概要:

hadoop和hbase导入环境变量:

要运行Hbase中自带的MapReduce程序,需要运行如下指令,可在官网中找到:
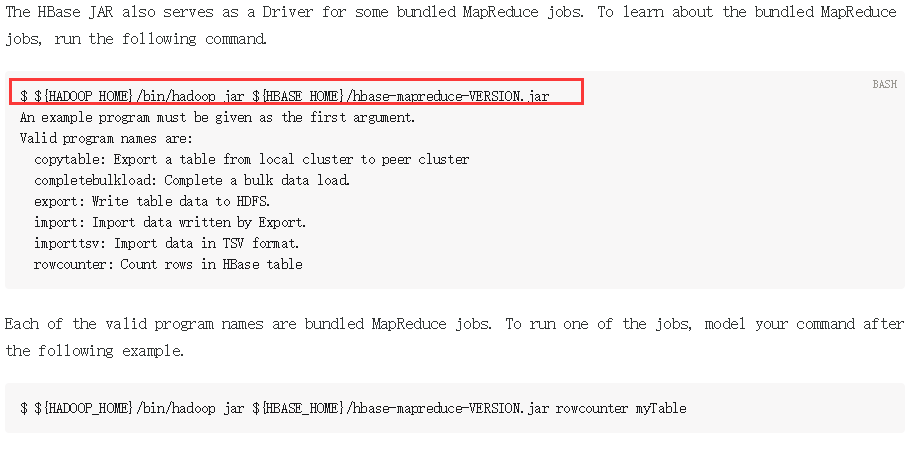
如果遇到如下问题,则说明Hadoop的MapReduce没有权限访问Hbase的jar包:

参考官网可解决:

运行后解决:

导入数据运行指令:
tsv是指以制表符为分隔符的文件
先创建测试数据,创建user文件:

上传至hdfs,并且启动hbase shell:

创建表:

之后导入数据:
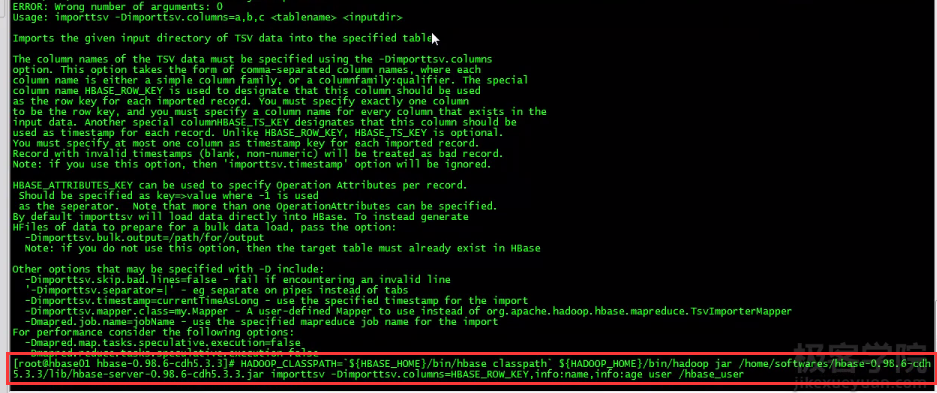
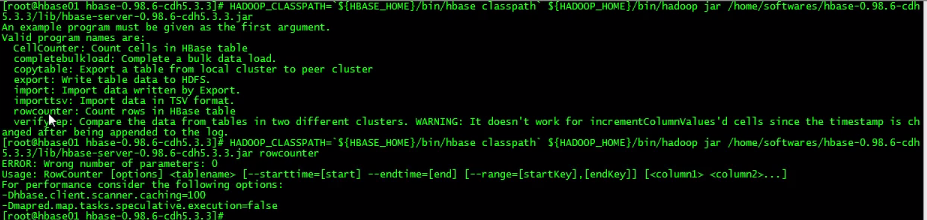
还有一些其他的方法,比如rowcounter统计行数:
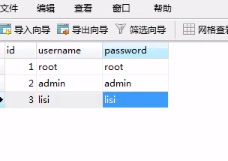
接下来演示用sqoop将mysql数据考入hbase,构建测试数据:
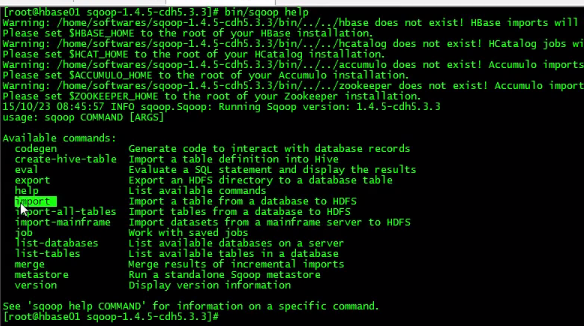
使用import,需要先配置hbase环境变量:


Hbase表数据的迁移:

