1.map方法读取一个文件的一行记录进行分析, 输入:LongWritable(当前读取的文件位置), Text(内容)
2.map将读取到的信息进行分类,输入Context (键值对) ;作为Reduce 的输入数据:
1)其中reduce 中的输入数据的先后是有顺序的,reduce-task 会先将所有的输入数据的Key先做一个排序
2)然后先处理输入的每一组数据按key的排序依次处理,
3.如何分组输入的所有的map结果中的key,mapreduce 使用的是一个GroupingComparator的类,的compare(o1,o2) 方法,如果方法放回0则相等;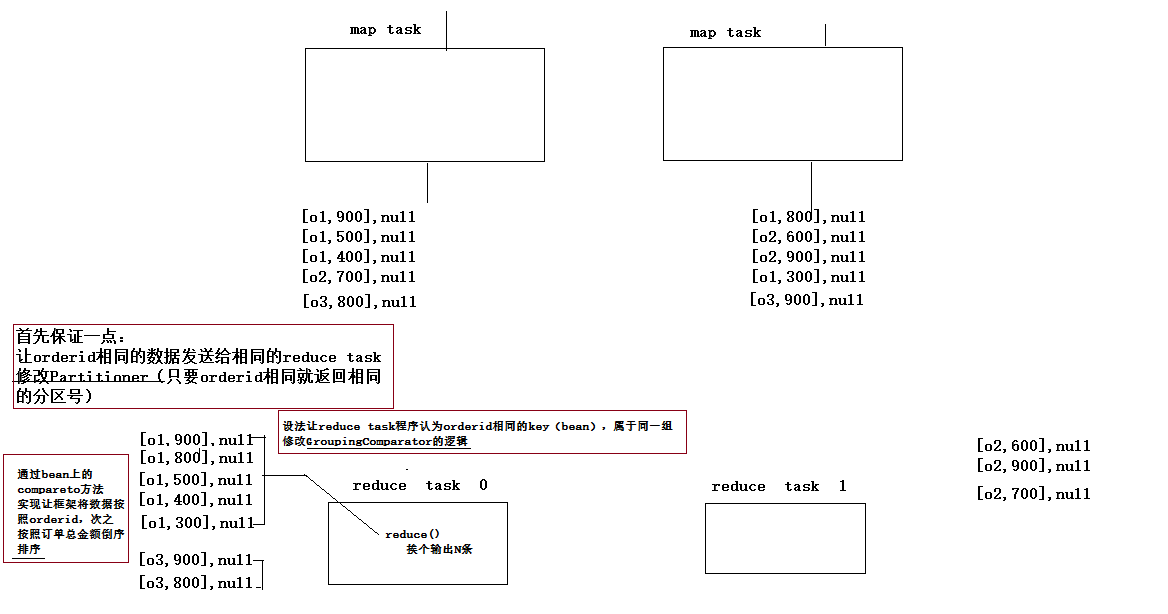
3.当所有的map运行完后,mapreduce 框架 会通过一个Patitioner 类进行reduce输入数据的分发.
默认的分发规则为:通过比较两个key的hashCode值与reduce个数取摩,
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K2 key, V2 value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}返回的摩就是目标reduce task