今天又阅读了最近的一篇NeurIPS 2020的文章,提出了一个减少图片空间冗余程度实现动态推理的方法。之前也看过一些减少空间冗余度的,但是本文所用的方法是对于一张图片来说,裁剪成相同大小的一个个patch以序列的方式输入到网络中,同时网络分为多个阶段,分别处理不同的输入,其核心点有两个一个是对于图片patch的定位,其次是实现动态推理。为了划分patch,单独训练了一个patch proposal network,为一个RNN结构,其输入不仅包括patch本身还有每一个阶段图像经过处理后的feature map,通过强化学习的方式进行训练,在每一次划分的结果输入普通的图像CNN网络中进行预测后与上一个patch的预测结果做对比后返回一个reward,来保证这个patch建议网络每次都可以尽可能的输出更具区分度的patch区域。分类器也是一个RNN结构,两个RNN都是用了GRU,在每一次输出预测结果后,还将本次的预测结果传给下一个阶段的分类器,也就是RNN的主要原理。在推理层面上也继续沿用了一贯的budgeted batch classification的测试方法实现动态推理,其代码具体实现部分在上篇博客里已经有详细介绍。
paper: https://arxiv.org/abs/2010.05300
code: https://github.com/blackfeather-wang/GFNet-Pytorch
Abstract
通常高分辨率图像对于CNN来说会有较高的准确性,但它同样也带来了较高的计算成本与空间冗余。从事实中可以得知对于一张图片来说并不是所有的部分都对最后的分类结果相关。我们通过处理一系列相对较小的输入提出了一种全新的结构,这些较小的输入是由策略性地通过强化学习的方式从原始图片当中得出,一旦模型对于预测具有足够的自信,就可以终止该自适应推理,这个框架可以和现有的轻量级CNN很好的融合,在iPhone XS Max上的MobileNet-v3平均时延降低了20%.
Introduction
CNN已经在224x224,320x320的图片上取得了非常好的结果,现在甚至有工作将分辨率调整至更大去获取更高的一个准确率,但是计算开销是巨大的,并且根据图像的尺寸大小呈二次方的上涨。本文的目的就是要降低高分辨率图像中的空间冗余问题。事实上,我们发现CNN只需要通过一些具有类别特性的图像块就可以进行正确的分类,例如小狗的头或者是鸟的翅膀,如果只用在这些部分做处理就可以在得到正确推理的同时减少计算开销。面对这样的问题,存在两个挑战:
- 如何定义具有类别区分度的区域
- 如何给每个图片动态的分配资源,毕竟对于不同的图片其区分度区域的数量和大小都是不一样
这个框架分为两个阶段,分别是glance和focus,总体被称为Glance and Focus Network(GFNet)
- glance:具体来说,区域的选择是一个顺序决策的过程,每一个阶段我们的模型会处理一个相对较小的输入生成一个关于类别的预测置信度和下一各区域的建议。由于减小了图像的尺寸,因此可以高效地完成每个步骤。 例如,推断96×96图像补丁的计算成本仅为处理原始224×224输入的计算成本的18%(尺寸的平方倍)。 整个顺序过程始于以降采样的比例(例如96×96)处理整个图像,被称为“扫视”步骤,在该步骤中,模型会使用全局信息对输入图像进行快速预测。 在实践中,我们发现,具有类别区分度特征的大部分图像已经可以在扫视步骤中以高置信度正确分类。
- focus:在glance步骤未能对其预测结果产生足够高的置信度时,将输出最具类别区分度的区域建议,该阶段通过迭代的定位和处理图像中的部分区域,并且以自适应的方式尽可能早的终止。
