一、引言
在理解了ELMO和attention之后,在理解transformer就容易很多。transformer中会需要用到前面说的注意力机制,理解了transformer后我们还可以继续往下了解bert的原理。
二、结构
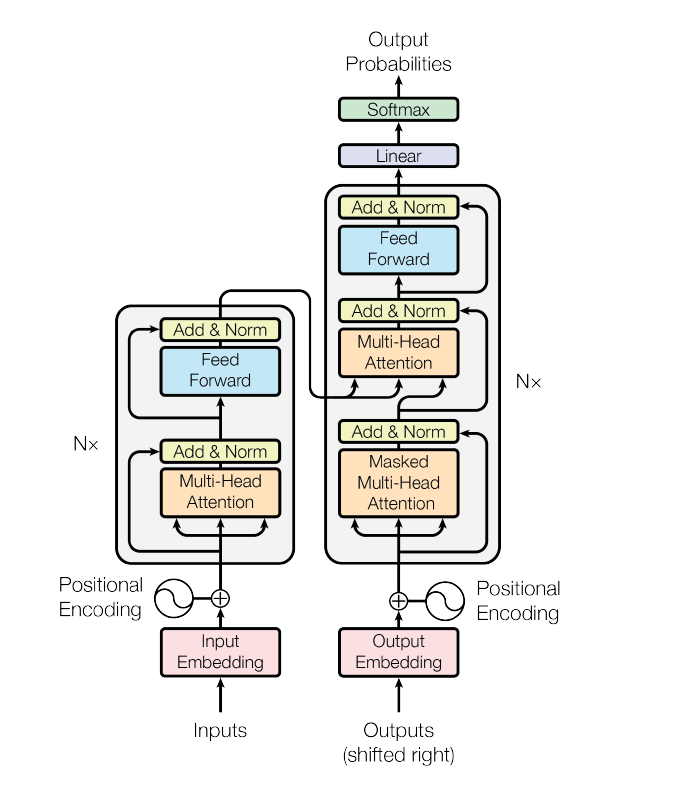
上面这个图大体就可以说明transform的过程了。它主要分为编码器和解码器两大部分,在上图中,左边部分表示编码器,右边表示解码器。
2.1encoder
在一个编码单元encoder中又有两层主要结构:一个是Multi-Head attention,一个是feed forward。
我们的大体过程是首先是将Inputs经过一个embedding层后变成了用向量形式表示的稠密向量,再加上一个这个词的位置信息position,拼接后送入encoder;在encoder这个单元中,先计算多头注意力,得到了注意力权重后,加权求和更新我们的稠密向量,得到这个词的新向量表示后,再加上一个原稠密向量,就是图中的“add norm”做的事情;然后我们把这块东西送入前馈神经网络得到一个该单元的输出。这个就是encoder的output,那么这个encoder的output有什么用,实际上这个图中没有画出来,它画了一个箭头直接指向了右边decoder的Multi-Head attention中。帮助decoder计算encoder-decoder-attention,这个就放在下面讲decoder的时候再说。
然后更细一点讲解encoder的部分
2.1.1attention

我们现在要说的是encoder中的attention,如上图红色方框中的内容。它实际上是一个self-attention,也就是说它attention的内容都来自于encoder本身,至于Multi-Head这个名号安上去表示的是做了不止一次attention,在原论文中安排了h次attention,它们并行计算,也就是每个单词输入进来都会进行h次的attention操作,得到h个注意力加权表示的向量。说这里的encoder是self-attention主要是要和decoder中的attention进行区分:decoder中的attention有两种,一种也是self-attention,attention的内容来自decoder本身,还有一种是encoder-decoder-attention,attention的内容同时来自encoder和decoder,也就是图中encoder指向decoder的部分。

