一、mysql主从延迟的判断指标
方法一:延迟时间
Seconds_Behind_Master: 0 此值作为监控主从延迟不是那么准确,此值计算的是主库的binlog的时间和从库的执行relay log的时间差,如果主从存在很大的网络延迟,那么这个值就不是那么的准确,可以参考如下链接
https://www.sohu.com/a/317335842_610509
方法二: 主库: mysql> show master status ;
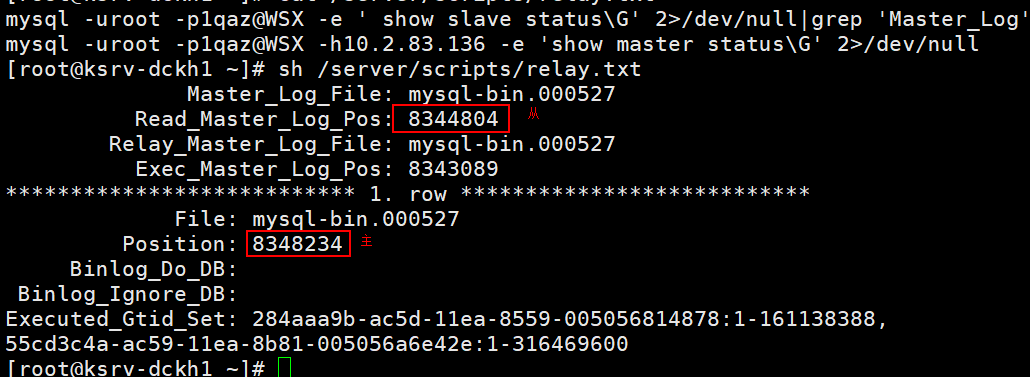
从库: [root@db01 data]# mysql -e "show slave status G"|grep "Master_Log" 已经拿到的主库日志量(master.info):判断传输有没有延时 Master_Log_File: mysql-bin.000004 Read_Master_Log_Pos: 151847
已经执行的主库日志(relay-log.info): 判断回放有没有延时 Relay_Master_Log_File: mysql-bin.000004 Exec_Master_Log_Pos: 141847
计算主从复制延时日志量。
从库执行判断脚本(得出的值为Read_Master_Log_Pos-Exec_Master_Log_Pos的值,单位为KB,可以监控此值来判断延迟多少数据量)
/usr/local/mysql/bin/mysql -uroot -pxxxxxx -e "show slave status G" 2>/dev/null|grep "Master_Log"|awk '{print $2}'|sed -n '2p;4p'|awk 'NR==1 {tmp=$1} NR>1 {print tmp-$1;tmp=$1}'
二、延迟原因排查
1.主库原因分析
binlog记录不及时,表现形式就是主库的show master的gtid大于slave接受的gtid号,有可能主库的IO压力太大,主库dump线程压力太大,也有可能网络延迟严重,在向从库同步binlog的时候,速度有延迟。
解决:可以降低双一标准,提高IO和网络延迟
例如如下:
mysql> select @@sync_binlog;
+---------------+
|@@sync_binlog |
+---------------+
| 1 |
+---------------+
参数说明:
1 : 每次事务提交都立即刷新binlog到磁盘。
0 : 由操作系统决定,什么刷新磁盘。
sync_binlog:这个参数是对于MySQL系统来说是至关重要的,他不仅影响到Binlog对MySQL所带来的性能损耗,而且还影响到MySQL中数据的完整性。对于“sync_binlog”参数的各种设置的说明如下:
sync_binlog=0,当事务提交之后,MySQL不做fsync之类的磁盘同步指令刷新binlog_cache中的信息到磁盘,而让Filesystem自行决定什么时候来做同步,或者cache满了之后才同步到磁盘。
sync_binlog=n,当每进行n次事务提交之后,MySQL将进行一次fsync之类的磁盘同步指令来将binlog_cache中的数据强制写入磁盘。
在MySQL中系统默认的设置是sync_binlog=0,也就是不做任何强制性的磁盘刷新指令,这时候的性能是最好的,但是风险也是最大的。因为一旦系统Crash,在binlog_cache中的所有binlog信息都会被丢失。而当设置为“1”的时候,是最 安全但是性能损耗最大的设置。因为当设置为1的时候,即使系统Crash,也最多丢失binlog_cache中未完成的一个事务,对实际数据没有任何实质性影响。