如下图所示,在测试时其计算资源会被不均匀的分配给不同的图像,从而提高效率,对于鹰的图片在glance阶段就已经产生较高置信度表示已得出结果,下面的两张图分别经历了两次和三次才最终找到一个置信度较高的结果。

值得注意的是,GFNet被设计为通用框架,分类与提议网络是两个独立的模块,所以可以和大多数轻量级网络兼容,并且专注于在自适应推理领域提高计算效率。并且,只要我们能确定所需要处理的区域的大小就可以显著的减少内存,可以充分灵活地利用计算资源,我们也在多种CNN上进行了实验。
Method
介绍方法的详细信息。 如前所述,CNN能够对某些“类别区分”图像区域(例如狗的脸或鸟的翅膀)产生准确的图像分类结果。 受此观察的启发,我们提出了GFNet框架,旨在通过对最小图像区域进行计算以获得可靠的预测来提高CNN的计算效率。 具体而言,GFNet根据图像的不同区域对最终分类的潜在贡献,将计算自适应地和渐进地分配给图像的不同区域,并且一旦网络有足够的信心,该过程就会终止。
Overview
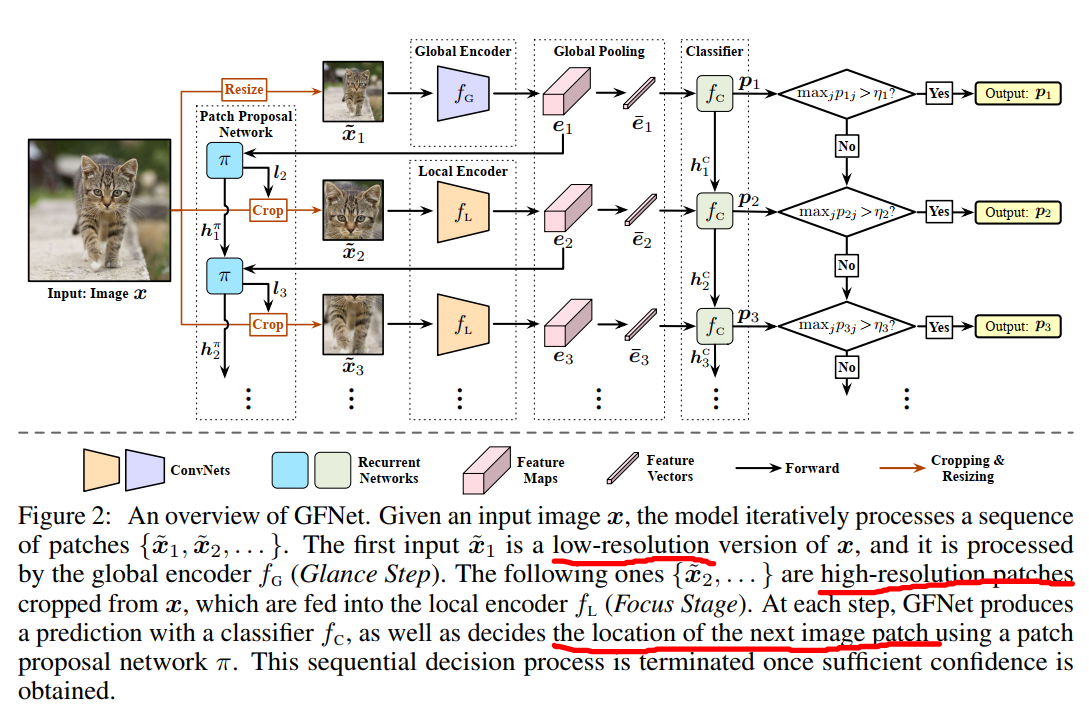
对于输入的(H imes W)图片,我们将处理一系列的(H' imes W') 较小的输入序列(left{ ilde{x}_1, ilde{x}_2,... ight}),其中除了( ilde{x}_1)以外都是从原始图片中的一定区域中裁剪的,裁剪的每一块的位置是利用先前所有的输入放入网络中动态决定的。
理想情况下,输入对于分类的贡献度应按照降序排列,所以计算资源应该有限分配给他们,但对于任意一张图片很难知道第一个patch设置在哪里,所以第一个patch就是原始图像resize之后的结果。不仅避免了由于随机定位初始区域而导致在次重要区域上浪费计算的风险,而且还给确定patch区域提供了有利的全局信息
- Inference 在第(t)个动态决策的过程中,CNN backbone接受输入( ilde{x}_t),产生一个(softmax)置信度(p_t),其中的最大值会和一个预训练好的阈值作比较,如果大于则输出结果作为最终预测结果,如果小于则决定下一个被裁减的patch,作为第(t+1)阶段的输出。值得注意的是预测(p_t)与确定下一个位置是通过两个循环网络获得的,因此它们利用了先前所有的输入信息,计算阈值的方法和之前介绍的类似。
- Training 在训练阶段,我们取消提前退出,以所有softmax结果中的最大值作为输出预测,对于patch的定位,我们选择相邻两个阶段之间ground truth标签上softmax预测结果增量最大的patch,也就是意味着一直希望能够找到网络当前尚未发现的最具有类别区分度的区域。这一步骤利用策略梯度算法解决不可微(policy gradient algorithm)
GFNet Architecture
网络结构共包括四个模块:全局编码器(f_G),局部编码器(f_L),分类器(f_c),和一个patch建议网络(pi)。
-
Global encoder (f_G) and local encoder (f_L)
两种都是用来提取图像特征,共同的网络结构但是参数不一样,global用来缩小原始图片。后面的用于patch,我们使用两个网络而不是一个,因为我们发现低分辨率输入( ilde{x}_1)与高分辨率patch之间存在差异,这会导致单个编码器的性能下降
-
Classifier (f_C)
(f_C)是一个循环网络,将所有先前的输入信息进行汇总,并在每个步骤产生一个预测,我们假设( ilde{x}_t)输入编码器,包含对应的feature map (e_t),用一个全局平均池化得到特征向量,然后通过(p_t=f_C(overline{e}_t,h_{t-1}^c))计算出预测值(p_t),(h_{t-1}^c)是(f_C)的隐含状态,在第(t-1)阶段更新。注意,不必为分类器维持着特征图因为分类通常不依赖空间信息,循环分类器和之前提到的两个编码器由下面的loss训练得到。