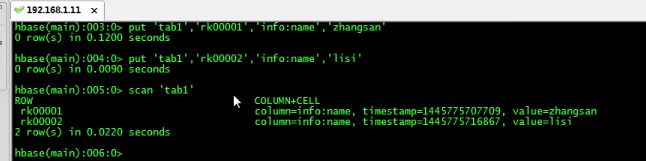
之后编写MapReduce程序,代码如下:
package com.tyx.hbase.mr; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hbase.CellUtil; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.client.Result; import org.apache.hadoop.hbase.client.Scan; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil; import org.apache.hadoop.hbase.mapreduce.TableMapper; import org.apache.hadoop.hbase.mapreduce.TableReducer; import org.apache.hadoop.hbase.util.Bytes; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; public class Tab2TabMapReduce extends Configured implements Tool { // mapper class public static class TabMapper extends TableMapper<Text, Put> { private Text rowkey = new Text(); @Override protected void map(ImmutableBytesWritable key, Result value,Context context) throws IOException, InterruptedException { byte[] bytes = key.get(); rowkey.set(Bytes.toString(bytes)); Put put = new Put(bytes); for (Cell cell : value.rawCells()) { // add cell if("info".equals(Bytes.toString(CellUtil.cloneFamily(cell)))) { if("name".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))) { put.add(cell); } } } context.write(rowkey, put); } } // reduce class public static class TabReduce extends TableReducer<Text,Put, ImmutableBytesWritable> { @Override protected void reduce(Text key, Iterable<Put> values,Context context) throws IOException, InterruptedException { for (Put put : values) { context.write(null, put); } } } @Override public int run(String[] args) throws Exception { //create job Job job = Job.getInstance(this.getConf(), this.getClass().getSimpleName()); // set run class job.setJarByClass(this.getClass()); Scan scan = new Scan(); scan.setCaching(500); scan.setCacheBlocks(false); // set mapper TableMapReduceUtil.initTableMapperJob( "tab1", // input table scan , // scan instance TabMapper.class, // set mapper class Text.class, // mapper output key Put.class, //mapper output value job // set job ); TableMapReduceUtil.initTableReducerJob( "tab2" , // output table TabReduce.class, // set reduce class job // set job ); job.setNumReduceTasks(1); boolean b = job.waitForCompletion(true); if(!b) { System.err.print("error with job!!!"); } return 0; } public static void main(String[] args) throws Exception { //create config Configuration config = HBaseConfiguration.create(); //submit job int status = ToolRunner.run(config, new Tab2TabMapReduce(), args); //exit System.exit(status); } }
运行指令:


接下来是hdfs中文件导入Hbase:
构造数据:


然后编写MapReduce程序:
package com.jkxy.hbase.mr; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil; import org.apache.hadoop.hbase.util.Bytes; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; public class HDFS2TabMapReduce extends Configured implements Tool{ public static class HDFS2TabMapper extends Mapper<LongWritable, Text, ImmutableBytesWritable, Put> { ImmutableBytesWritable rowkey = new ImmutableBytesWritable(); @Override protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException { String[] words = value.toString().split(" "); //rk0001 zhangsan 33 Put put = new Put(Bytes.toBytes(words[0])); put.add(Bytes.toBytes("info"),Bytes.toBytes("name"),Bytes.toBytes(words[1])); put.add(Bytes.toBytes("info"),Bytes.toBytes("age"),Bytes.toBytes(words[2])); rowkey.set(Bytes.toBytes(words[0])); context.write(rowkey, put); } } @Override public int run(String[] args) throws Exception { // create job Job job = Job.getInstance(this.getConf(), this.getClass().getSimpleName()); // set class job.setJarByClass(this.getClass()); // set path FileInputFormat.addInputPath(job, new Path(args[0])); //set mapper job.setMapperClass(HDFS2TabMapper.class); job.setMapOutputKeyClass(ImmutableBytesWritable.class); job.setMapOutputValueClass(Put.class); // set reduce TableMapReduceUtil.initTableReducerJob( "user", // set table null, job); job.setNumReduceTasks(0); boolean b = job.waitForCompletion(true); if(!b) { throw new IOException("error with job!!!"); } return 0; } public static void main(String[] args) throws Exception { //get configuration Configuration conf = HBaseConfiguration.create(); //submit job int status = ToolRunner.run(conf, new HDFS2TabMapReduce(), args); //exit System.exit(status); } }
运行指令
接下来演示使用BulkLaod将数据从Hdfs导入Hbase,使用该方式可以绕过WAL,memstor等步骤,加快海量数据的效率,代码如下:
package com.jkxy.hbase.mr; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.client.HTable; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2; import org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles; import org.apache.hadoop.hbase.mapreduce.PutSortReducer; import org.apache.hadoop.hbase.util.Bytes; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; public class HFile2TabMapReduce extends Configured implements Tool { public static class HFile2TabMapper extends Mapper<LongWritable, Text, ImmutableBytesWritable, Put> { ImmutableBytesWritable rowkey = new ImmutableBytesWritable(); @Override protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException { String[] words = value.toString().split(" "); Put put = new Put(Bytes.toBytes(words[0])); put.add(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes(words[1])); put.add(Bytes.toBytes("info"), Bytes.toBytes("age"), Bytes.toBytes(words[2])); rowkey.set(Bytes.toBytes(words[0])); context.write(rowkey, put); } } @Override public int run(String[] args) throws Exception { //create job Job job = Job.getInstance(getConf(), this.getClass().getSimpleName()); // set run jar class job.setJarByClass(this.getClass()); // set input . output FileInputFormat.addInputPath(job, new Path(args[1])); FileOutputFormat.setOutputPath(job, new Path(args[2])); // set map job.setMapperClass(HFile2TabMapper.class); job.setMapOutputKeyClass(ImmutableBytesWritable.class); job.setMapOutputValueClass(Put.class); // set reduce job.setReducerClass(PutSortReducer.class); HTable table = new HTable(getConf(), args[0]); // set hfile output HFileOutputFormat2.configureIncrementalLoad(job, table ); // submit job boolean b = job.waitForCompletion(true); if(!b) { throw new IOException(" error with job !!!"); } LoadIncrementalHFiles loader = new LoadIncrementalHFiles(getConf()); // load hfile loader.doBulkLoad(new Path(args[2]), table); return 0; } public static void main(String[] args) throws Exception { // get configuration Configuration conf = HBaseConfiguration.create(); //run job int status = ToolRunner.run(conf, new HFile2TabMapReduce(), args); // exit System.exit(status); } }
使用如下指令: