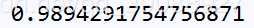首先,我们准备了0~9的训练集和测试集,这些手写体全部经过像素转换,用0,1表示,有颜色的区域为0,没有颜色的区域为1。实现代码如下:
# 图片处理 # 先将所有图片转为固定宽高,比如32*32,然后再进行处理 from PIL import Image as img f = open('f:/result/weixin.txt', 'a') im = img.open('f:/data/weixin.jpg') # im.save('f:/data/weixin.bmp') length = im.size[0] # 长 width = im.size[1] # 宽 # k=im.getpixel((1,9)) #获取图片某个像素的色素 for i in range(0, length): for j in range(0, width): RGB = im.getpixel((i, j)) RGB_SUM = RGB[0] + RGB[1] + RGB[2] if RGB_SUM == 0: # 说明当前位置为黑色 f.write('1') else: f.write('0') f.write(' ') f.close()
手写数字体转换为0,1像素矩阵如下:
我们一共准备了1934个训练集和934个测试集,分别为0~9的手写体像素矩阵
基于贝叶斯模型对手写体数字进行识别
贝叶斯模型实现代码:
from numpy import * from os import listdir class Bayes: def __init__(self): self.length = -1 # 如果未进行训练,则length为-1 self.labelcount = dict() self.vectorcount = dict() def fit(self, dataSet: list, labels: list): if (len(dataSet) != len(labels)): raise ValueError("输入的测试数组和类别数组不一致") self.length = len(dataSet[0]) # 测试数据特征值的长度 labelsnum = len(labels) # 所有类别数量 no_repeat_lables = len(set(labels)) # 不重复类别的数量 for item in range(no_repeat_lables): # 当前类别的数量占总类别数量的比例 self.labelcount[item] = labels.count(item) / labelsnum for vector, label in zip(dataSet, labels): if (label not in self.vectorcount): self.vectorcount[label] = [] self.vectorcount[label].append(vector) print('训练结束') return self def btest(self, TestData, labelSet): if (self.length == -1): raise ValueError("还未进行训练") # 计算当前testdata分别为各个类别的概率 lbDict = dict() for thislb in labelSet: p = 1 alllabel = self.labelcount[thislb] allvector = self.vectorcount[thislb] vnum = len(allvector) allvector = array(allvector).T for index in range(0, len(TestData)): vector = list(allvector[index]) p = p * vector.count(TestData[index]) / vnum lbDict[thislb] = p * alllabel # 当前标签的概率 thislabel = sorted(lbDict, key=lambda x: lbDict[x], reverse=True)[0] return thislabel
之后,我们利用建立好的贝叶斯模型加载训练集、训练模型,实现代码如下:
# 加载数据 def dataToArray(filename): arr = [] f = open(filename) for i in range(0, 32): thisline = f.readline() for j in range(0, 32): arr.append(int(thisline[j])) return arr # 建立一个函数取文件名前缀 def seplabel(fname): filestr = fname.split(".")[0] label = int(filestr.split("_")[0]) return label # 建立训练数据 def traindata(): labels = [] trainfile = listdir("f:/data/traindata/") num = len(trainfile) # 长度1024(列),每一行存储一个文件 # 用一个数组存储所有训练数据,行:文件总数,列:1024 trainarr = zeros((num, 1024)) for i in range(0, num): thisfname = trainfile[i] thislabel = seplabel(thisfname) labels.append(thislabel) trainarr[i, :] = dataToArray("f:/data/traindata/" + thisfname) return trainarr, labels 在对数据进行训练后,我们建立好的模型对测试数据中的手写体"8"进行测试,实现代码如下: # 抽某一个测试文件出来进行试验 trainarr, labels = traindata() thistestfile = "8_76.txt" testarr = dataToArray("f:/data/testdata/" + thistestfile) b = Bayes() b.fit(trainarr, labels) label = b.btest(testarr, labels) print(label)
结果如下:

结果证明贝叶斯方法可以准确地识别出手写体“8”,接下来我们对贝叶斯方法的精度进行测试,这次我们对所有的测试集进行识别,实现代码如下:
# 识别多个手写体数据 testfile = listdir("f:/data/testdata/") num = len(testfile) count = 0 for i in range(0, num): this_file = testfile[i] this_label = seplabel(this_file) # 正确的label test_arr = dataToArray("f:/data/testdata/" + this_file) result = b.btest(test_arr, labels_all) if (result == this_label): count += 1 acc = count / num print(acc)
结果显示,最终精度为:

实验结果还不错,证明贝叶斯模型的确是一个较好的分类模型
基于KNN模型对手写体数字进行识别
接下来我们使用KNN对手写体数字进行识别,实验控制变量,继续采用之前的测试集和数据集。
首先,我们实现KNN模型:
from numpy import * import operator from os import listdir def knn(k, testdata, traindata, labels): traindatasize = traindata.shape[0] dif = tile(testdata, (traindatasize, 1)) - traindata # 扩展数组行 sqdif = dif ** 2 sumsqdif = sqdif.sum(axis=1) # 行求和 dis = sumsqdif ** 0.5 # 距离 sort_dis = argsort(dis) # 排序,返回的是索引 count = {} for i in range(0, k): vote = labels[sort_dis[i]] # 显示当前类 count[vote] = count.get(vote, 0) + 1 # 统计各类别次数 sortcount = sorted(count.items(), key=operator.itemgetter(1), reverse=True) # 按照降序排列字典 return sortcount[0][0]
然后,我们利用训练集创建KNN模型:
# 加载数据 def dataToArray(filename): arr = [] f = open(filename) for i in range(0, 32): thisline = f.readline() for j in range(0, 32): arr.append(int(thisline[j])) return arr # 取出文件前缀,获得label def seplabel(filename): filestr = filename.split(".")[0] label = int(filestr.split("_")[0]) return label # 建立训练数据 def traindata(): labels = [] trainfile = listdir("f:/data/traindata/") num = len(trainfile) # 长度1024(列),每一行存储一个文件 # 用一个数组存储所有训练数据,行:文件总数,列:1024 trainarr = zeros((num, 1024)) for i in range(0, num): thisfname = trainfile[i] thislabel = seplabel(thisfname) labels.append(thislabel) trainarr[i, :] = dataToArray("f:/data/traindata/" + thisfname) return trainarr, labels 最后,利用创建的KNN模型对测试集进行测试,同样是测试手写体“8”: #抽某一个测试文件出来进行试验 trainarr,labels=traindata() thistestfile="8_76.txt" testarr=dataToArray("f:/data/testdata/"+thistestfile) rknn=knn(3,testarr,trainarr,labels) print(rknn)
结果为:

说明KNN模型也可以识别出手写体“8”,接下来我们利用所有测试集求出KNN模型的精度:
#用测试数据调用KNN算法去测试,看是否能够准确识别 def datatest(): trainarr,labels=traindata() testlist=listdir("f:/data/testdata") tnum=len(testlist) count = 0 for i in range(0,tnum): thistestfile=testlist[i] this_label = seplabel(thistestfile) testarr=dataToArray("f:/data/testdata/"+thistestfile) rknn=knn(3,testarr,trainarr,labels) if (rknn == this_label): count += 1 acc = count / tnum print(acc)
结果为: