、h2、h3。分别与上一节点的decoder hidden state进行相乘(如果是第一个decoder节点,需要随机初始化一个hidden state),最后会获得三个值,注意,这个数值对于每一个encoder的节点来说是不一样的。这三个值我们称之为scores。就是三个词分别的得分情况。
把该分数值进行softmax计算,主要是为了限制在0-1之间。计算之后的值就是每一个encoder节点的encoder hidden states对于当前decoder的权重,把权重与原encoder hidden states相乘并相加,得到的结果即是当前decoder的一个context vector,随后用于拼接并产生输出值。
第一个decoder的节点因为没有前一个节点,所以我们要初始化一个decoder hidden state 0给第一个decoder,该初始化decoder hidden state作为第一个节点的输入而不是状态,经过第一个decoder后得到一个新的decoder hidden state 1与输出值。对于输出值,这里和Seq2Seq有一个很大的区别,Seq2Seq是直接把输出值作为当前节点的输出,但是Attention会把上一段得到的context与hidden state做一个连接,并把连接好的值送入一个前馈神经网络,最终当前节点的输出内容由这个前馈神经网络决定,重复以上步骤,直到所有decoder的节点都输出相应内容。下图大致说明了这个过程:
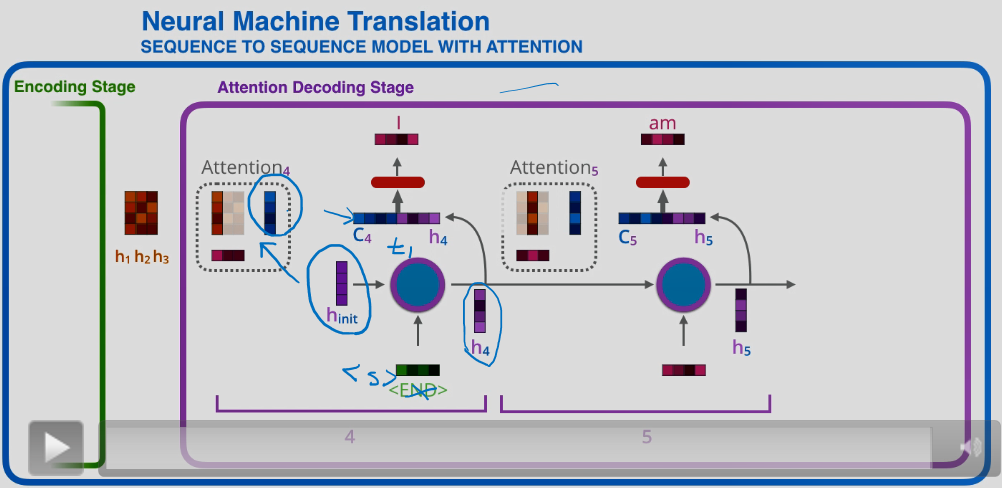
上图中的C4即为如上所述获得的初始时刻context vector ,它是考虑了全文中每个词的权重之后的出来的一个向量。这个向量送到decoder后不能够直接用来预测输出,它要再和h4进行一个拼接。
先看一下h4是怎么得到的。它是上图第一个decoder的隐状态,由上一时刻的隐状态hint和<z>所获得(注意hint做了很多事情,它帮助计算注意力权重,进而得到了context vector;而且它还帮助计算当前decoder的隐状态)。
现在我们拥有了第一个decoder的隐状态h4,以及存在注意力机制的context vector C4。现在我们再将C4和h4进行拼接后,经过full connection层,再经过softmax多分类层,预测当前时刻的输出。
下一时刻:h4与encoders中所有的encoder hidden state计算scores,再通过softmax进行权重分配,加权平均获得一个新的的context vector:C5;h5由h4和当前时刻输入的embedding获得,拼接C5和h5后,经过全连接层和softmax,预测当前时刻的输出。
所以实质上,这个attention到底引入用来干嘛?关键又是什么,就是计算每个解码节点,它们对编码的注意力分布。
其实就是解码过程中,比如机器翻译,每个节点所关注的东西不一样,它们会有各自的隐状态,我们拿上一阶段的隐状态去和每个单词的编码比较,也就是经过一个函数F,就可以得到对不同单词编码的一个分数,再经过softmax就可以计算出权重了。
计算出权重后,我们就可以得到一个语义表示,比如上图中的C4C5,它们都来源于一段句子,只是对句子中的不同单词的注意力不同,然后单单知道这个就行了吗?当然不,我们还要考虑当前节点的隐状态,我们之前确定权重的时候考虑的是上一个节点的隐状态,拿来计算权重的;现在考虑的是这个节点的隐状态,用来计算输出值的。为什么要计算输出值的时候,还要考虑当前的隐状态?这要看当前隐状态是怎么得到的,是用上一阶段的隐状态和上一阶段的输出值得到的,包含了上一阶段的语义信息,比如说翻译的时候,我们不能单单只看一个词的翻译,这样就不是句子翻译了,我们还要去看上一阶段我们翻出来了个啥,才好确定下一阶段我翻出来的是名词还是动词。故我们采用注意力机制,得到了一个语义表示后,还要把这个表示同当前包含历史语义信息的隐状态进行拼接,送入前馈神经网络中进行学习。
现在还有一个问题,大体过程明白了,具体这个注意力机制的根本原理在于什么呢?如下说明,原来是一种通过比较来找到注意力的焦点部分。
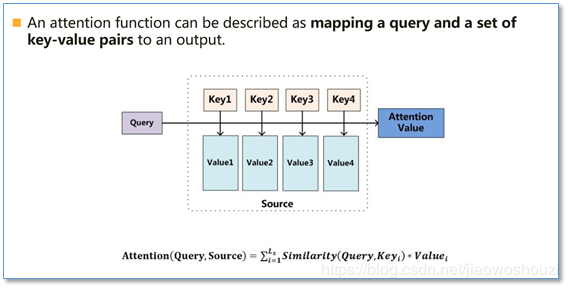
这里的key就是value,就是我们输入句子中每个词的语义编码encoder hidden states。有区分主要是因为我们要拿Query和key进行比较计算,然后再乘以key,为了区分,所以写成value。
然后Query是什么,在自然语言处理中就是我们的decoder的输出结果target中的某个元素。我们拿这个元素去和key进行比较,相似度高的得到的数字就大,得到这个相似度后我们再去乘以value,得到scores,接下来就可以得到权重。
上图写了一个计算attention的方法就是比较相似度。常用的相似度函数有点积,拼接,感知机等。