从以往经验和相关测试来看,对于高并发事务的系统来说,“sync_binlog”设置为0和设置为1的系统写入性能差距可能高达5倍甚至更多。
show variables like 'sync_binlog';
set global sync_binlog=0;
***优化方式***:
调整双一标准:
sync_binlog=n
innodb_flush_log_at_trx_commit=2
调整数据库事务隔离级别为RC:
select @@tx_isolation; 查看当前的隔离级别
set global tx_isolation = 'READ-COMMITTED' 在线调整隔离级别
set session transaction isolation level read committed;设置当前事务的隔离级别
永久生效:修改/etc/my.cnf
transaction-isolation = READ-COMMITTED
参考如下链接:
https://blog.csdn.net/weixin_30800151/article/details/113196750
2.从库原因分析
# IO线程:
从库IO比较慢。relay 落地慢。可以将realy放到 SSD
# SQL 线程: 串行回放。
从库串行回放的条件:
主库开启组提交,只有主库在同一个commit组提交的事务从库的SQL线程才可以并行回放。
主库开启组提交的方式:
https://www.cnblogs.com/liuxiuxiu/p/12720242.html
主库可以并行事务,从库SQL线程串行回放。
所以:并发事务高、大事务、DDL
解决方法: 5.6 版本: 开启GTID后,可以多SQL线程,只能针对不同的库的事务进行并行SQL恢复。
5.7 版本: 做了增强,基于逻辑时钟的并行回放。MTS。 LAST_COMMIT(BINLOG_GROUP_COMMIT) SEQ_NUM.
5.7 的从库并发配置方法。
gtid_mode=ON
enforce_gtid_consistency=ON
log_slave_updates=ON
slave-parallel-type=LOGICAL_CLOCK
slave-parallel-workers=4
master_info_repository=TABLE
relay_log_info_repository=TABL
3. 从库延迟sql线程卡在某个Gtid上不向下执行,可能是从主库上同步的大的事务,执行时间比较久,判断是什么事务的方式:
1)mysql> show slave statusG 查看目前sql线程执行的事务对应的主库的binlog的GTID

2)mysql> show slave statusG 查看目前sql线程执行的事务对应的从库的的relay log的GTID
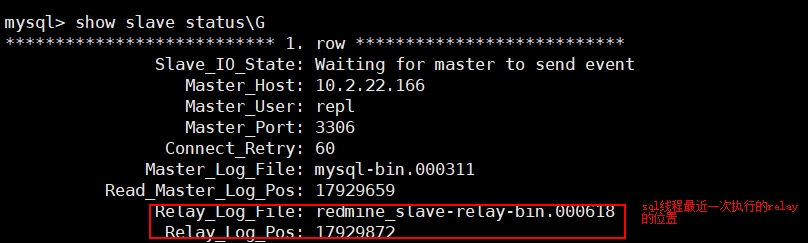
如果刚好卡在某个事务不动了,可以通过在主库上:
mysqlbinlog --no-defaults --base64-output=decode-rows -vv mysql-bin.000311 >/tmp/171.sql 找到对应的gtid 比如上图的166523036,看看是什么大事物导致的
或者:
在从库上:
mysqlbinlog --no-defaults --base64-output=decode-rows -vv redmine_slave-relay-bin.000618 >/tmp/171.sql 找到对应的gtid 比如上图的17929872,看看是什么大事物导致的
也可以show processlist看看是否有什么sql在跑。