[L_{cls}=frac{1}{|D_{trian}|}sum olimits_{(x,y)in{D_{train}}}left[frac{1}{T}sum olimits_{t=1}^{T}L_{CE}({p_t},y) ight] ](D_{train})是训练集,(y)是(x)对应的label,(T)是输入序列的最大长度,(L_{CE}())是standard cross-entropy loss function
-
Patch proposal network
这一部分在我看来就是本文的创新点所在,用一个循环网络决定每张图片patch的位置,鉴于该网络的输出是不可微的裁剪操作,我们将其视为一个agent并且用策略梯度法(policy gradient method)对其进行训练。在第t个阶段,接收( ilde{x}_t)的特征图(e_t),从(pi)建立的一个分布(l_{t+1}simpi(l_{t+1}|e_t,h_{t-1}^pi))中随机选取一个区域(l_{t+1}),(h_{t-1}^pi)为隐含状态,(l_{t+1})为下一个patch( ilde{x}_{t+1})的中心点坐标,在训练中我们使用一个高斯分布,均值由(pi)输出,标准差被定义为超参数。在测试时,我们只需采用平均值(l_{t+1})即可进行确定性推理过程。隐藏状态汇总了过去所有特征图(left{e_1,...e_t ight})的信息。我们并不对特征图进行任何池化操作,因为特征图中的空间信息对于定位patch十分重要。所以我们通过1x1卷积来减小feature的channel数。这种设计抛弃了对分类有用对定位没什么用的信息,结构请看下图
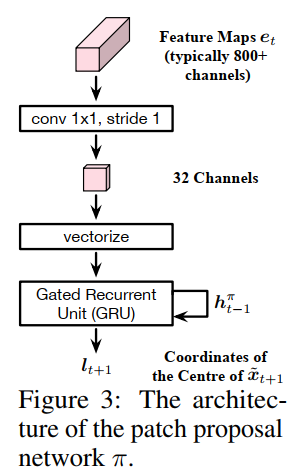
在训练过程中,在获得(l_{t+1})之后,我们将从原图片以(l_{t+1})为中心裁剪成为(H' imes W')的patch作为下一个的输入,放进网络中生成预测结果(p_{t+1})。patch proposal网络将对生成(l_{t+1})的行为得到一个reward (r_{t+1}),被定义为在真实值标签上预测结果softmax的增量,即(r_{t+1}=p_{(t+1)y}-p_{ty}, yinleft{1,...,C ight}),C为类别数,该网络的目标就是要最大化这个折扣奖励的和:
其中(gammain(0,1))是一个提前定义好的折扣参数,通过上述直观的等式,我们尽可能让(pi)以尽可能少的patch产生高置信度的预测结果。 从本质上讲,我们训练(pi)来预测每个步骤中用于图像分类的最有利区域的位置。 请注意,由于我们计算了预测概率的“增量”,因此该过程也考虑了先前的输入。
Training Strategy
-
Satge I
首先我们并没有将(pi)网络集成到GFNet中,取代而之的是在每一步中随即裁剪patch并在整个输入图像上均匀分布,训练(f_G,f_L,f_c)让分类的loss (L_{cls})最小,这一阶段训练网络以适应任意输入序列
-
Stage II
第二阶段固定从第一阶段来的两个编码器和分类器,并调用随机初始化的patch proposal网络(pi)来确定每个patch 的位置,我们用策略梯度算法来训练网络(pi)让总的reward值最大
-
Stage III
最后我们对于两个编码器和分类器加上固定的网络(pi)通过学习的patch选择策略进行微调
Implement details