上面的图说明了注意力机制的计算方法,我们有维度为$d_{k}$的queries以及keys,这两个是通过x1乘上Wk和Wq两个矩阵的出来的结果;然后我们还有Values,也是通过X1乘上Wv得到的结果。我们需要拿一个词的query和其他所有词的keys做一个点乘,然后再做一个标准化,就是除以$sqrt{d_{k}}$,再经过一个softmax得到权重,如上图得到的是0.88和0.12,那么我们就可以计算:
$z_{1}=0.88v_{1}+0.12v_{2}$
这个就是我们得到的结果,因为Q和K要进行点乘,所以q和k要维度一样,但是v没有这个要求。这里这句话只有2个词,那么就有2*2的矩阵来表示它们之间的注意力权重,如果是10个词,就有10*10的矩阵来表示。
注意,以上我们只有一个Wk,一个Wq,Wv,所以我们输入一个句子,对于句子中的一个词x1,我们得到的注意力权重个数是句子长度,然后进行加权平均,我们就有了一个z1。上面是解释了self-attention,但是我们开头说过,论文里用的是多头注意力,意味着我们需要有很多个Wk,Wq,Wv,来计算得到很多个z1,这些不同的z1可以理解成从不同的角度去收集句子的信息。当我们得到了很多z1之后,我们再去利用一个矩阵,进行降维即可。如下图:


2.1.2norm
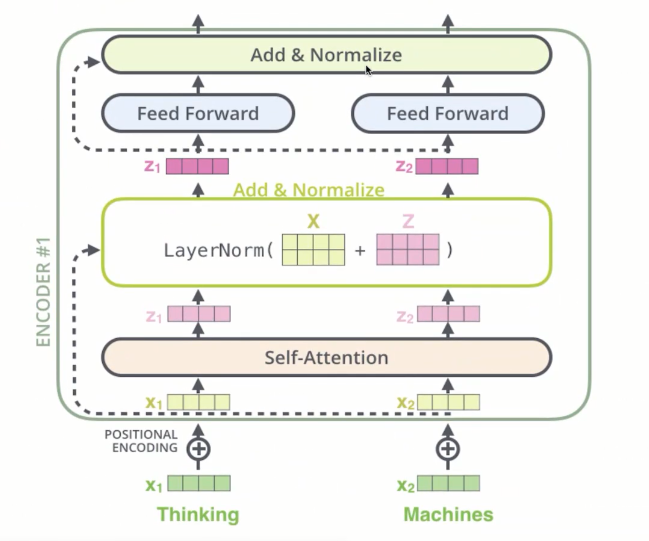
在每个encoder的两个self-attention层和forward层外面都添加了一个residual残差的连接,然后进行了layer nomalization的操作。
2.2decoder
注意就是其实decoder也有自己的输入input,在我们训练的时候,就是我们的target目标句子;在我们使用这个模型的时候,就是目标词的前文,因为这个模型是要用前文来预测下一个词的概率。
2.2.1self-attention
在decoder中的self-attention首先它也是多头注意力机制,但它与encoder中的self-attention不太一样的点就在于:encoder1中的self-attention是一个基于long term的attention,意思就是说在encoder中每个词,需要去计算它分配给全文所有单词的注意力权重,是考虑上下文的;然而decoder中的self-attention,因为decoder是用前文来预测下一个词的,所以decoder只能考虑前文的注意力权重,这是一个不同。其他的机制一样的。
2.2.2encoder-decoder-attention
encoder-decoder-attention和前面讲的编码器和解码器中的self-attention都不大一样,encoder-decoder-attention会同时考虑到两边的selfattention结果,如下图:

我们可以看见,有6个encoder单元叠加而成了一个整体的encoder,这个整体的encoder的output其实有两个,一个是前馈网络的output,一个是最终的self-attention。前馈网络的output会影响decoder前馈网络的的output;另外encoder最终的self-attention会输给右边的六个decoder单元,帮助他们做encoder-decoder-attention计算。
那么就是queries来自于之前的decoder层,而keys和values都来自于encoder的输出。
2.3 positional encoding
由于模型没有任何循环或者卷积,为了使用序列的顺序信息,需要将词的相对以及绝对位置信息注入到模型中去。论文在输入embeddings的基础上加了一个“位置编码”。位置编码和embeddings有同样的维度,所以两者可以直接相加。有很多位置编码的选择,既有学习到的也有固定不变的。总之就是添加了一个有关位置对词的一个影响。