-
(f_G,f_L)的初始化
局部编码器(f_L)使用ImageNet预训练好的模型进行初始化,由于全局编码器fG以较低的分辨率处理调整大小后的图像,因此我们首先将所有调整后的训练样本的大小调整为(H' imes W')有趣的是,仅使用低分辨率图像对预训练模型进行微调有助于提高网络效率。
-
Recurrent Network
我们在(f_C,pi)中使用了
gated recurrent unit(GRU)对于MobileNets-V3和EfficientNets,我们使用级联的全连接层来提高实施效率。 -
Regularizing CNN
在前面的loss方程中添加了一正则化项,旨在保持两个CNN学习线性可分离的能力
[L'_{cls}=frac{1}{|D_{trian}|}sum olimits_{(x,y)in{D_{train}}}left[frac{1}{T}sum olimits_{t=1}^{T}left[L_{CE}({p_t},y)+lambda L_{CE}(Softmax(FC_t(overline e_t)),y) ight] ight] ](lambda>0)是一个预先定义好的参数,在每一阶段又定义了一个全连接层(FC_t),用特征向量(overline e_t)计算计算softmax交叉熵loss,当最小化(L_{cls})时,由于所有的梯度都流向(f_C),因此不直接监督两个编码器,而(L'_{cls})强制实施了线性化的深层特征空间
-
Confidence threshold
每一个step都会分配一个概率,并且具有一个相应的计算成本,利用类似于之前budgeted的方法根据分配的概率去找threshold
-
Policy gradient algorithm
用
proximal policy optimization(PPO)算法训练(pi)
Experiments
-
result


-
可视化

-
Ablation Study

Conclusion
在本文中,我们引入了Glance and Focus Network(GFNet),以减少图像分类任务中的空间冗余。GFNet以顺序方式处理给定的高分辨率图像。在每个步骤中,GFNet都会处理较小的输入,该输入可以是原始图像的降采样版本,也可以是裁剪的patch。 GFNet会逐步执行分类,并为下一步定位判别区域。 一旦获得足够的分类置信度,该过程就终止,从而导致自适应方式。 我们的方法与各种现代CNN兼容,并且易于在移动设备上实现。 在ImageNet上进行的大量实验表明,即使在理论上和经验上,即使在大多数SOTA轻量CNN的基础上,GFNet都能显着提高计算效率。
Appendix
-
Recurrent Networks-GRU
对于RegNets,MobileNets-V3和EfficientNets,我们在patch提议网络(pi)中使用具有256个隐藏单元的门控循环单元(GRU)。 对于ResNets和DenseNets,我们采用1024个隐藏单元,并删除(pi)中的卷积层。 这不会影响效率,因为与两个编码器相比,π的计算成本可忽略不计。 关于循环分类器(f_C),对于ResNets,DenseNets和RegNets,我们使用具有1024个隐藏单元的GRU。 对于MobileNets-V3和EfficientNets,我们发现尽管具有大量隐藏单元的GRU分类器可实现出色的分类精度,但在效率方面却过于昂贵。 因此,我们用级联的完全连接的分类层代替了GRU。 具体来说,在第t步,我们将所有先前输入fē1的特征向量连接起来(left{overline{e}_1,...overline{e}_t ight}),并使用大小为(tF imes C)的线性分类器进行分类,其中F是特征维数,C是类数。 同样,在第(t + 1)步使用另一个((t+1)F imes C)线性分类器。 总共,我们有T个线性分类器,大小为F×C,2F×C,...,TF×C。
-
Policy Gradient Algorithm
太难了没看懂
-
Training Details
-
初始化。 如本文所述,我们使用ImageNet预训练模型初始化局部编码器(f_L),而首先通过微调预训练模型并将所有训练样本的大小调整为H'×W'来初始化全局编码器(f_G)。 具体来说,对于ResNets和DenseNets,我们使用pytorch提供的预训练模型,对于RegNets,我们使用其论文提供的预训练模型,对于MobileNets-V3和EfficientNets,我们使用 首先按照他们的论文中提到的所有细节从头开始训练网络,以匹配报告的性能,然后将获得的网络用作预训练的模型。 对于H'×W'微调,我们使用与训练过程相同的训练超参数。值得注意的是,当将MobileNets-V3和EfficientNets用作backbone时,我们在初始化后固定全局编码器(f_G)的参数,并且不再对其进行训练,这对于Glance Step的最终性能是有益的。
-
第一阶段。我们使用SGD优化器训练所有网络,并采用余弦学习速率退火技术,且Nesterov动量为0.9。 mini-batch的大小设置为256,而RegNets的L2正则化系数设置为5e-5,其他网络的L2正则化系数设置为1e-4。 分类器(f_C)的初始学习率设置为0.1。 对于这两种编码器,ResNets,DenseNets,RegNets,MobileNets-V3和EfficientNets的初始学习率分别设置为0.01、0.01、0.02、0.005和0.005。 对于ResNets,DenseNets和RegNets,将正则化系数λ设置为1,将MobileNets-V3和EfficientNets设置为5。 我们训练ResNets,DenseNets和RegNets达到60个时代,MobileNets-V3达到90个epoch,EfficientNets达到30个epoch。
-
第二阶段。 我们使用具有附录中提供的超参数的Adam优化器训练patch提议网络π。 在所有实验中,我们从中采样定位作用(l_t)的高斯分布的标准偏差设置为0.1。
-
第三阶段。 我们使用与阶段I相同的超参数,但对分类器(f_C)使用的初始学习率为0.01。 此外,由于我们没有目睹性能的提高,因此我们不对EfficientNets执行此阶段。
-
输入尺寸和阶段长度T和对应的编码器如表所示

-
-
Effects of Low-resolution Fine-tuning
如本文所述,我们的方法通过首先对所有训练样本的大小调整为H’×W‘的预训练模型进行微调来初始化全局编码器(f_G)。一个有趣的观察是,低分辨率微调提高了计算效率。下图中报告了与基准和GFNets相比较的微调模型的性能。重要的是,这些微调模型所实现的改进实际上已包含在我们的GFNet中,因为Glance步骤的性能主要取决于低分辨率微调。 另一方面,我们的方法能够通过Focus Stage进一步提高测试准确性,并在线调整平均计算成本。

-
Comparisons with MSDNet in Budgeted Batch Classification
从训练集中选取5w张图片作为一个额外的验证集去估计阈值的置信度,用剩余的样本训练网络,用Fig4(a)中的作比较,如下图

To learn
- GRU
- loss正则化
- PPO算法
如有问题欢迎指正与讨论